Features of the Novell Kernel Services Programming Environment for NLMs: Part Two
Articles and Tips: article
Senior Software Engineer
Server-Library Development
01 Oct 1999
Part two in a series on the features and functionality of the Novell Kernel Services (NKS) programming environment. Focuses on multi-threaded programming, latency, and thread cancellation issues.
- Introduction
- Thread-Programming Definitions
- Overview of Threads and Context
- Joinable Threads and Thread Termination
- Swapping Contexts between Threads
- Thread-specific Data and Key-value Pairs
- Migrating NKS Threads between NLMs
- Synchronization
- Conclusion
Introduction
This is part two in a series on the programming features and functionality of the Novell Kernel Services (NKS) programming environment from the perspective of my organization, which is tasked with ensuring that developers have tools and technologies at their disposal for writing applications that run as NetWare Loadable Modules (NLMs) on NetWare.
Part one explored the reasons for this recently defined programming environment and examined in some detail the various interfaces surfaced by NKS.NLM.
Part two, this article, focuses more closely on the programming concepts in the Novell Kernel Services environment including discussions of multi-threaded programming correctness, latency, and thread cancellation issues.
Part three of the series will finish the concepts started in part two by covering the remaining programming interfaces for writing NLMs.
Part four will discuss how LIBC sits atop NKS and make comments about programming at both levels. In addition, it will make pertinent remarks about differences in programming to LIBC as compared to CLIB.
In "The Future of Application Development on NetWare with NLMs" (Novell Developer Notes, Sept. 1999, p. 27) I explained how the ten-year old CLIB programming environment had reached an unfortunate milestone in its attempt to continue to support existing NLMs coded to it and at the same time had moved forward to embrace support for future multi-threaded programming technologies. I also explained the reasons why we plan to freeze CLIB in its current state (plus bug fixes) and move ahead with a new environment based on Novell Kernel Services (NKS) plus a standard C library environment (LIBC) loosely referred to as NKS/LIBC. Part one of this series covered at the 64,000-foot level the services offered by NKS. Now, we'll expose the concepts behind NKS thread programming by discussing thread programming to NKS and using synchronization variables in some depth.
Thread-Programming Definitions
In any in-depth discussion such as this one, it is useful to establish some definitions at the beginning. Since this threads discussion is pointed toward NetWare programming and will involve comparison between new NKS concepts and older tradition in programming to NetWare, we want to establish our definitions on that basis and, where useful, note in passing how the concept relates to the article.
|
process |
"An instance of a running program." Process is in use in many environments, not just NetWare. In NetWare, historically, a process and a thread have been the same thing, even as concepts of lighter-weight worker threads have arisen. In the end, scheduling differentiates threads rather than actual weight in data structure representation. The term process has mostly fallen by the wayside. |
|
thread |
"A stream of control that executes instructions independently." In a multi-threaded system, the thread and not the process is the basic unit of execution. |
|
context |
"Data associated with a thread." This includes its stack, registers, any private data area, and all other aspects of the thread that fully describe its state to the kernel. Moreover, the user state of a thread is also part of its context. |
|
kernel mode |
"Privileged execution mode." Most code written to NetWare executes in kernel mode in the form of NLMs, sort of kernel extensions. This is partly the source of NetWare's striking performance, but also of its programming difficulties. |
|
user mode |
"Non-privileged execution mode." NLMs run in this mode when loaded in a protected or ring 3 address space. The operating kernel is insulated from anything that code running in user mode does leading to the relative stability of the operating system and its services. |
|
parallelism |
"The performing of two or more tasks at the same time." This can occur only when at least two processors are present in the hardware. |
|
concurrency |
"The illusion that two or more tasks are being performed in parallel." Concurrency is created by an operating kernel's support of multiple threads. Concurrency becomes parallelism once there are other processors to which a second thread can migrate. |
|
multi-threading |
"Programming paradigm in which some tasks are accomplished concurrently." This includes the analysis, design, and implementation of a program that splits execution into at least two parts that can be concurrently executed. |
|
multiprocessing |
"Execution of a program using two or more processors." The existence of a second processor potentially brings multi-threaded code in contention for the same resources at the same time. |
|
uniprocessing |
"Execution of code in a single-processor environment." Until NetWare 4.11, this was the environment in which all code executed. |
|
preemption |
"Suspension of an executing thread or process on a CPU to replace it with another." Preemption also tests the multiprocessing worthiness of code since predicting when it will be preempted is usually beyond the code's ability. |
|
nonpreemptive |
"Condition of execution in which the running thread or process retains control of the processor until it explicitly or implicitly relinquishes it." This was the case of NetWare until 5.0 and then, only of code running in user mode (see this term). |
|
multi-thread-safe |
also,multiprocessor-safe, "Multi-threaded program written such that concurrent operations do not contaminate or misuse shared data and resources." This is the correctness aspect of implementing a multi-threaded program. If code is not multi-thread-safe, it will fail to execute safely in environments that include multiple processors or preemption. |
|
funnelling |
"The act of relocating a thread's execution from one processor to another." Multiprocessing NetWare, starting with 4.11 SMP, provided for funnelling threads in older applications to make them safe. Even threads from safe applications are funnelled into some residually unsafe kernel code. Funnelling is highly inefficient execution and can lead to code executing more slowly than if run on a uniprocessor machine. |
|
synchronization |
In the context of our discussion, this is "the use of special variables or objects that protect data and resources with advisory locks." Careful synchronization is part of the way multi-thread-safe applications achieve their correctness. |
|
scaling |
"Code's ability to take advantage of the addition of more processors and achieve incremental increases in performance." This can only be achieved by correctly multi-threaded coding. The goal for multi-thread code is to achieve their output on one processor multiplied by as many processors as are added to the hardware. |
These definitions by themselves say a lot about how NetWare has evolved over the years. The main objective facing most application programmers as well as Novell engineers is to write (or rewrite) code that is correctly multi-threaded so that it scales well.
Overview of Threads and Context
This section discusses the following: thread versus context, context and thread creation, thread state, thread yielding, and suspended and blocked threads.
Thread versus Context
The first concept in NKS thread programming that merits a strong discussion is the difference between a thread and its context. Traditionally in NetWare and in other thread-programming models, a thread is closely identified with the data structures that make up its context, and the two are inseparable. NKS, however, distinguishes between the two for a useful purpose.
(Incidentally, since underneath NKS lies an operating kernel that can continue the traditional associations, the actual implementation of NKS threads proceeds along lines predictable on the implementing platform. Thus, on NetWare, when an NKS thread is actually running, it is executed using a thread kernel object that will appear in the debugger as expected.)
NKS distinguishes a thread from its context in a way that tempts us to use as metaphor a ghost story. Imagine a thread as a sort of life force that can do nothing of itself. Imagine also context as a body that such a life force can inhabit. A context defines the appearance of a thread by determining where the thread starts executing, how much stack it uses, what its per-thread data might be, and an almost limitless number of ways to distinguish itself from other contexts.
The thread is a vehicle for execution. Under programmer control, a thread comes to pick up and animate a piece of context much as some green gas picks up and walks around in bodies from the grave in the Night of the Living Dead. Like all metaphors, this one can become absurd, but the point is that contexts are pieces of work with a variety of aspects including state while threads are what give life (execution) to the context.
With this metaphor in mind, it will be easy to understand in later discussions what properly and permanently belongs to a thread (very little) and what belongs to context (practically everything useful to the programmer). Now, that I've established this, I want to go back on what I've said a little bit because by default, creating a thread to run a context will bind the two together as tightly as has been the habit in the older thread-programming model on NetWare because the majority of use is expected to follow that procedure. The utility of overstating the distinction of thread and context is in other possibilities that their separation make available and which will be discussed here.
Context Creation
Contexts are created much as threads were created in earlier programming models on NetWare. A start function, stack size, and other aspects are specified.
#include <:nks/thread.h>
NXContext_t NXContextAlloc( void (*start_func)( void *arg ), void *arg, int priority,
NXSize_t stackSize, NXSize_t privDataSize, long flags, int *error );
In the thread- and context state diagram (see Figure 1), this function creates the initial state of a context with no thread to run it.
Figure 1: NKS thread/context state diagram.
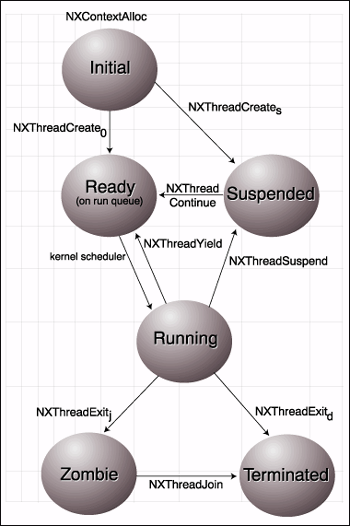
The NKS thread stack cannot be user allocated as is possible when programming to CLIB or directly to NetWare. This is by design: It frees the programmer from dealing with stack life cycles and enforces better programming style. However, the size may be prescribed. The stack allocated for it by NKS will be in user-space or in the kernel, depending on the locus of execution of the calling NLM. The stack works identically to stacks in any other NLM on NetWare in that it can be viewed in the system debugger from ESP using d or dd, or using the dds command.
Thread Creation
The thread is created with a context for it to run by calling a different function to which the context is passed.
#include <nks/thread.h> int NXThreadCreate(NXContext_t context, long flags, NXThreadId_t *id);
The thread's actual runtime (normal or worker thread) state is a function of the context. In this article, we will not discuss work-to-dos, but only normal threads. The context may have been created with a low, medium or high priority as a hint to the kernel scheduler. This priority is ignored when the NLM is executing on NetWare because priority isn't supported. If you are writing NLMs that run on NetWare, where NKS is supported, you will need to take this gap into account.
However, initial state of execution of the thread can be specified through the flags argument to NXThreadCreate. For example, the thread can be created in a suspended state (NX_THR_SUSPENDED). It can be a detached (NX_THR_DETACHED) or a joinable (default) thread. It may be noted through these flags that the context run by the thread should (by default) or shouldn't be (NX_THR_DONT_DESTROY_CTX) automatically freed upon termination.
By default, a thread is considered to be bound to the context passed in NXThreadCreate. Again, this is somewhat in opposition to what I set out to say. Later, we'll discuss thread swapping and, in another article, work-to-dos where the ultimate distinction between thread and context will be an essential one.
Thread State
Once a context has been created, thread creation will launch the whole process into a series of states controlled by the programmer according to this diagram.
Except for promotion from the run queue to being the executing thread, each state is reached through programmer action. The initial state of a context is threadless as noted previously.
The next state is one of two. If the thread was created with the suspended flag, then it will become suspended. By default, threads are created in the run queue to run as soon their turn is reached.
Thread Yielding
A currently executing thread can relinquish execution explicitly by calling
#include <nks/thread.h> int NXThreadYield( void );
In NetWare parlance, this means it adds itself back to the end of the run queue, permitting other threads to run. Normally, a thread would reach, through a call into an I/O function or other blocking service, a point at which it would implicitly yield the processor. However, there are a number of reasons a thread might explicitly want to give up its turn at executing. One historical reason is conformance to the `nice guy' rule of NetWare programming.
Because NetWare has been nonpreemptive historically, it has been on the shoulders of the developer to determine how much work can be accomplished without cheating other threads of their turn on the processor. Moreover, Novell Labs has had a criterion or threshold of how long any one thread of a certified NLM can monopolize the processor. To meet this criterion, developers have sprinkled explicit yields in their code. Unfortunately, increases in the speed of the processor over the years have led to a situation in which the processor is performing more and more context switches per second for NLMs coded this way. Context switches are not a measure of true performance, but of how much opportunity to work the processor has lost. What took up too much time and failed the time-slice test on an Intel 486 is now easily beating that threshold by several times on the latest Pentium processors.
So, what must be done to correct this? In general, you should try not to sprinkle yields throughout your code as if using a salt shaker, but in places where it makes sense, more, if necessary to pass certification, especially on slower processors. We have fixed the underlying yield code in NetWare 5 to measure the frequence of yields and do them less often when appropriate. Consequently, you must not think that an explicit yield will actually result in being moved to the end of the run queue nor should you try to predict when the yield will be ignored. The kernel will make this decision. No application should make any assumptions about it.
Suspended and Blocked Threads
A thread can be created in the suspended state or it can be put in this state using the interface
#include <nks/thread.h> int NXThreadSuspend( NXThreadId_t thread ); int NXThreadContinue( NXThreadId_t thread );
The thread itself cannot achieve this directly. This is a big difference with other threading models in use on NetWare including CLIB and direct programming to legacy NetWare threading primitives. It is widely considered incorrect for a thread to suspend itself, so NKS will not permit it. To allow the explicitly suspended thread to continue, call the second interface.
A thread will become suspended due to its own action by calling a blocking function or a synchronization function; for example, it enters this state when it contends for a mutex that another thread has already acquired. However, this blocking or sleep state (see later comments on mutex), which might have been better shown using a different oval in the illustration, isn't the same thing as suspension: a thread blocked on a mutex cannot be continued from that state.
Joinable Threads and Thread Termination
NKS supports the notion of joinable threads, which is new to NetWare thread programming. This notion only applies significantly at thread termination. Prior to termination, joinable and nonjoinable (detached) threads are identical. A joinable thread waits around after termination so that another thread (which itself may or may not be of the joinable variety) can discover its exit status. This is a simple synchronization mechanism.
The state of termination is really more a concept than a usable state. To the programmer, it isn't very meaningful except in the sense that it is a convenient notion by which joinability can be explained. Except when joinable, a thread that has fallen off its last program brace (}) or has explicitly terminated by calling NXThreadExit is gone, and even joinable threads have gone away back to the kernel (for threads are kernel objects). What remains in the case of the joinable thread is the context and its exit status that can be read by another thread by calling the join interface.
#include <nks/thread.h> int NXThreadExit( void *status ); int NXThreadJoin( NXThreadId_t wait_for, NXThreadId_t *who_died, void *status );
As you saw the interesting thread/context state named zombie in Figure 1, you naturally thought I was going to get into my Night of the Living Dead metaphor again. This is for the joinable thread that has just been briefly described. This name labels very well the final state of a thread that has finished processing: it is for all intents and purposes dead since it is not executing, it is not on the run queue waiting to execute, and it is not suspended in any useful sense. Instead, it is a zombie because it is dead but has not been completely destroyed.
A joinable thread becomes a zombie when it is ready to terminate but needs to communicate its death to another, inspecting thread as if it must keep publishing its obituary until someone reads it before the zombie can go away. The concept has long existed in POSIX' pthreads and the UNIX International (UI) thread-programming interfaces, but is, as previously noted, new to NetWare.
This operation of reading the obituary or inspecting the thread is called joining. By default, NKS threads are created joinable. When a thread is joined, it communicates its termination status code (to continue our metaphor: the reason why it died) as decided upon by the programmer. If you have ever explicitly returned a value from main or by calling exit to communicate the success or failure of a program to the shell on UNIX, then you have exercised the concept of returning a termination status code.
It is not necessary to wait for a joinable thread to die before joining it. Perhaps this is a little bit ghoulish; it's like taking out a life insurance policy on a sibling with the expectation that he or she will soon die and you want notification as soon as it happens. When the thread dies, the joining thread gets the exit status. (The join interface goes much further in that if NULL is passed as the identity of the thread to be waited on, the function returns the identity and status of the next application thread to die.)
Why is joining useful? A smartly coded application might find resource management easier if it knows when its threads die. The other reasons are limited only by imagination. For example, since an application must manage its own contexts, it may have some difficulty knowing when those contexts may be freed. Joining may be a solution (so would refraining from passing the don't-destroy flag when creating the thread). However, joining a thread for the purpose of synchronizing code or data is probably not the best thing to do if it means that this mechanism is used to supplant condition variables or other synchronization objects that are more efficient at such operations than the relatively costly process of creating and terminating threads.
A joinable thread does not actually have to be joined. The library will clean up all unjoined threads at unload. Failure to join a thread in a long-lived application, however, will result in loss of memory and other resources. This is discouraged as bad practice. Instead, create a detached thread. Detached threads cannot be joined and are traditional threads in the NetWare sense. However, they can join any joinable threads. The first thread of an application, the one that executes its main function, is created by the library as a detached thread.
Swapping Contexts between Threads
Now we get to the point about threads and contexts being separate and distinct. If a thread is created with the flag NX_THR_DONT_DESTROY_CTX, this interface is used to switch from the context hosted on that thread to a different one, thereby achieving a coroutine style of programming. The interface is:
#include <nks/thread.h> int NXThreadSwapContext( NXContext_t next, NXContext_t *prev );
Contexts can thus be scheduled on a pool of threads. If the original context (the one on which NXThreadSwapContext was called) is reused by calling this function again from another thread, that thread will begin executing where the one that abandoned the original context left off since part of the context is the processor state. To be clearer, the sequence of events is (read pseudocode of first function; follow to second; then return to first):
NXContext_t context1, context2;
void RunOnContext1( void )
{
NXContext_t dummy;
err = NXThreadSwapContext(context2, &dummy);
...coming back from context 2, continuing on context 1...
}
void Context2StartFunc( void *arg )
{
...running on context 2; this is its start function...
err = NXThreadSwapContext(context2, &context2);
...anything after here isn't executed; as if longjmp were called...
}
This is a concept remotely reminiscent of setjmp/longjmp.
Thread-specific Data and Key-value Pairs
It is useful to the application to associate data with a specific thread. For example, perhaps the thread is performing some service on behalf of a registered client. It will save away a connection, a directory path, a credential obtained on behalf of that client, etc., for reuse every time it performs an operation. In the case of LIBC, it wants to maintain for each thread the notion of errno and other "global" variables like the string currently being processed by strtok or the time string returned by asctime. So, key-value data pairs are the NKS implementation of "per-thread global variables."
There are two ways an application can manage and access thread-specific data supported by NKS. The first and fastest way is to use the private data area. You may have noticed in the prototype to NXContextAlloc, a size argument for this purpose. The context's private data area is allocated, like the stack, by the library at the time the context is created. Later, a call to
#include <nks/thread.h> void *NXThreadGetPrivate( void );
on the part of the thread bound to or animating the context will retrieve a pointer to this area. The contents of the area are application defined. By convention, no other cooperating application or library (full-blown NetWare applications tend to make use of other NLMs) should be using the area since only the creating application knows about it its size and format. There is only one and no overloading can be done except by strict cooperation at the coding level.
A simple use of this area would be to hold a structure whose type is defined in C. Getting a pointer to it permits immediate use of whatever the structure holds.
The limitations on the private data area make it useless to code that doesn't know about its internal format like libraries since they provide interfaces to applications whose data they can know nothing about. Per-thread data has been at ill-supported feature at best in CLIB. To overcome the past trouble in furnishing a per-thread data area for unpredicted use, NKS innovates on NetWare a concept from pthreads called the key-value pair.
Key-value pairs are like arrays of per-thread data. A key is created its meaning is arbitrary and only understood by its creator and reserved across all contexts in the current NKS virtual machine in which the application runs. We haven't discussed the virtual machine yet (we will do so in part three of this series), but in general it can be thought of as the environment in which one and only one NKS application runs. This means that migrating threads outside it (a common NetWare programming concept) will render the keys useless, and care must be taken not to attribute meaning to keys on a context that a helper NLM might come to know. But more on this later.
A key can be associated with a pointer or a scalar value that is different for each context. For example, an application might create a key and associate with it a deep error value la errno that its code sets inside various functions. The interfaces for key-value pairs are
#include int NXKeyCreate( void (*destructor)( void * ), void *value , int *key); int NXKeyDelete( int key ); int NXKeyGetValue( int key, void **value ); int NXKeySetValue( int key, void *value );
When a key is created, a function is associated with it that will be called for every context when the context is freed. This destructor will be called using the current value associated with the key being destroyed. If the data associated with the key (the key's value) has merely been allocated using NXMemAlloc, for example, the destructor to be passed might simply be NXMemFree since the latter accepts void* as its only argument. A NULL can be passed in place of a function pointer for a destructor and should be where the value associated with a key is only some integer, as in our simple example.
Setting and retrieving the values associated with keys are trivial operations. Consider the key as an index or subscript into an array: "key 1 is where I keep errno, key 2 is where I keep a pointer to my connection structure with the remote server name and the path to my client's configuration file." Setting an integer, enumeration (enum) or other scalar value for a key merely involves casting the value to void*.
NXKeyDelete does not call the destructor function for every context when a key is deleted. This is mostly because freeing data that may be in use by other threads is too precarious. Consequently, it isn't a very good idea ever to call this function if it can be avoided. Calling it for keys whose destructor does nothing or is nil will not result in lost resources, but it may be confusing to other threads trying to retrieve data associated with that key and that key will ultimately be reused if more keys are created later, resulting in potential confusion as to what the key really refers to.
As already noted, keys are only meaningful within the containing NKS virtual machine. Why this is important will be explained later, but it is good to note that though libraries might make use of keys on behalf of applications, they must be careful if more than one application (and therefore more than one virtual machine) is calling. In principal, a library is more interested in the virtual machine that a calling thread belongs to than any thread-specific data. Hence this warning. The example of errno, strtok, and asctime isn't construed to make you think this is how we actually implemented these interfaces in LIBC, but chosen because more suitable examples would not have been so easily understood without considerable commentary.
Migrating NKS Threads between NLMs
Migrating threads between NLMs is a long-standing practice on NetWare. It is also at the root of many of my own nightmares in the bowels of labs at Novell over the years. When I say migrating, I don't mean a thread calling into and coming back out of a function in a library NLM like CLIB that was written to support this sort of thing. I mean, instead, that the thread journeys into an NLM that performs extensive work often in partial ignorance of the calling thread and in which the thread unwittingly acquires locks or otherwise creates state that, if the calling NLM were terminated, would result in anything from lost memory resources to a hung server. A series of figures illustrate this later.
By the way, NetWare allows threads to be killed without bothering about locks or providing a competent cancellation mechanism. This is perhaps because the evolution in NLM complexity couldn't have been too clear in 1988 when the version of NetWare that introduced NLMs was being written. NLMs were to be an efficient, dynamic, and comparatively painless way to extend the kernel. The new multiprocessor kernel in NetWare 5 and the NKS interfaces are meant to endow NetWare with the latest multi-thread technology and techniques, but they can only do this if programmers play by the rules. Old NLMs and NLMs from nonparticipants are simply going to exhibit these dangers (that our up-and-coming platform code-named Modesto has been expressly designed to solve).
Let's first revist the problem of creating keys in a library NLM. Libraries can in fact create keys on behalf of a calling application, and this will work because the context on which the call is being made is known to NKS and the key will be for that virtual machine/application. But the library must not assume that the key it got for one application will have a relation to one it created on behalf of another! This must be taken into account and a table set up for each library client. This might mean that using keys may be too cumbersome a thing for a library to do.
However, there is a much nastier problem alluded to by mention of an NLM holding locks as a result of another calling into it. If a thread is terminated while it holds one or more locks in its own and especially in another NLM, this is a catastrophe. I term this situation and a whole potential world of problems like it cancellation because killing or unloading an NLM is a process of cancellation.
Cancellation is the general term for the concept of a thread becoming inoperative in some way, usually by suspension or death. Suspending and killing threads are useful operations in most applications, but they present a difficult situation when it is unknown whether the thread undergoing such treatment holds a lock, for if it does, other threads contending for that lock will become blocked and the application could crumble in on itself functionally, or, worse still, another program calling into an application or library might hang because of it. In NetWare, when this hang occurs at unload and involves the system-console thread, the console becomes permanently inoperative a catastrophic situation.
Correctness
This problem of a thread becoming inoperative while it holds a lock or other resource and thereby denies its use from other threads is an important issue for NLMs because of the peculiarly free relationships between them, especially in kernel mode (ring 0).
Latency
Using CLIB, it was possible to suspend a thread by calling SuspendThread (even the calling thread could suspend itself), but not to kill it. In NKS, it is possible to suspend another thread using NXThreadSuspend, but there is not presently an interface to kill it (although it can kill itself).
Actually, suspending or killing isn't what such interfaces do. Instead, they mark the thread for sleep (suspension) or death, and the marked thread continues on until it reaches a cancellation point at which time the library (NKS, which offers the cancellation point at the beginning and/or end of most of its interfaces) puts it to sleep, and, if required, kills it. The delta between the time this marking occurs and when the thread reaches the cancellation point is described as latency and is a particular problem. Under certain complex circumstances which will be discussed below, latency is an important consideration.
Suspending and Killing: The NLM Legacy
The problem of correctness has haunted NLMs and particularly CLIB with increasing worry over the years. The introduction of multiprocessing to NetWare sent the problem nearly to the number-one spot on the software defect hit charts.
CLIB suspended or killed threads marked for such as soon as they reached the next cancellation point. The NetWare OS provided some primitives to regularize the state of some resources the thread was holding or blocking like the keyboard, awaiting the response of a NetWare Core Protocol (NCP) packet and even a crude mechanism for cancelling its hold on a semaphore, the only synchronization variable available in original NetWare. However, with the advent of multiprocessing, releasing the hold a thread has on semaphores and other, more complex synchronization variables becomes difficult to impossible.
NKS has chosen to assert less positive control over the situation. Correctness is now a burden on the shoulders of the NKS application (and programmer) rather than on the library, which cannot hope to do better than CLIB in the delicate interplay of NLMs on NetWare.
NKS offers roughly the same cancellation-point opportunities to callers that CLIB did. Most interfaces in NKS that perform complex operations, or are likely to block or call through into NetWare or other low-level components, check for pending cancellation upon entry, and, to reduce latency, again upon exit.
An application that only calls into NKS and one could hardly imagine such an application performing much real work is protected against incorrect behavior by the placement of these cancellation points and by library knowledge about thread and lock state. For example, when a thread acquires a lock of any sort, it is marked against cancellation, so that even though another thread might mark it to be suspended or killed, this won't happen until the thread abandons all locks it holds. Thus, the library won't honor cancellation requests when it knows specifically that the situation is unsafe. This increased latency may or may not be a problem for the programmer who must deal with it.
Unfortunately, other NLMs library or not do not and cannot take the care that NKS exercises in this matter. Guarding against this is the programmer's responsibility.
As implied, most NKS applications will make calls into foreign components under NetWare that may acquire locks or other resources. The NKS library cannot be made aware this is happening as will happen on its native Modesto platform where the kernel will track them all and make dying threads rewind their way back through each virtual machine with appropriate error codes (which, one hopes, will be appropriately handled by those components). Consequently, acquiring a lock places a responsibility upon the thread programmer to avoid getting suspended or killed. This is done by performing explicit cancellation control in NetWare using NetWare-specific interfaces that are not properly speaking part of the NKS set.
Illustrations
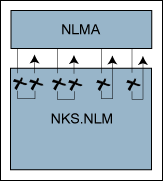
The first example (Figure 2) shown is that of an NLM that calls into the library. Illustrated are the cancellation points of the many interfaces (cancellation points are shown as checked before as well as after the function's task, another only before and still another only after the task). NLM A calls only into the library and all of its doings are known, so the programmer need take no special precautions with respect to cancellation. If a mutex is acquired by imaginary threada, for example, it will be marked, and should threadb call NXThreadSuspend (threada) on it, the suspension won't actually occur until after the first thread has called NXUnlock.
Figure 2: Illustration of cancellation points in the NKS library.
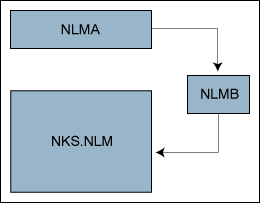
In the second example (Figure 3), NLM A calls into NLM B and NLM B calls (on A's thread) into NKS.NLM. This is termed thread migration, and while it is one of the phenomena explicitly handled by Modesto's kernel, no such control is to be had on NetWare. NLM B may very well have waited on an acquired a mutex or semaphore. Unless the design of NLM A included specific and accurate details about NLM B's behavior and knew for certain that B would not acquire a lock, NLM A's thread could be suspended or killed, leaving resources blocked by the call made in B, leaving B in a problematic state because the library knows nothing about the lock B acquired and won't disable cancellation for A. If NLM B is some important kernel service, this could have the gravest of consequences for more than just NLM A!
Figure 3: Complex inter-NLM relationships.
The solution to this situation is for NLM A to explicitly mark its thread as not-safe-to-cancel by calling nxCancelDisable, deferring cancelling until later. When this thread returns to NLM A (returns from the called function in B), then nxCancelEnable can be called, restoring cancellability to the thread. If the thread had been marked for suspension or death by one of its sibling threads in NLM A, this could occur the next time a call was effectuated into an interface of NKS that offered a cancellation checkpoint. Or, NLM A's thread could explicitly check to see if it was cancelled while in NLM B (and wherever else NLM B took it) and allow itself to be cancelled by calling nxCancelCheck. This explicit action is called polling.
Note that this deferral capability only applies to the NKS library. Only NKS refuses to stave off suspension or death of an NKS thread that is cancel deferred. Other libraries and components won't be so courteous. Some anguish will be left over for the programmer using legacy components and nonparticipating NLM libraries.
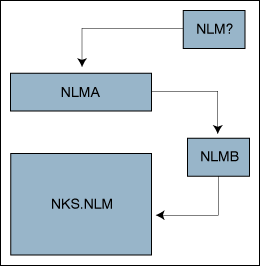
Any other code (another NLM as shown in Figure 4) calling into NLM A, if this NLM exports interfaces for use by yet other NLMs, must either know accurately whether A's interface will acquire locks or lead the calling thread into B or still another adventure in yet another NLM. Code calling NLM A cannot assume that because it is an NKS NLM, it is safe unless NLM A (actually, its programmer) certifies itself as correct. However, the thread of a foreign, non-NKS NLM can call safely into NLM A because NKS.NLM will not (cannot) perform cancellation on a foreign thread.
Figure 4: More complex inter-NLM relationships.
Summary of Cancellation and Cancellation-Point Management
The solution to the problem of correctness in cancellation is the use of both implicit and explicit cancellation points maintained by the library and the application through polling. The application has the burden of remaining very aware of where its threads may wander and whether they can be indiscriminately cancelled. It is recommended that the programmer explicitly disable cancellation while in unsure circumstances (calls into foreign NLMs, etc.) and reenable it when safe.
Synchronization
Use of synchronization is the last topic this article treats. Synchronization deals with ensuring that data or resource accesses don't occur at the same instant from two or more threads. At first glance, the word seems inappropriate since it is generally used to describe setting up events to occur at the same time, but in fact, it is not the data accesses that are being set up to occur at the same time, but the data access event in one thread with data nonaccess in one or more others. Whatever the justification for this term, data sharing is the reason that multi-threaded programming is so difficult.
First, it must be determined whether it is necessary to synchronize access to data. This is an object of program design. Some memory locations will be read-only from the beginning or after program initialization and won't need synchronization. Other locations must be preserved against more than one thread frequently writing to them at the same time. In between, there are data that are changed only infrequently. NKS synchronization variables provide for the extreme cases and cases in between.
Originally, the only synchronization primitive that existed in NetWare was the semaphore. NKS exposes a variety of other primitives because they are available from the new NetWare 5 multiprocessing kernel or because, in the case of 4.11, they have been implemented atop the legacy semaphore object.
Synchronization Variables Advisory
Following is a short expos on each synchronization variable that NKS furnishes. These locks are advisory only. This means that if a lock is set up to control access to a piece of data, the actual access of the targeted resource isn't magically prohibited until the lock is acquired. File-locking schemes are often integrated into the file I/O interfaces in such a way as to prohibit access to a byte range that has been locked by another entity, but with synchronization variables such as these, nothing in the library or the operating system will actually impede access to the protected data. This means that synchronization is a little like a game of Simon says. If the programmer forgets and accesses the data in code somewhere without having first acquired the lock, there is nothing in the compiler, linker, loader, library, or operating system to stop the access and the data may become corrupted.
Mutex
Mutually exclusive locks (or mutexes) serialize access to a shared state by assuring a single, exclusive owner.
#include <nks/synch.h> NXMutex_t *NXMutexAlloc( NXHierarchy_t order, NXLockInfo_t *info ); void NXMutexFree( NXMutex_t *mutex ); void NXLock( NXMutex_t *mutex ); void NXUnock( NXMutex_t *mutex );
Mutexes perform complete serialization to a resource, allowing access by only one thread at a time. They have in past times also been called sleep locks because their implementation acts to put to sleep (NXThreadSuspend) any thread contending unsuccessfully for a lock. All threads contending for a mutex are placed on a sleep queue and awakened one by one with acquisition of the mutex. Acquiring a mutex is construed to mean that the resource protected by it can now be manipulated by the owning (acquiring) thread.
An example of a resource that might be protected by a mutex is the linked list. If a linked list is highly dynamic, that is, if it is frequently changed, and if the changes are performed by more than one thread potentially, then a mutex might be a good way to serialize access to it.
With the notion of thread priority comes the implicit concept of priority in the mutex acquisition sleep queue. In other words, if a high priority thread is contesting a mutex with other, lower-priority threads, the latter should be positioned to acquire the mutex first. Unfortunately, this isn't yet implemented on NetWare, and, in the meantime, isn't even an advertised feature in NKS. But it may become one someday; the NKS documentation for thread and lock priority should be consulted.
The mutex is the cheapest of all NKS synchronization variables in terms of overhead, work to acquire, etc. Other variables exist for clever purposes, but the implementor should prove their preference over the mutex because of their relatively higher cost. A good idea would be to make the choice of variable part of the implementation design document for the locking code to be written and then to update that document if and when after profiling, it is determined that a different variable type proves superior.
Read-Write Lock
Some resources don't change very frequently and so there is a special twist on the mutex called the read-write lock. Read-write locks are sort of mutexes that permit any number of readers to acquire, but when write acquisition is requested and obtained, no readers can acquire for the duration of the write lock. Because they are a bit more costly in their implementation than mutexes, they are not to be preferred over mutexes without a) determining the ratio of potential write requests to read requests and b) profiling the actual result to verify that the correct lock choice was made.
All aspects of the mutex except for the one just discussed apply to read-write locks.
#include <nks/synch.h> NXRwLock_t*NXRwLockAlloc( NXHierarchy_t order, NXLockInfo_t *info ); void NXRwLockFree( NXRwLock_t *lock ); void RdLock( NXRwLock_t *lock ); void WrLock( NXRwLock_t *lock ); void RwUnlock( NXRwLock_t *lock );
Semaphore
The semaphore is a counting lock that permits up to a certain number of threads to "acquire" it. The number of threads permitted to hold a semaphore at any given time is given as the first argument to NXSemaAlloc. The concept of semaphore as a synchronization variable originated with a Dutch mathematician, Dijkstra.
A real-world illustration might best describe the semaphore's use. Imagine a railroad segment with one set of rails only. Rail traffic can proceed up and down the tracks, but only in one direction at a time. In fact, in the early days of the railroad, there was a track adornment called a semaphore that displayed the current direction of traffic on the track. As long as it indicated that traffic was flowing in the direction a new train was going, that train could venture out onto the tracks without worrying about a head-on collision.
In software terms, the head-on collision to be feared is data corruption or the reading of potentially incomplete or corrupt data. One example might be a licensing check system that permits a database (a file descriptor, perhaps) to be in use by n users. Each potential user as represented by a thread would attempt to acquire use of the semaphore by waiting on it. Once one "legal" thread posted its end of use, the next thread waiting would gain access to the database.
#include <nks/synch.h> NXSema_t *NXSemaAlloc( unsigned int count, void *arg ); void NXSemaFree( NXSema_t *sema ); void NXSemaPost( NXSema_t *sema ); void NXSemaWait( NXSema_t *sema );
Condition Variable
The condition variable is a sort of mixed synchronization primitive, like a cross between a mutex and a semaphore, and is good for check-pointing complex situations especially where threads are permitted to access a resource based on a change in some condition. As long as the condition is expressible in C, then it can be used to implement a condition variable. The condition variable uses a mutex to implement the sleeping point for the threads that must not access the protected resource.
An example of a complex situation to which the condition variable is adapted is the implementation of a producer-consumer or work-crew component where a number of threads are producing work (up to a certain amount) that consuming threads use without either type getting too far ahead or behind. An example of just such a component, coded in NKS, can be found in the SDK sample code.
#include <nks/synch.h> int NXCondAlloc( void *arg ); int NXCondFree( NXCond_t *cond ); void NXCondSignal( NXCond_t * cond ); void NXCondBroadcast( NXCond_t *cond ); int NXCondWait( NXCond_t *cond, NXMutex_t *mutex );
Additional Synchronization Interfaces
There are other interfaces beyond these. For each type of variable, for instance, there is a function that will perform the initialization of the variable as a part of a programmer-defined structure so that the lock doesn't have to be subject to so much allocation overhead. These are the init- and deinit functions listed in the documentation (and cited in the first article in this series).
For some locks, a calling thread can determine whether or not it is the owner of a lock, useful since none of the locks are guaranteed to behave well recursively. In addition, there are "try" functions for most locks. These attempt to acquire a lock, but don't block if it cannot be acquired. If the lock can be acquired, it is, and, if not, these interfaces return a value to that effect.
This interface can be useful to avoid deadlock, a notion elaborated below. Still other interfaces have a notion of timeout associated with them. A special interface permits a timed wait to acquire a lock and if the lock cannot be acquired before the timer expires, then the function returns an error. These two incantations on the locking mechanisms should be used sparingly and not as a remedy for bad lock design.
Dangers of Synchronization Variable Use
The use of synchronization variables creates a host of corner cases for their use. These corner cases lie in the area of blocking and cancellation, leading to deadlocks. An example of a deadlock is when one thread holds a resource lock (A) it needs to update and is waiting on another resource (lock B) that a different thread has already locked, and, for some reason, cannot abandon because it can't finish its work. If the work of the second thread includes gaining access to lock A held by the first, then the deadlock is labeled a classic ABBA. The first thread has A and waits on B while the second thread has B and is waiting on A.
There are a number of ways to avoid deadlocks. The first and best is to design a hierarchy of lock acquisition into the implementation restricting access to hierarchical locking to a sequence or policy that is identical for all threads. NKS has been designed to help prototype and prove such policies via a debugging mechanism in its mutex and read-write lock interfaces. As of summer 1999, no implementation had yet been accomplished, but it is expected to happen before the NetWare 6 Pack time frame. Nevertheless, this will be a compile-time debugging feature to help find policy infractions; it won't actually prevent them from happening.
The second way to avoid deadlocking is to use try-lock interfaces to test for availability, but such an approach is costly, wasteful, and potentially sloppy. In our ABBA case, if we acquire A and check for B, we must release A if B cannot be acquired, in order to avoid the deadlock. Consequently, an access loop must be set up. There are situations in which a perfect hierarchical lock acquisition policy cannot be set up or must be violated. Try-locking is useful in these situations.
The most serious corner cases for NetWare remain those of inter-NLM blocking and the problem of cancellation already explored. If a thread winds its way through "unknown" code in some NLM ignorantly acquiring a lock and then is cancelled by unloading or suspending, the NLM owning the locking code could be damaged in its ability to access an important resource. As NLM shut-down code is run through by the system console thread in the case of an unload request from the command line, the console risks becoming useless if it can't get the NLM down due to one of its threads hanging on a mutex"something that will happen if the thread that acquired the mutex was killed while still holding it.
In the end, the cardinal rule is that no thread must exit while holding any lock. Program architecture should be designed specifically to avoid this, just as it is important to solve all the other problems in the way of the task the application is to solve.
Sample Code
We have written some example code for common operations in NKS and published this code with the individual NKS function documentation on the web in the SDK. The URL is http://developer.novell.com/ndk.
Conclusion
These are the thread and synchronization interfaces that make up Novell Kernel Services (NKS) on all platforms to which it has been ported, but with details specific to NetWare programming. Nevertheless, most of the details covered hold for all platforms. The next installment of this article undertakes to cover the concepts of programming to the remainder of the library. The fourth and last in the series will talk about the relationship between NKS and LIBC, which sits atop the former, and the differences in programming to LIBC and NKS, making relevant comments about and comparisons to programming to CLIB.
* Originally published in Novell AppNotes
Disclaimer
The origin of this information may be internal or external to Novell. While Novell makes all reasonable efforts to verify this information, Novell does not make explicit or implied claims to its validity.