High There
Articles and Tips:
01 Feb 2006
In today's enterprise, downtime costs money, and a simple outage can result in hours of work and business lost. Fortunately for SUSE Linux users, Novell SUSE Linux Enterprise Server 9 contains Linux High Availability (HA) services.
HA services are provided by a specialized set of applications that run on a SUSE Linux Enterprise Server 9 server. These programs communicate with a redundant server (we'll call it a node) on the network, and initiate failover processes when the node becomes unavailable. HA services enables you to quickly and easily configure systems to provide automatic service redundancy in the case of a hardware failure.
The heartbeat package provides HA services, and is relatively easy to configure and manage. In this article we'll discuss some of the advantages of HA services, and how to configure and test them. In particular, we'll set up a redundant node to take over serving Web pages when the main node fails.
Configuring the Hardware
The basic premise behind using Linux HA services is that two nodes monitor each other and when the active node becomes unavailable, the passive one takes over. This monitoring is typically done using redundant connections, so even if the primary network goes down, the services don't start failing over.
In our example, we'll set up HA monitoring to use a NIC card (we'll use a crossover Ethernet cable to connect the two systems), and a null-modem cable connecting the serial ports of the two servers. (We can use the /dev/ttyS0 device to communicate between the two systems.) By providing two means of communications, we'll ensure that a single cable failure won't disrupt intranode communication and cause services to fail over.
When configuring network interfaces, if at all possible, segregate your working network from the network you use for intranode communication. This helps to ensure that network issues, such as a problem with a switch or unusually heavy network load, won't trigger a service fail over. You minimize the points of failure by placing the two nodes on a separate, dedicated network. The best solution is to use a crossover Ethernet cable and a couple of NICs. Configure your network addresses as appropriate for a point to point network.
Prepare the Services
HA-supported Services are started as part of the HA initialization process--not the normal system initialization. To ensure they aren't started twice, and more importantly, that they don't start unless they are needed, remove the services from the normal system startup. The insserv-d apache2 command removes Apache (Web server) from the normal system initialization. Instead, Apache will be started by the HA services that we configure next.
Installing the Heartbeat Packages
HA services are provided by three heartbeat packages:
heartbeat
heartbeat-stonith
heartbeat-pils
These packages provide the base HA functionality. If you want to set up HA using YaST, use the yast2-heartbeat package because it has the YaST module you need to configure HA.
Configuring High Availability
You can configure HA services using the SUSE Linux Enterprise Server 9 YaST GUI, which creates & modifies the configuration files in the /etc/ha.d directory. After you install the required packages, start YaST, and select the High Availability module from the System section. Or you can use the yast2 heartbeat command to start the module directly.
Typically, you configure HA services to start when the system boots; this allows the system to recover automatically when a problem occurs and, optionally, reassert control over the redundant service. If HA services aren't started, messaging between the two nodes won't occur and the services we've configured won't start.
From the Start-up Configuration screen, select On under Booting. (See Figure 1.) Normally, you can start the HA services from this screen, but in this case we haven't yet configured the HA services. Select Next to configure HA services. After you've finished configuring the service, you can use the rcheartbeat start command (on both servers) to initiate HA services.
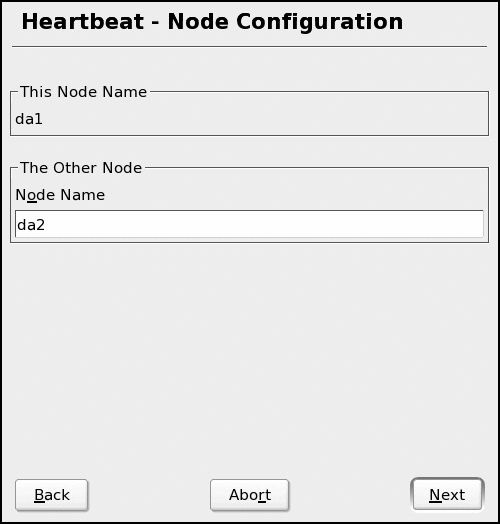
HA services work between two nodes, so you need to specify the other node for this HA cluster. Later, when we configure redundant services, make sure that the node names match the output of uname - n exactly; HA services won't start unless the host name matches the configuration file exactly. (See Figure 2.)
Figure 1: Select "On" but do not start the server yet because you must configure it first.
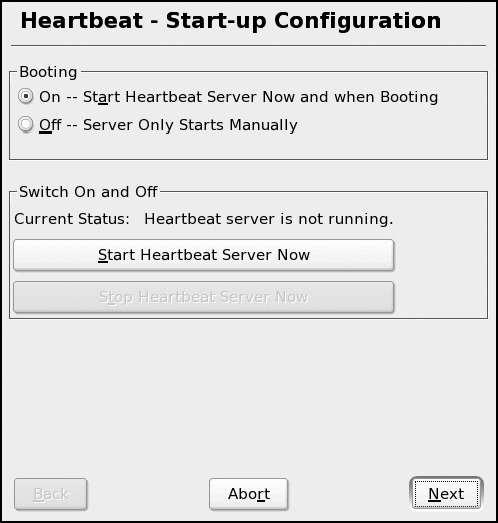
Figure 2: Ensure that node names match the output of the "uname -n" command.
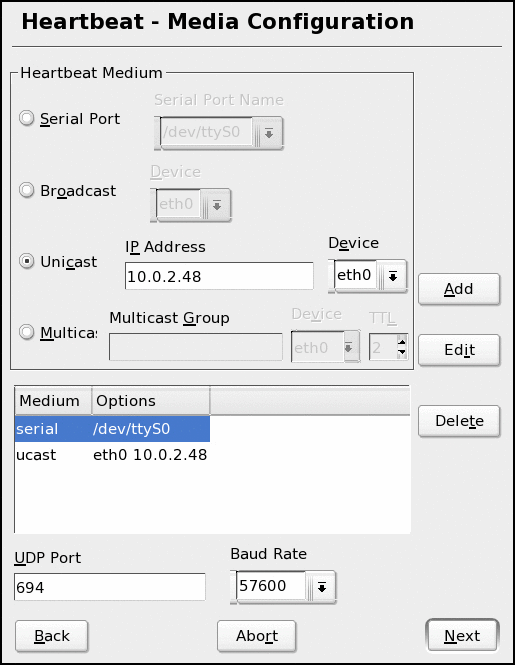
Once you've defined the hosts that will be used for the HA cluster, specify how they will communicate (the heartbeat). If you recall, we're using two methods: the /dev/ttyS0 (serial port with a null modem cable) and the network. While it's possible to add more methods (and later we'll see how we can add more checks to ensure systems are available), two are generally sufficient for most configurations. Select the media you'll use for communication and click Add. Keep adding media settings until you've added all of the settings you need. (See Figure 3.)
Figure 3: Set the media configuration based on your hardware configuration.
To ensure that heartbeat messages are co-opted or forged, you can use an authentication key. Without a key, messages will be sent with a simple checksum to ensure they arrive intact, but without any special identification information.
In this case, where our communication medium is a secure network, a simple checksum is sufficient and less resource intensive; however, when HA communication occurs over an insecure network, it is important to use a secret key (symmetric key). This key is the same on both nodes in the HA cluster and ensures that only valid HA messaging is recognized.
The most secure, and most resource-intensive, mechanism to use is the SHA1 algorithm. Information you enter using that algorithm is stored in the /etc/ha.d/authkeys file. (You can always copy this file over an SSH connection to the standby system.)
Configuring Resources
The most common HA applications involve configuring a failover IP address and a failover service. In the case of a failover IP address, when one system becomes unavailable, its partner system assumes its IP address. The HA system will automatically send out a gratuitous ARP packet, informing routers and switches that the IP address has a new owner. For multiple services, you can use multiple IP addresses; HA will activate the IP address automatically when the service fails over.
When adding resources, associate each resource with a primary node--the node on which the service should normally be started. The HA system will initially start the services on the primary node. If the primary node for a service is down, the partner node will start the service.
For this system to work properly, both systems should agree on the services and who needs to provide them. As a result, the resources should be identical on both nodes in the cluster. Resource information is stored in the /etc/ha.d/haresources file. This file must be identical on both nodes in the cluster and can be copied from one node to the other after you configure the first one.
Resources listed as services are named after their system initialization files, as found in the /etc/init.d directory. The HA system will start and stop these services using the start and stop arguments just as when the system first boots. In our example, the apache2 service will normally run on node da1 and needs to be failed over to node da2 if da1 is unavailable, or in other words, is not sending out heartbeat packets.
When listing IP addresses for failover, use the IP address as the name of the resource. The HA system will recognize the dotted decimal notation automatically, and assume control of the IP address when a failover occurs. In this case, the 10.0.2.192 IP address needs to be failed over, so incoming HTTP requests can be redirected to the appropriate system when a failure occurs.
If either system has multiple network interfaces, the HA system will refer to the routing table and assign the IP address to an interface based on the lowest-cost route; typically, this is the default route. Remember, this requires no special network configuration, as long as the IP address listed is on the same subnet as a NIC card in the system.
When a system becomes unavailable, the resources start in the order they are listed. This ensures that dependencies are met, if needed, when services are started. In our example, we need to assign the new IP address prior to starting Apache. Otherwise, Apache might not bind to the proper IP address.
The inverse of this is also true: when you manually switch a service over to another node the services will be stopped and the IP addresses will be released in reverse order. When adding/listing services for failover, ensure that the services are started and stopped in the proper order. (See Figure 4.)
Figure 4: Services must be listed on their primary node in the order they should be started.
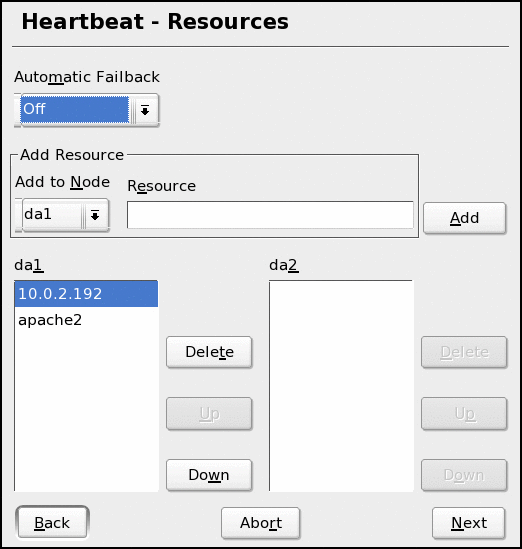
You might notice in our example, we placed the ownership of all services on da1. You can also assign some services to be owned by da2. This would allow you to use both da1 and da2 for normal network services, with each taking on the additional load of the other in the case of a failure. This type of scenario allows you to better use your hardware, since neither server will ever sit idle while still providing fault tolerance.
When configuring resources, you must tell the HA system how to recover from failures. When a node becomes unavailable, its mate will start the necessary processes to ensure those services remain available; however, when a node, which was previously down, becomes available, the HA system must determine how to recover.
Use the Automatic Failback option to configure this. With Automatic Failback turned off, services won't automatically switch back when a node returns to operation. Instead, the nodes remain in the post-failure state until someone resets them (by using the hb_standby command), or another failure occurs. If the setting is On, the primary node for a service will assume control of it when that system comes back online.
In most situations, the Off setting is preferable, because it minimizes service disruption, or the "hiccup" that occurs when services switch over. The Off setting also prevents services from switching back and forth when a system has a recurring problem. The Legacy setting is for backwards compatibility with older versions of the HA system and you typically don't use it.
Configuring a STONITH Device
When services fail over, the failover system must be certain that its peer is really down. To ensure this, HA can communicate with a Shoot-The-Other-Node-In-The-Head (STONITH) device.
A STONITH device ensures that a node is down, usually by cutting the power to the device using a software actuated switch. The HA system supports a wide range of STONITH devices, many of which it controls using the SNMP protocol. (See Figure 5.)
Figure 5: Configure a STONITH device to ensure that the two nodes never provide a service simultaneously.
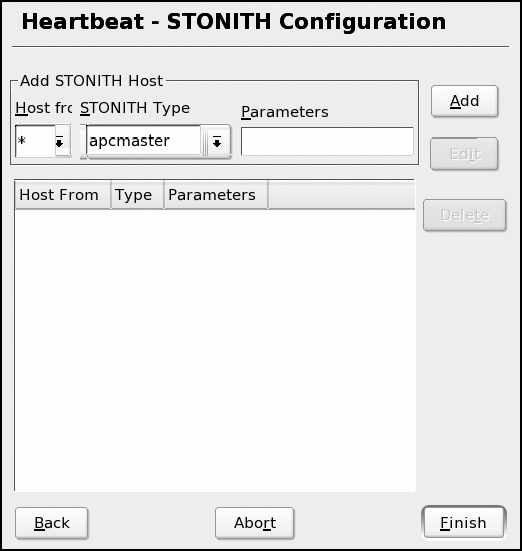
Remember, a STONITH device doesn't perform a graceful shutdown of a node, which could result in more data being written or additional delays in a failover. Rather, it interrupts all processes and immediately shuts down the server.
If you use shared devices, such as a shared disk, make sure the active node is down before the passive node goes active; data corruption might occur if both systems try to read and write the same data. Several devices exist that provide STONITH operations for HA systems. They are typically multiple-outlet power switches managed via SNMP over the network.
Starting & Verifying HA Services
HA Services are started using the rcheartbeat start script and stopped using the rcheartbeat stop script. Typically, you start these services on the primary node for services first, and then the failover node. If they start on the failover node and the server doesn't get any heartbeats, the failover node will start the services.
Once started, you can find information about the status of HA services in the /var/log/ha-log log file; don't forget to add a configuration file for this log to logrotate! You can include HA services in the system boot sequence using the insserv heartbeat command; you typically do this when you configure the HA system.
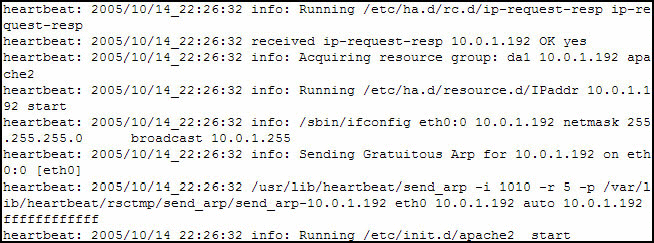
Once HA services are started, the two nodes will communicate over the channel(s) you configured. Each node will determine the status of the other, and will start services based on the node status. Examining the log file on the primary node reveals that the primary node activated the IP address that we had allocated for the HA service, and then started the apache2 service. (See Figure 6.) The secondary node's log file shows the node was placed in standby. In this case, it will continue to monitor messaging and heartbeats from the primary node to ensure the node is available.
Figure 6: The ha-log file shows the activation of the IP address and startup of redundant services.
Testing the Failover Services
To verify proper operation of the service, you can perform a range of tests: To perform a manual failover, use the /usr/lib/heartbeat/hb_standby command. This command lets the HA system know that the current node, or the one on which the command is executed, is going into standby mode. As a result, the other node in the cluster will assume control of the resources that were configured.
In this case, let's configure Apache on the two nodes with two different Web pages. When a failover occurs, you can press Reload in your browser to retrieve a new Web page from the other node in the cluster.
To switch back, log on to the current active node and issue the hb_standby command again. You can also issue the hb_takeover command from the non-active node causing it to signal the active node and then take control of HA resources.
If you've configured multiple resources, you can use the /usr/lib/heartbeat/req_resource command to request that a node take control of that resource. For example, perhaps "named" is a primary resource for da1 and apache2 is a primary resource for da2, you can use the following command to take control of the apache2 resource again: /usr/lib/heartbeat/req_resource apache2. That command migrates the specified resource, along with all other resources on the same configuration line of that resource, over to the node where the req_resource command was executed. This allows you to configure a pair of HA nodes so they can provide redundancy for services running on each other. This lets you use hardware that might normally only be used as a hot standby device.
The final test is to unplug your serial cable and crossover Ethernet cable and ensure that services switch over and the STONITH device powers down the failed node.
Advanced HA Features
The HA features of Linux go far beyond the simple failover scenarios discussed herein. You can configure Heartbeat to perform a wide range of other operations that ensure your users always have reliable network services.
Fine Tuning Your Heartbeat
Depending on your needs for service availability, you can fine tune HA services by modifying the /etc/ha.d/ha.cf file. Using different configuration parameters, you can better control the frequency of heartbeat messages, the delay before a failover occurs and other related settings. You can find more information on this configuration file
HA can use the ipfail module to monitor external IP connectivity. As long as the node can communicate with systems that exist on an external network, that node will remain active. If ipfail detects that connectivity is lost, it will cause a HA failover. This type of watchdog allows the HA system to detect more than simply an unavailable system. Using such a solution increases the importance of having automatic failback disabled, since network outages can sometimes be temporary. You can also configure the ipfail module through the YaST heartbeat module.
With the heartbeat-ldirectord package installed, HA can also monitor the proper operation of network services. While standard HA solutions watch for heartbeat messages, or network connectivity, to fail over, the heartbeat-ldirectord package contains scripts that can monitor additional ports and services, for example, httpd, https and ftp. If a monitored service becomes unavailable, or returns data that was not expected, HA services can be triggered to perform a failover. Such solutions allow you to cause automatic failover of services in several scenarios ranging from Web server errors to hacked Web pages.
Small Expense, Big Returns
You can couple HA with Distributed Replicated Block Devices (DRBD), which allow file system mirroring over a network, and allows redundant file systems as well as services. Coupled with MySQL or PostgreSQL clustering solutions, HA can provide clustered MySQL and PostgreSQL databases with High Availability.
These solutions allow Linux systems to provide database, file and other services with a high degree of availability at a fairly low cost. So let your imagination wander. Using SUSE Linux Enterprise Server 9 and its Linux High Availability services, you can put a HA solution into place without much expense that will pay off big when you have that eventual system failure.
* Originally published in Novell Connection Magazine
Disclaimer
The origin of this information may be internal or external to Novell. While Novell makes all reasonable efforts to verify this information, Novell does not make explicit or implied claims to its validity.