Understanding NetWare Directory Services
Articles and Tips: article
Engineering Documentation Team Lead
NDS Development Team
01 Jan 1995
This DevNote defines basic concepts and operating theory that are necessary to understand NetWare Directory Services (NDS). Concepts covered include hierarchical naming, directory schema, inheritance, authentication, partitioning, replication, name resolution and synchronization.
Introduction
The first half of this article defines basic concepts used in NetWare Directory Services (NDS). I cover the following concepts:
Client/server
Bindery services
Global, distributed, replicated name service
Hierarchal naming
Partitioning
Replication
Name server
Synchronization
Loose consistency
Schema
Object classes
Super classes
Containment
Inheritance
Authentication
Background Authentication
I'll cover these concepts in (what seems to me to be) logical order.
Networking and NetWare Concepts
NetWare 4 changes the manner in which networks have been traditionally used and administered. Instead of providing a server-centric environment, NetWare 4 provides a network-centric environment. This means that the network administrator is applying new concepts and techniques to network administration. NetWare 4 Directory Services provides the tools for administrators and applications to manipulate the new network environment.
NetWare 4 Directory Services is based on the 1988 CCITT X.500 standard on Directory Services. This standard outlines a paradigm in which network objects are held on independent machines. This article will discuss the concepts involved in Directory Services and how they relate to the NDS environment.
Client/Server Model
NetWare, and therefore NDS, is built on the network client/server model. That is, one or more Directory servers are attached to one or more workstations (clients). At the client workstation, a user application invokes a client agent that formulates directory requests on the user's behalf. The client agent establishes a session with a Directory server to which it submits the requests.
Client agents and Directory servers use the NDS protocol when they need to make access requests. Client workstations can also access some Directory information by using bindery services.
Figure 1: This shows the NDS Client/Server architecture.
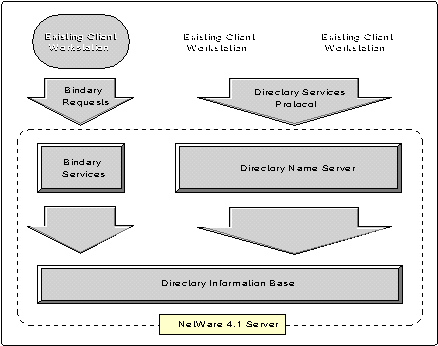
Note: The X.500 Directory Services standard refers to a client agent as a directory user agent (DUA). It also refers to Directory servers as Directory system agents (DSA).
Bindery Services
NetWare versions prior to NetWare 4 used the bindery to store the database information. Currently, NetWare 4 uses the NDS name to store this information. It relies on bindery services to provide backward compatibility to applications that use bindery calls. Bindery services formulate Directory information into a bindery format that the server can use to respond to bindery-style requests.
Note: Bindery services are limited; they allow backward compatibility, but cannot express all of the information stored in the Directory.
Global, Distributed, Replicated Name Service
NDS provides a global, distributed, replicated name service. This name service is global because it is not server-centric. NetWare 4 shifts the networking paradigm from one in which the entire database is stored on one server to one in which the database is split across a network of servers. Thus, the NDS name service encompasses all servers and resources in the network. In other words, NDS allows the database to change while giving users across the network a consistent view of the Directory.
NDS is also described as a distributed database, because, as described above, portions of the database are placed among the Directory servers according to corporate needs, network use, and access time, among other factors. These portions of the data base are called partitions.
These directory partitions are replicated throughout the network tree. Among other uses, these replicas provide fault tolerance and easier access to network resources.
Cooperation among Directory servers allows users to access these partitions as a single resource. This coordination of multiple partitions and replicas is referred to as the distributed operation of the Directory.
One of NDS's main functions is to provide a name service. A name service translates network or resource names to network addresses. This means that any modification to the network address of a resource or object is invisible to the user; the user is still able to access the resource by the resource's name. See Figure 2 for a basic illustration of this concept.
Directory services define the name space (or naming structure) for the entire network. A name space is a set of rules that defines how all network users and resources are named and identified.
Note that the term name space is also used in the NetWare context to refer to the file naming convention for a particular client operating system. NetWare's native file system uses DOS's 8.3 naming convention (eight characters, followed by a period and a three-character extension). If you want your file server to support the long file names supported by the Macintosh operating system, you need to load the Mac name space (MAC.NAM).
Hierarchal Name Space
NDS uses an n-level hierarchal name space instead of the traditional flat name space such as the bindery. A flat name space contains one name for each object, and that name does not include any other information about the object. For example, a printer object could be named HPLJIII. That name identifies a printer as HPLJIII, but it does not identify a specific physical printer, or the physical location of that printer.
A hierarchial object name resembles a complete file name in a hierarchal file system such as DOS. A complete DOS file name contains each directory in the path from the drive root to the file; a complete hierarchal object name contains the name of every container object between itself and the root of the database.
Figure 2: Mapping a network address to a resource name.
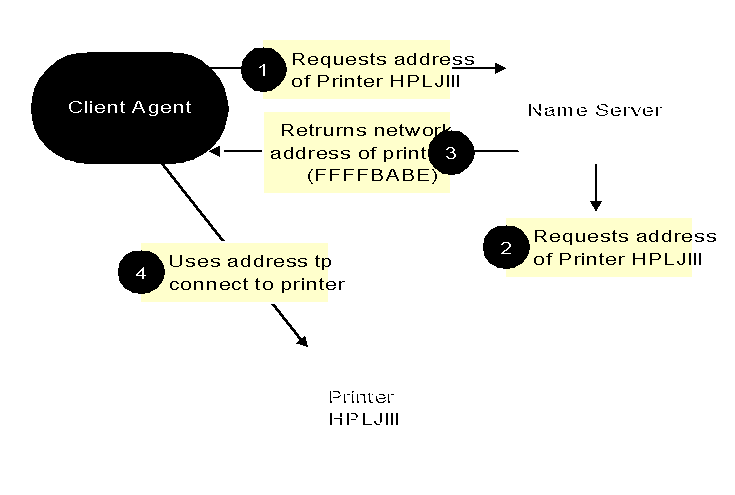
NDS uses the hierarchal name space because an average NetWare 4 customer has about five to seven objects in the directory per user account. These objects provide the basic functions and resources of the network, such as printing, e-mail and user accounts. In a corporation of 5000 employees, the NDS database size would consist of 25,000 to 35,000 objects. This database would also grow as its environment grows and more users and resources are added to the network. A flat naming space in a database of this size becomes very difficult to administer and scale.
An n-level hierarchial name space is usually represented as a tree structure (much like the representation of a hierarchal file system). Figure 3 shows an example of a user object SteveM and its relationship to its container objects in a tree form.
The name of user object SteveM shows its relationship to the database hierarchy and indicates its logical location as follows:
.CN=SteveM.OU=Core OS.OU=NPD.O=Novell.C=US
Unlike the long file names in a hierarchal file system, an NDS object name starts with the most significant part of the name and proceeds to the most general part. Thus, the name of object SteveM, starts with the user's name (the most significant part) and traces its relationships back to the country object (the most general part).
Figure 3: An example of an NDS tree.
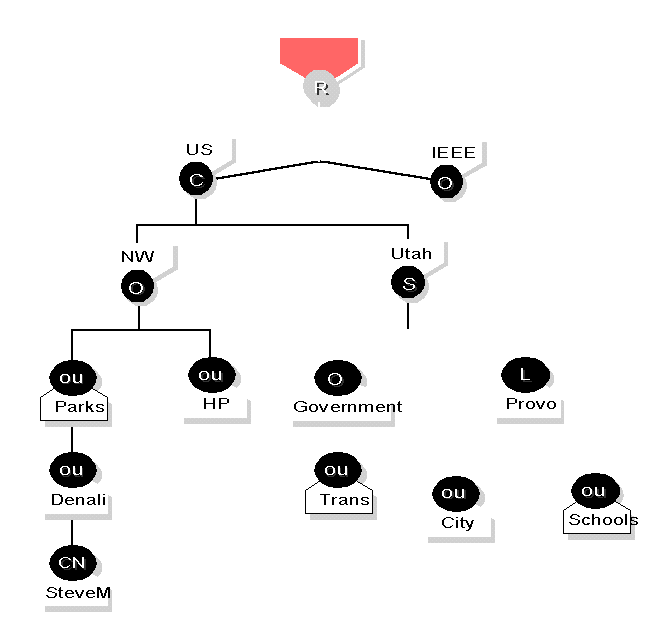
Because a hierarchal name contains the logical relationship of the object to its environment, a hierarchal name structure allows NDS to split the name space into logical groupings of objects. These groupings become the partitions of the NDS tree (see Figure 4).
Distinguished Name
An object's Distinguished Name (DN) is a unique reference that identifies the location and identity of an object in the Directory. For example, the name
.CN=SteveM.OU=Core OS.OU=NPD.O=Novell.C=US
isolates Steve M's user object to only one object in the entire directory because it contains a unique path of container object names.
Figure 4: An example of a partitioned NDS tree.
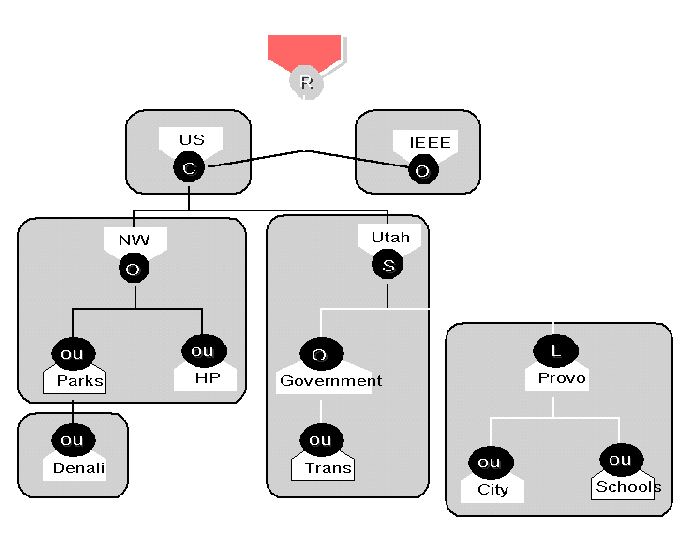
Each object name has a naming attribute, which in the base schema is associated with either a container or a leaf object. For example, the naming attribute for a leaf object is usually CN= (Common Name). Container objects generally have one of the following naming attributes:
C= Country
L= Locality
S= State
O= Organization
OU= Organizational Unit
In the previous example, the Core_OS object has the naming attribute of OU, which in the base schema means that it is an Organizational Unit object.
Note: A distinguished name which contains the type identifiers is also known as a typeful name. Distinguished names can also use just the "." between the object names and drop the object types. These names are called typeless names.
Relative Distinguished Name
The individual name assigned to an object is called the object's relative distinguished name (RDN), or partial name. The partial name must be unique in relation to the object's superior object. In the above example, only one object named Core_OS can be subordinate to NPD, and only one object named SteveM can be subordinate to Core_OS, and so on.
Name Context
NDS requires that an object be specified by its complete name. Because it can be inconvenient to identify an object by its complete name, NDS allows a client to submit a portion of its complete name. This portion must be relative to a predefined name context. The name context is a complete name that serves as a default naming path for the operation. (It is the complete name of a container object; it is not the user's complete name.)
Partitioning
Each partition contains a subtree of the entire Directory tree. When taken together, all the partitions form a hierarchal tree of partitions leading back to a root partition that contains the Directory root (see Figure 5).
Figure 5: A hierarchal tree and its partitions.
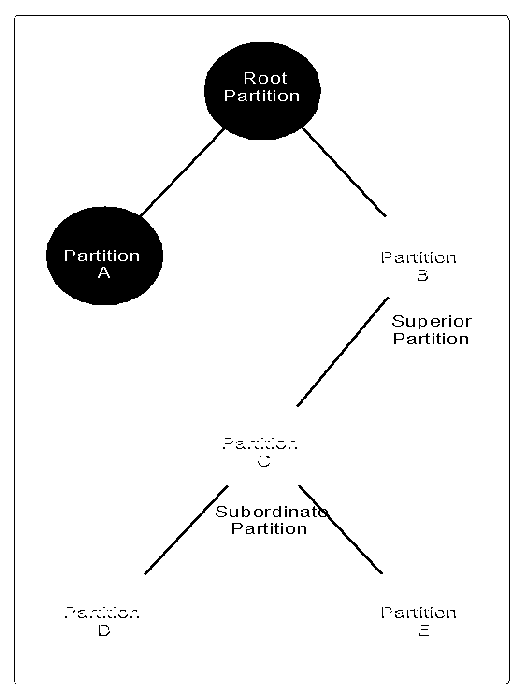
Where the boundaries of two partitions meet, the partition closer to the root is considered the parent, or superior, partition, and the one further from the root is considered the child, or subordinate, partition. This tree of partitions is invisible to the typical directory user who only sees a global tree of Directory objects.
Partitions must obey the following three rules:
They must contain a connected subtree.
They must contain only one container object as the root of the subtree.
They cannot overlap with any other part of the NDS tree.
A partition is named by its root-most container object (the container at the root of the subtree.)
Replication
A single instance of a partition is called a replica. Partitions can have multiple replicas; but only one replica of a particular partition can exist on each server. (Keep in mind that servers can hold more than one replica, as long as each replica is of a different partition.) One of these replicas (usually the first created) must be designated as the master replica. Each partition can have only one master replica; the other replicas are designated as either read-write or read-only replicas. (You can use the read-only replica only to read the information in the partition replica. You cannot write to a read-only partition.)
Replication adds fault tolerance to the database because the database has more than one copy of its information.
Name Server
Physically, a name server is a network node that administers zero or more Directory replicas. A name server provides name services for a Directory tree. Logically, a name server is an object that is defined in the schema and that can reside on a Directory server.
Synchronization
Synchronization is the process of ensuring that all changes to a particular partition are made to every replica of that partition. The X.500 standard defines two synchronization mechanisms: master/ slave synchronization and peer-to-peer synchronization. The master/slave mechanism requires that all changes be made on the master replica. That replica is then responsible to update all the other replicas (slave replicas).
In a peer-to-peer synchronization system, updates can be made to any read-write or master replica. At a predetermined interval, all servers holding copies of the same partition communicate with each other to determine who holds the latest information for each object. The servers update their replicas with the latest information for each replica.
NDS uses both the master/slave and peer-to-peer synchronization processes, depending upon the type of change that is being made. The master/slave mechanism synchronizes operations such as partition operations that require a single point of control. The peer-to-peer mechanism synchronizes all other system changes.
Note: In NetWare, the synchronization time interval ranges from between 10 seconds to 5 minutes depending upon the type of information updated.
Loose Consistency
Because the NDS database must synchronize, not all replicas hold the latest changes. This concept is referred to as loose consistency. Loose consistency simply means that the partition replicas are not instantaneously updated. In other words, as long as the database is being updated, the network Directory is not guaranteed to be completely synchronized at any instance in time. However, during periods in which the database is not updated, it will completely synchronize.
Loose consistency has the advantage of allowing Directory servers to be connected to the network with different types of media. For example, you could connect one portion of your company's network to another by using a satellite link. Data traveling over a satellite link experiences transmission delays, so that any update to the database on one side of the satellite is delayed into reaching the database on the other side of the satellite.
However, because the database is loosely consistent, these transmission delays do not interfere with the normal operation of the network. The new information arrives over the satellite link and is propagated through the network at the next synchronization interval.
Another advantage to loose consistency is that if part of the network is down, the changes will synchronize to available servers. When the problem is resolved, the replicas on the affected servers will receive updates.
Note: The X.500 standard refers to the concept of loose consistency as transient consistency.
Directory Schema
The directory schema defines the rules for adding entries to the Directory. A data dictionary specifies the rules and provides a standard set of data types from which objects can be created. Every object in the Directory belongs to an object class that specifies what attributes can or must be associated with the object.
All attributes are based on a set of standard attribute types which, in turn, are based on standard attribute syntaxes. Object classes, attribute types, and attribute syntaxes are all defined by the Directory schema.
The Directory schema not only sets the rules for the structure of individual objects, but it also sets the relationships among objects in the Directory tree. To do so, the Schema specifies subordination among object classes. Every object has a limited group of object classes from which subordinate objects can be formed.
By limiting the potential pairs of superior and subordinate object classes, the schema provides a stable, yet flexible, structure for developing the Directory tree. The base schema is the schema created when the server is installed. However, this schema is extensible which means that new information types can be added to the existing ones. Applications cannot subtract from the definitions provided by the base schema.
Object Classes
Object classes are used as the principle templates for storing information in the Directory. All Directory objects must belong to an object class. A class is defined by the types of attributes that characterize an object. These attributes types contain the following types of information:
Super classes
Containment
Mandatory attributes
Optional attributes
Effective status
Default Access Control Lists (ACLs)
Super Classes
Each new object class must have a Super Classes list. The super classes contain the schema inheritance rules. To determine the complete set of rules for a given object class, you must look at that class's super classes. An object class inherits all the features of its super classes.
This is how hierarchies of classes develop through class inheritance. The classes at the top of a hierarchy provide general characteristics, while those at the bottom become more and more specialized. The complete set of rules for an object class is called the expanded class definition.
The class from which an object is created is called the object's base class. The information associated with an object includes the base class and the sum of information specified by all its super classes. When the directory is searched, an object is considered a member of all its super classes. For example, the base class for the User object is Organizational Person. The user object also inherits information from the Person and Top classes.
Containment
Directory Services employs a concept called containment that is very similar to the concept of subdirectories in a hierarchal file system. Some objects, such as Organizational Units, can contain other objects, such as User or resource-type objects. These objects are called container objects. The Directory tree is formed by container objects that hold other container and leaf objects in a specific organization. Often this organization reflects the corporate structure.
The containment classes and naming attributes for an object class constitute the classes' structure rules. In other words, the containment classes determine where the object can appear in the Directory tree.
Objects that cannot contain other objects are called leaf objects. Leaf objects are the network resources such as User and Printer objects.
Inheritance
A superior (or containing) object class passes its attributes to a subordinate object class. This attribute passing is called inheritance.
Objects can inherit attributes from their containing objects and super classes and they can inherit the rights that belong to those objects and classes.
Authentication
Authentication provides verification that any requests the server receive's are from valid clients. Authentication has two phases:
Login: Obtains the private key.
Authentication: Uses the signature to generatea proof that is used to authenticate (establish identity).
Authentication is invisible to the user. During login, the user enters a password, and the remainder of the operation is performed in the "background" by the authentication functions.
Authentication is invisible to the user. During login, the user enters a password, and the remainder of the operation is performed in the "background" by the authentication functions.
Authentication is session-oriented. The data that provides the basis of authentication is valid only for the duration of the current login session. The critical data used to create authenticated messages for a particular user is never transmitted across the network.
Authentication relies on encryption systems, that is procedures that allow information to be transmitted in unreadable forms. NetWare 4 uses a private/public key form of encryption. Basically public/private key encryption means that the agent to receive messages generates a key pair. The receiving agent then distributes the public key and keeps the private key. Those that want to send encrypted messages use that public key to encrypt the message, the receiver then uses the private key to decipher the message.
Only the holder of the private key can decipher these messages. Conversely, a sender can encrypt data with the private key. The recipients of this message would then use the public key to decrypt the message. If the decryption is successful, the recipient can be sure that the message was encrypted with the corresponding private key. Only the holder of the private key could have generated the message. In this case, many agents can decrypt the message and be assured that the message is authentic.
Background Authentication
Background authentication refers to authentication to additional services subsequent to the initial login operation. The user indicates the party to which it needs authentication, and the authentication functions do the rest. The user does not have to retype a password.
Default Access Control List Templates
An Access Control List (ACL) is an optional property on each object that determines which operations a trustee can do on that object. Most object classes have a default ACL template assigned to them if no ACL is specified when the object is created. This default template provides a minimum of functionality and access control for the new object.
Theory of Operations
The remainder of this article discusses NDS's basic operating theory. It provides an overview of partitioning, replication, name resolution and synchronization.
How NDS Works
NDS is an object-oriented, global information database. An NDS database is equipped to handle up to 16 million objects per server. (This number is based on the addressing available in the hash table.) As this number indicates, the large databases typically managed by NDS can be very difficult to administer on a per-server basis.
To resolve that difficulty, NDS uses a hierarchal name space, rather than a flat name space. This hierarchal organization of objects allows the database to be mapped as a tree, which in turn, allows the database to be partitioned by its subtrees. And because the object names contain the hierarchy information, users can globally access the network resources. The network administrator can also administer the entire tree and its objects from a single point.
NDS Objects and Attributes
NDS consists of objects and attributes based on an extensible schema. This schema contains the rules for forming these objects and their hierarchy.
Container and Leaf Objects
The NDS schema defines two types of objects:
Container objects
Leaf Objects
Container Objects. Containers are simply objects that can contain other objects. The Country, Locality, State, Organization, and Organizational Unit objects are container objects.
Leaf Objects. Leaf objects are objects that cannot contain any other objects. These objects are usually the network resources. Users, printers and NCP servers are examples of leaf objects.
Object Attributes
Objects are defined by their mandatory and optional attributes. Mandatory attributes are attributes defined by the schema that the object must have in order for that object to exist. If the object is missing a value for a mandatory attribute,the object becomes unknown. Optional attributes are attributes that the object may or may not have values for.
Attributes can be single- or multi-valued. A single-valued attributed can have only one value. For example, an object's login script is a single-valued attributed as each object can have only one login script. A multi-valued attribute can have more than one value. For example, an object's phone number is a multi-valued attribute as each object can have more than one phone number.
Object Names
Every object must have a unique name. This name and its location in the hierarchy form the object's name context. NDS allows two general types of names:
Typed Names
Typeless Names
Typed Names. Typed names contain the object's location in the hierarchy, as well as the type of each object in the name. For example, .CN=AResource.OU=NPD.O=Novell is a typed name. It defines the name AResource as the Common Name of the object; NPD as an Organizational Unit object; and Novell as an Organization Object.
Typeless Names. Typeless names contain the object's location in the hierarchy, but does not contain the type of each object. For example, .AResource.NPD.Novell is a typeless name.
Full and Partial Names. Both typed and typeless names can be either full or partial. A name which starts with a period, such as .AResource.NPD.Novell, is a full name. A partial name contains only a portion of the hierarchy. The system appends the object's default context to its partial name.
General Object and Attribute Structures
The block diagram in Figure 6 illustrates a generic object structure. This structure contains 5 fields:
Figure 6: This shows the generic object structure.
|
Object Class |
Object Name |
Creation Name |
Modification Time |
Entry ID |
The block diagram in Figure 7 illustrates a generic attribute structure. This structure contains 3 fields.
Figure 7: This shows the generic attribute structure.
|
Attribute Type |
Value |
CreationType |
NDS Partitions and Replicas
Because the NDS database is hierarchal and object-oriented, it lends itself well to distribution, or partitioning. And because the database is partitioned, it can be efficiently replicated.
The NDS database can be mapped as a tree structure with container objects forming subtrees. Each subtree can be either partitioned separately, or partitioned with parallel (sibling) container objects as long as they are all held in a common superior container.
Partitions obey the following rules:
They must contain a connected subtree.
They must contain only one container object asthe root of the subtree.
They cannot overlap with any other part of the NDS tree.
A partition is named by the root-most container object (the container at the root of the subtree).
Figure 8 illustrates an example partitioned tree.
Figure 8: An example of a partitioned tree.
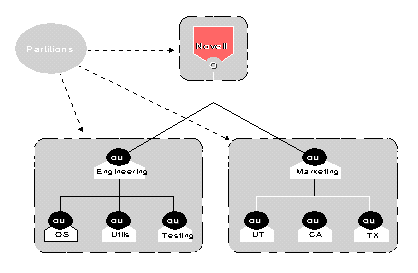
The tree in Figure 8 has three partitions: Root, Engineering and Marketing. Figure 9 shows an improperly partitioned tree in which Engineering and Marketing are combined as a subtree.
Figure 9: An example of an improperly partitioned tree.
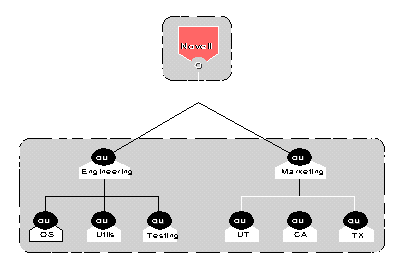
As you can see in Figure 9, NDS has no way of accessing either Engineering or Marketing because the partition has combined subtrees. In other words, the partition cannot be named because it does not have a single, unique, root-most container.
However, as illustrated by Figure 10, if you join Engineering and Marketing into a single subtree (held in one container), you can then place them into a single partition.
Figure 10: An example of a partitioned tree with combined partitions.
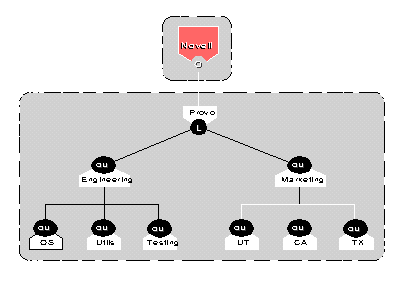
As Figure 10 shows, the partition is now named Provo, and the system has a way of locating it.
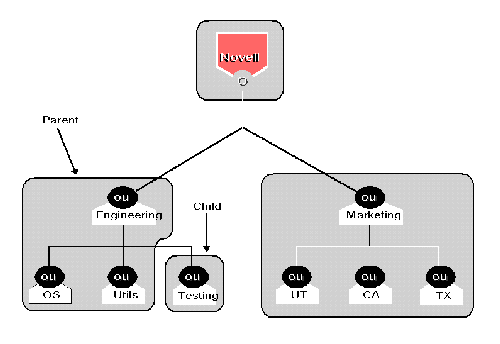
Parent and Child Partitions. When a container object is put into a partition independent of that object's container, the partitions are known as parent and child partitions. The parent partition holds the superior container and the child partition holds the subordinate container. This is illustrated in Figure 11.
Figure 11: An example of parent and child partitions.
Replicas
A single instance of a partition is called a replica. Partitions can have multiple replicas; but only one replica of a particular partition can exist on each server. (Keep in mind that servers can hold more than one replica, as long as each replica is of a different partition.)
Replicas must be designated as one of four types:
Master.
Read/write.
Read Only.
Subordinate Reference
One (and only one) replica of a partition must be designated as the master replica; the other replicas must be designated as either a read-write or read-only replica, or a subordinate reference. The replicas are invisible to the user; that is the user does not know which replica contains the objects being accessed.
Master, Read/Write, and Read-Only Replicas. Clients can create, modify and delete objects on either master or read/write replicas. However, clients can perform operation that deal with partitions only on the master replica. Clients cannot make any changes to read-only replicas.
An object must access either a master or a read/write replica in order to log in.
Figure 12 shows three partitions (A, B, and C) replicated across three name servers (NS1, NS2, and NS3). NS1 stores the master replicas of partitions A and B and a read-only replica of partition C. NS2 stores the master replica of partition C and secondary replicas of A and B. NS3 stores secondary replicas of A and C.
Given this arrangement, any of the servers could handle a request to add an object to partition A. Only NS1 and NS2 could handle a similar request for partition B, and only NS2 and NS3 could handle such a request for partition.
Figure 12: This shows partition replication.
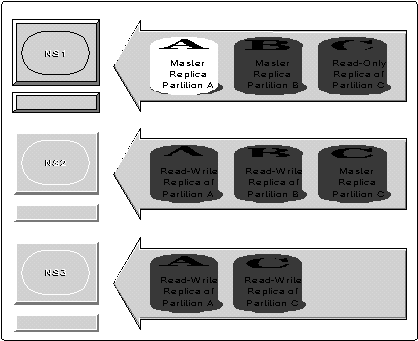
Only NS1 can create a new partition subordinate to partition A or B, and only NS2 can create a new partition subordinate to partition C.
Subordinate References. Subordinate references provide tree connectivity. As a general rule, subordinate references are placed on servers that contain a replica of a parent partition, but not the relevant child partitions. In this case, the server contains a subordinate reference for each missing child partition. A subordinate reference is essentially a list of all the servers on which the child replica can be found.
Figure 13 illustrates a partitioned tree and its subsequent replica placement on the servers which are holding the tree.
Figure 13: An example of replica placement.
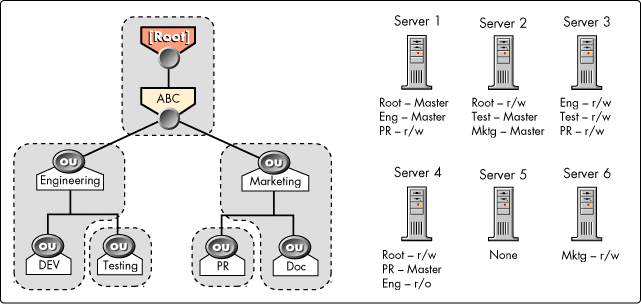
Some of the servers in Figure 13 are holding replicas of parent partitions, but not replicas of the corresponding child (see Srv1, Srv2, and Srv4.) These servers must also hold subordinate references, as shown in Figure 14.
Figure 14: An example of replica placement with subordinate references.
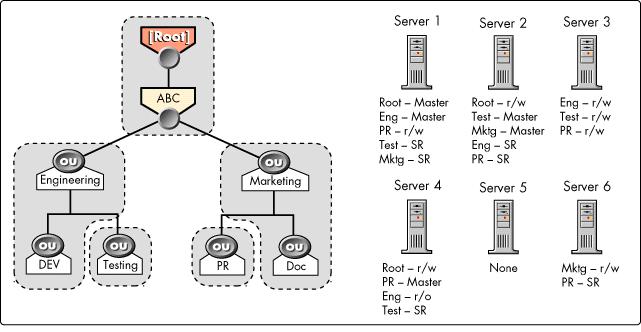
Replica Lists. Each replica contains a list of replicas that support the partition it represents. The replica list is stored in each replica as an attribute of the root-most container object in the partition. This list provides enough information for navigation of the NDS tree.
The replica list contains the following elements for each replica:
Server Name: The name of the server where the replica is located.
Replica Type: Thetype of the replica stored on the server designed in the ServerName field. (The type is either Master, R/W, RO, or SR.)
Replica State: Thestatus of the replica. (Includes On, New, Replica dying, Partition dying, and Replica dead, and others.)
Replica Number: The number that the master assigned to this replica at the time the replica was created.
Network Address: The server's last known address.
Remote ID: The entry ID of the replica's partition root object.
Name Resolution. To resolve an object's name, NDS maps the name to the network address of the server where the object is stored. NDS must resolve names in the following instances:
Login
Authentication
Resource location
Figure 15: A sample NDS tree.
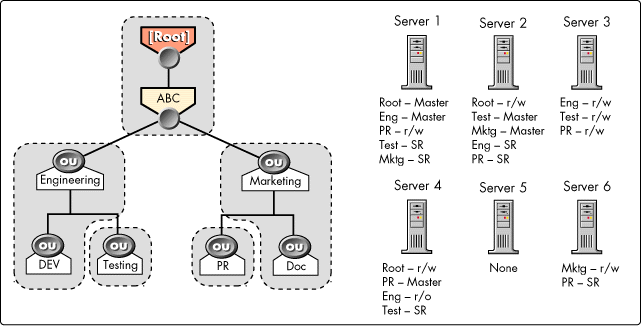
For example, in the tree illustrated in Figure 15, a client must access a resource in the Test partition. For this example, Srv1, Srv2, and Srv4 are not available. In this case, Srv3 locally contains all the information for the Test partition, so it sends the requested information back to the client. However, when the other servers are available, and the same request is made, the client agent checks the replica list for the partition and sends the replica list to the client. The client then determines which server is the least expensive to access and requests the information from that server.
If the client requests information from Srv5 (which has no replicas), the server sends a SAP requesting information regarding the required resource. If the client requests information from Srv6, the client agent looks at the replica list and asks all the servers in the list for information regarding a more superior container in the tree.
Replica Synchronization. The NDS database is loosely consistent, which means that at any given instant any particular replica is not guaranteed to hold the latest changes to the database. However, to ensure the integrity of the database, NDS automatically synchronizes all the replicas, and the database is guaranteed to completely synchronize over any period of time during which no changes occur. This synchronization process runs in the background.
The NDS synchronization process is divided into two types:
Fast synchronization
Slow synchronization
Fast synchronization occurs at 10 second intervals. All object modification events are scheduled for fast synchronization.
Slow synchronization occurs at 5 minute intervals. Only the attributes that deal with the login time and the network address are scheduled for slow synchronization.
Although the X.500 standard suggests that all the information for every object is exchanged during synchronization, NDS exchanges only the delta (or updated) information. Each attribute has a time stamp associated with it. NDS updates this time stamp whenever an object's attribute is updated. A replica uses this time stamp and the time stamp associated with each replica in the replica list to determine whether the object must be included in the current synchronization process.
NDS References
NDS relies on two types of references to help manage the database and provide tree connectivity. These references are:
External References
Back Links
External References. When a server does not contain a full path from a replica back to the root of its NDS tree, NDS creates a placeholder for each nonlocal object that NDS tracks. These placeholders are called external references. NDS tracks these nonlocal objects so that it can keep track of renamed objects, moved objects and deleted objects. External references also provide full name resolution, complete tree hierarchy and allow partial name matching. They have the following purposes:
Refer to objects not physically located on the local server (external objects).
Provide the server with an ID for the operating system.
Provide tree connectivity.
Allows attributes of external objects to be cached in order to improve performance.
An external reference is not a pointer; it is a reference to a real object.
An external reference can refer to an object that is not physically located on the local server. For example, referring to Figure 15, if a user located in the Testing group on Srv3 must access a resource in the Documentation group, Srv3 would hold an external reference to Doc.Mktg. In this case, external references reduce the database size and allow a single point from which to rename, move and delete objects.
The following actions create external references for nonlocal objects:
A nonlocal object authenticates to attaches to the server.
A nonlocal object is added as a file system or local object trustee.
A nonlocal object is added as a member of a group object.
Providing the Server with an ID for the Operating System. The operating system requires that NDS provides it with a 32-bit ID. The file system, connection tables and other operating system services then use this ID to locate the appropriate NDS object. The operating system catalogues this ID on a server-by-server basis because a global NDS ID presents scalability problems.
Providing Tree Connectivity
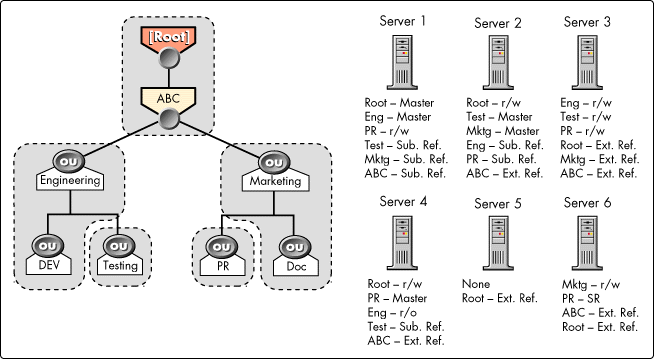
An external reference can also be thought of as supplying the missing link(s) between existing replicas on the server and the root. For example, in Figure 16, Srv5 does not physically hold a replica of Root. However, because Srv5 is part of the ABCTree, it must know be able to locate Root. Therefore, Srv5 would have an external reference to Root. Srv6 also does not have a replica of Root, and it must also be able to link to the tree root. However, in this case Serv6 holds a replica of Mktg which is a subordinate of the ABC container. Therefore, Srv6 must hold an external reference to ABC and to Root.
Figure 16 shows the external references required to connect the ABCTree.
Figure 16: A sample NDS tree showing external references.
Caching Attributes of External Objects
External references allow frequently accessed attribute information to be cached by the server. This means that the server can locate this information in its own memory, instead of repeatedly having to search the tree. Currently, the only cached information is an object's public key.
This cached information improves authentication performance. Cached external references are also referred to as transient external references. If an external reference is not accessed within a period of time (set by the network administrator), the server deletes the cached information. The public key is cached only during the current session. After the current session, the server deletes its public key.
Backlinks
When NDS creates a new external reference, it also attempts to create a pointer to the server holding the external reference as one of the attributes of the nonlocal object. This pointer is called a backlink. If NDS is unable to create the backlink, it continues trying to create the link 9 times. The default retry interval is currently three minutes. If NDS cannot create the backlink after 9 times, the backlink process creates the backlink.
The backlink process executes on a time interval set by the network administrator. Currently, the default interval is 13 hours. The backlink process has two basic functions:
Remove any expired and non-required external references from the system.
Create and service any backlinks not created at the same time as the external reference.
* Originally published in Novell AppNotes
Disclaimer
The origin of this information may be internal or external to Novell. While Novell makes all reasonable efforts to verify this information, Novell does not make explicit or implied claims to its validity.