NDS Database Operations
Articles and Tips: article
Technical Writer
Novell Products Group
JOHN WILLIAMS
Technical Writer
Novell Products Group
01 May 1998
Provides an overview of NDS database operations including such features as partitioning, replication, distributed relationship management, and synchronization.
Introduction
The NDS database operations provide the features necessary to distribute NDS across multiple servers. These features include
Partitioning
Replication
Distributed relationship management
Synchronization
Partitioning
NDS divides the Directory tree into logical subtrees called partitions. Although any part of the Directory can be considered a subtree, a partition forms a distinct unit of data for storing and replicating Directory information. Partition boundaries cannot overlap, because each entry in the Directory must appear in only one partition.
Figure 1 shows a partitioned tree with Novell as the Directory tree's root partition.
Figure 1: Partitioned tree.
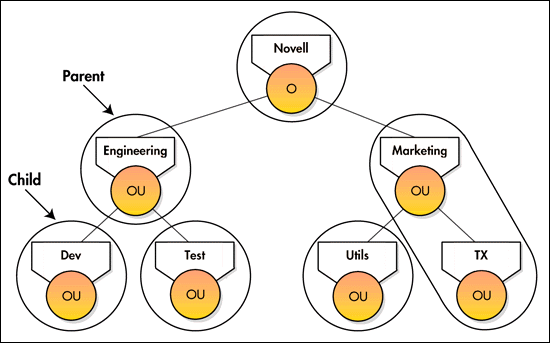
A partition subordinate to another partition is called a child partition, while its immediate superior is called a parent partition. Thus, engineering.novell is a parent partition and dev.engineering.novell and test.engineering.novell are child partitions.
Even though Figure 1 shows the NDS tree partitioned into six partitions, end users browsing the tree see the tree as one tree and are not aware of crossing any boundaries when they move from one partition to another.
Partitions must obey the following rules:
They must contain a connected subtree.
They must contain only one container object as the root of the subtree.
They cannot overlap with any other partition.
They take their name from the root-most container object (the container at the root of the subtree), which is called the partition root.
Replication
Replication adds fault tolerance to the database because replication allows the database to have more than one copy of its information.
A single instance of a partition is called a replica. Partitions can have multiple replicas, but only one replica of a particular partition can exist on each server. Servers can hold more than one replica, as long as each replica is of a different partition.
To manage replicas, NDS provides the following:
Different types of replicas
Replica lists
Replica, or partition, operations
Replica Types
Replicas must be designated as one of four types:
Master
Read/write
Read-only
Subordinate reference
One replica (usually the first created) of a given partition must be designated as the master replica. Each partition can have only one replica designated as the master. The other replicas must be designated as read/write, read-only, or subordinate reference.
The replicas are invisible to the end user; that is, the user does not know which replica contains the entries being accessed.
Master, Read/Write, and Read-Only Replicas
Three of the replica types (master, read/write, and read-only) are configurable by the system administrator:
The master replica contains all object information for the partition. Users can modify the objects and attributes which are passed to other replicas. All partition operations must occur on the server that stores the master replica of a given partition. Partition operations include such operations as creating child partitions and creating other replicas of the partition.
A read/write replica contains the same information as the master replica. Users can modify the objects and attributes which are passed to other replicas. The system administrator can create any number of read/write replicas. Partition operations cannot be performed on a server that contains only read/write replicas.
The read-only replica contains all the same information as the master replica. Users can read, but not modify, the information. The replica is updated with changes made to the master and read/write replicas.
Figure 2 shows three partitions (A, B, and C) replicated across three name servers (NS1, NS2, and NS3).
Figure 2: Storing Replicas.
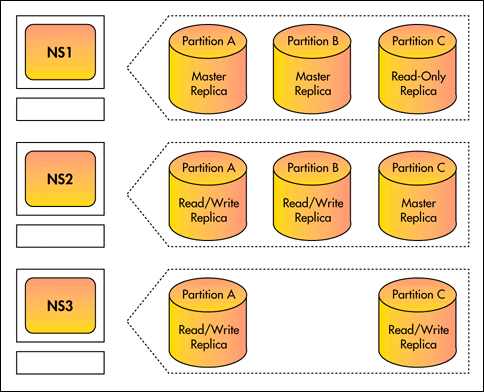
The servers in Figure 2 store the following replicas:
NS1 stores the master replicas of partitions A and B and a read-only replica of partition C.
NS2 stores the master replica of partition C and read/write replicas of A and B.
NS3 stores read/write replicas of A and C.
Given this arrangement, any of the servers could handle a request to add an entry to partition A. Only NS1 and NS2 could handle a similar request for partition B, and only NS2 and NS3 could handle such a request for partition C.
Only the administrator of NS1 can create a new partition that is subordinate to partition A or B, and only the administrator of NS2 can create a new partition that is subordinate to partition C.
Subordinate References
Subordinate references, which are not visible to end users or system administrators, provide tree connectivity. Each subordinate reference is a complete copy of a given partition's root object but is not a copy of the whole partition. As a general rule, subordinate references are placed on servers that contain a replica of a parent partition but not the relevant child partitions. In other words, a subordinate reference points to an absent subordinate partition. In this case, the server contains a subordinate reference for each child partition it does not store.
Subordinate references provide tree connectivity by referring to replicas the server may need to find. Because the subordinate reference is a copy of a partition root object, it holds the Replica attribute, which lists all the servers on which replicas of the child partition can be found. NDS uses this list to locate replicas of the subordinate partition.
Figure 3 shows a partitioned tree and the servers with their replicas.
Figure 3: Replica placement in a partitioned tree.
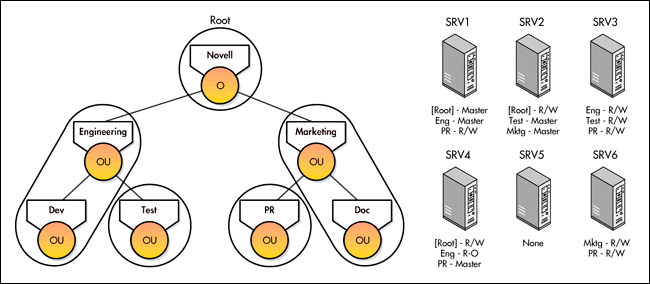
Some of the servers in Figure 3 hold replicas of the parent but not replicas of the corresponding child. These servers must also hold subordinate references to the child partitions they do not hold. For example, because server SRV4 holds a replica of the Eng partition but not of Test, it must hold a subordinate reference to Test.
Figure 4 displays the placement of the subordinate references. SRV1 requires subordinate references to mktg.novell and test.eng.novell because it holds replicas of the parent partitions but not of the child partitions.
Figure 4: Replica placement and subordinate references.
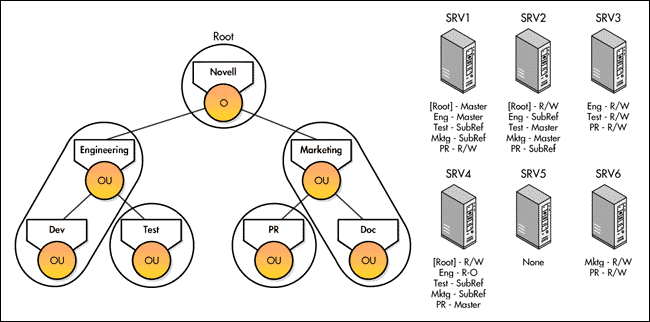
On server SRV1 in Figure 4, the subordinate reference of mktg.novell is a complete copy of the root object, mktg.novell, but not of its subordinate objects; the subordinate reference of test.eng.novell is a complete copy of the entire partition, since test.eng.novell is the only object in the partition. Users cannot change a subordinate reference's replica type.
Besides providing tree connectivity, subordinate references also help determine rights. Because a subordinate reference holds a copy of the partition root object, it holds that object's Inherited ACL attribute, which summarizes the Access Control Lists up to that point in the tree.
Replica List
Each replica contains a list of servers that contain replicas of the partition. The replica list is stored in each replica as a Replica attribute of the partition's root-most container entry. This list provides information needed for navigating the NDS tree and synchronizing the replicas.
The replica list contains the following elements for each replica:
Server Name. The name of the server where the replica is located.
Replica Type. The type of the replica stored on the server designated in the Server Name field. (The type is either Master, R/W, RO, or SR.)
Replica State. The status of the replica. (The status modes include On, New, Replica dying, among others.)
Replica Number. The number that the master assigned to this replica at the time the replica was created.
Network Address. The server's address.
Remote ID. The Entry ID of the replica's partition root entry.
The group of servers storing this information form the partition's replica ring.
Partition Operations
NDS allows administrators to create and manage partitions and their replicas. These operations, called partition operations, allow great flexibility in maintaining and modifying the Directory tree. Partition operations include the following:
Adding a replica of a partition. This operation involves placing a replica of a given partition on a specific server.
Changing a replica's type. This operation changes a replica's type, including creating a new master replica. For example, an administrator may want to change a read/write replica to a read-only replica to restrict changes to that partition's data.
Removing a replica from a set of replicas. This operation removes one or more replicas of a given partition.
Splitting a partition. This operation creates a new partition from a container in an existing partition.
Joining two partitions. This operation joins a parent and child partition, making one partition from the two.
Moving a partition. This allows administrators to move an entire partition and its contents to another part of the Directory tree without affecting connectivity or access control privileges.
All these operations involve two major stages: the initial operation involving the client and the master replica, and a second stage during which the partition changes are sent to each replica of the partition.
Distributed Relationship Management
Besides subordinate references, which help keep the tree connected, NDS uses three distributed relationship management components:
External references
Back links
Obituaries
External References
A server usually stores replicas of only some of the partitions in an NDS tree. Sometimes a server needs information about entries in partitions that the server does not store. Often, the server requires information about an entry in a parent partition or a child partition.
At other times, the server requires information about entries in partitions that are not parents or children of partitions it stores. For example, the file system may need to refer to these entries because entries from these diverse partitions have been granted rights to the directories on the server.
NDS stores this type of information in external references, which are placeholders containing information about entries that the server does not hold. External references are not "real" entries because they do not contain complete entry information.
Besides providing connectivity, external references improve system performance by caching frequently accessed information. Currently, NDS caches only an entry's public key. The Modify Entry routine stores the public key as an attribute on the external reference.
Creating External References
NDS creates external references for the following operations:
Authentication. A user authenticates to a server, and this user does not have an entry stored in a partition on the server. To enable authentication, the server must create an external reference so that an entry ID can be given to the authentication process.
Browsing. When a user, browsing the NDS tree, requests information about an entry that is not stored locally, NDS creates an external reference to the entry.
Security equivalence. Users who authenticate to the server can have security equivalence to entries not stored locally. Such objects require external references.
Properties of local entries. Some entries, such as groups, can have members that are not local entries. Each such entry requires an external reference.
File system. The file system uses entry IDs to maintain a list of owners and trustees of files and directories. Trustees or owners that are not local entries require external references.
NDS also creates external references when a replica is removed from the server. When this happens, NDS changes all of the entries in the removed replica into external references and marks them as expired.
NDS uses the following rules when creating external references:
NDS never creates an external reference below a real entry in the tree.
NDS never creates a subordinate reference below an external reference in the tree. Any subordinate references below an external reference will be removed during synchronization.
Deleting External References
On each server, NDS deletes expired external references if they have not been used within a specified time period. The system administrator can use a SET parameter to set the number of days after which NDS deletes external references that have not been used, are not needed for another entry's context, or do not contain information that the operating system needs.
To remove expired external references, NDS builds a list of unused external references by checking the life-span interval of each external reference. This interval defaults to eight days and thirty minutes.
The back link process checks to see if the file system must access any of the external references. This process then deletes any external references not accessed by the file system within the life-span interval. The janitor process then purges the deleted external references.
Back Links
When creating an external reference, NDS locates the non-local entry to which the external reference points. On that entry, it stores a Back Link attribute, which points back to the external reference. The back link maintains connectivity between the server holding the external reference and the server holding the object to which the external reference points. Figure 5 illustrates this procedure.
Figure 5: Back links and external references.
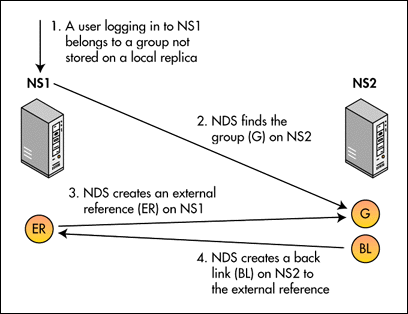
If NDS can't create the back link, it continues trying to create the link 9 times. The default retry interval is currently 3 minutes. If NDS cannot create the back link within 3 minutes, the task is assigned to the back link process. The back link process executes on a time interval set by the network administrator. Currently, the default interval is 25 hours.
NDS uses back links to update external references in cases where the real object has been renamed or deleted. The Back Link process has two basic functions:
Remove any expired and unneeded external references from the system.
Create and maintain any back links not created at the same time as the external reference.
When NDS removes an external reference, the back link to that external reference must be deleted. The server holding the external reference requests that the server holding the real entry delete the back link, and the server holding the back link then deletes the reference.
Obituaries
In a distributed database, each server receives updated information through synchronization. Because the servers do not receive updates simultaneously, the servers may not hold the same information at a given time. For this reason, each server holds on to the old information until all the other servers receive updates. NDS uses obituaries to keep track of such information.
Obituaries are attribute values that are not visible to clients and are used in server-to-server exchanges.
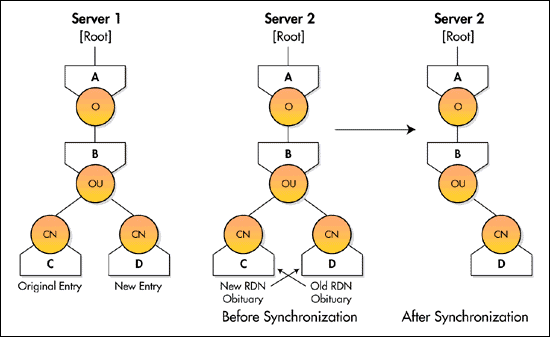
For example, Figure 6 shows how obituaries are used when an entry is renamed. On Server 1, the entry C is renamed to D. When Server 2, which holds a replica of entry C's partition, receives the update during synchronization, it keeps the copy of C and attaches an obituary (called New RDN in Figure 6) which points to the new object.
This obituary ensures that all servers can access C, even if they have not been notified of the name change. When Server 2 creates entry D, it attaches an obituary (called Old RDN in Figure 6) pointing back to the original object. After all replicas have been synchronized, Server 2 can delete its copy of C and remove the obituary from entry D.
Figure 6: Obituaries.
Primary and Secondary Obituaries
NDS uses two types of obituaries: primary and secondary. Primary obituaries keep track of entry-level modifications, including
Renaming an entry
Deleting an entry
Moving an entry
Moving a subtree
Generally, when data is changed, primary obituaries convey the changes to servers holding the affected entry.
Secondary obituaries convey the change to servers holding external references to the changed entry. The secondary obituary, also called a back link obituary, is placed on the entry's back link when the entry is renamed, moved, or deleted.
Obituary States
Both primary and secondary obituaries go through several states before they can be deleted from the database. Since secondary obituaries are linked to primary obituaries, all secondary obituaries must reach the state before the primary obituary can be marked as reaching that state.
Obituaries progress through the following states:
Initial--state assigned at creation
Notified--servers with copies of the obituary have been notified
Wait--timeout to ensure all changes are propagated to all replicas
Purgeable--servers with copies of the obituary mark the obituary as purgeable
Wait--timeout to ensure all changes are propagated to all replicas. Once they have been propagated, the obituary is deleted from the database.
Synchronization
Synchronization is the process of ensuring that all changes to a particular partition are made to every replica of that partition. The X.500 standard defines two synchronization mechanisms:
Master-to-slave
Peer-to-peer
The master-to-slave mechanism requires that all changes be made on the master replica. That replica is then responsible to update all the other replicas (slave replicas).
In a peer-to-peer synchronization system, updates can be made to any read-write or master replica. At a predetermined interval, all servers holding copies of the same partition communicate with each other to determine who holds the latest information for each object. The servers update their replicas with the latest information for each replica.
NDS uses both the master-to-slave and peer-to-peer synchronization processes, depending upon the type of change being made. The master-to-slave mechanism synchronizes operations such as partition operations that require a single point of control. The peer-to-peer mechanism synchronizes all other system changes. Most operations use peer-to-peer synchronization.
In NDS, the synchronization time interval ranges from between 10 seconds to 30 minutes depending upon the type of information updated.
To understand the NDS synchronization processes, you should be familiar with the following NDS features:
Loose consistency
Time stamps
Partition root entry information
Once these features are described, the remaining synchronization sections describe
Replica synchronization process
Other NDS synchronization processes
Loose Consistency
Because the NDS database must synchronize replicas, not all replicas hold the latest changes at any given time. This concept is referred to as loose consistency (called transient consistency in the X.500 standard), which simply means that the partition replicas are not instantaneously updated. In other words, as long as the database is being updated, the network Directory is not guaranteed to be completely synchronized at any instance in time. However, during periods in which the database is not updated, it will completely synchronize.
Loose consistency has the advantage of allowing NDS servers to be connected to the network with different types of media. For example, you could connect one portion of your company's network to another by using a satellite link. Data traveling over a satellite link experiences transmission delays, so any update to the database on one side of the satellite link is delayed in reaching the database on the other side of the satellite link. However, because the database is loosely consistent, these transmission delays do not interfere with the normal operation of the network. The new information arrives over the satellite link and is propagated through the network at the next synchronization interval.
Another advantage to loose consistency is that if part of the network is down, the changes will synchronize to available servers. When the problem is resolved, the replicas on the affected servers will receive updates.
Time Stamps
One critical component in synchronization is the time stamp, which records information about when and where a given value in a given attribute was modified. When NDS updates a replica, it sends a modification time stamp with the data to be updated. The replica compares time stamps and replaces the old information with the new.
Partition Information
For normal operations, including synchronization, to be successful, the partition root object on each server must store several important attributes and their values:
Replica Pointers--the local server stores a pointer to the remote servers that contain a replica of this partition. This pointer structure contains, among other things, the server's ID, address, and the type of replica stored on the server.
SynchronizedUpTo Vector--the local server uses this attribute to store a time stamp that indicates the last update the local replica received from each remote replica.
Partition Control--the local server uses this attribute to track the progress of operations such as splitting and joining partitions and repairing time stamps.
Partition Status--the local server uses this attribute to store information about the success of the last synchronization cycle.
Replica Synchronization Process
Because an NDS partition can be replicated and distributed across a network, any changes made to one replica must be sent to, or synchronized with, the other replicas.
NDS uses two timers to synchronize changes to replicas:
Convergence attribute--some changes, such as a change in a user's password or access rights, need to be sent immediately to another replica. When these high convergence attributes are modified, the replica synchronization process is scheduled with the fast synchronization interval of 10 seconds.
Heartbeat--less critical changes, such as a user's last login time, can be collected locally for a short period of time before being sent to other replicas. The heartbeat triggers a scheduled synchronization at least every thirty minutes. The network administrator can adjust the trigger's time interval with the use of the DSTrace console SET command. NDS adjusts the time if it must respond to expiring time outs.
In the source code, synchronization is known as skulking. The purpose of the synchronization operation is to check the synchronization status of every server that has a replica of a given partition. Factors that determine whether synchronization is necessary include the replica's convergence attribute, its replica type, and the time that has elapsed since the replica was last synchronized or updated. The system scans the partition records locally to decide which partitions need to be synchronized.
The synchronization process involves updating all replicas with all the changes made to a partition since the last synchronization cycle. The synchronization process takes the replica list and synchronizes the replicas one at a time to the replica that has changed.
Since NDS is a loosely synchronized database, an update made at one replica propagates to other replicas of the partition over time. Any modification to the NDS database activates the replica synchronization process. When a change is made locally to an NDS entry on one server, the synchronization process wakes up to propagate the change to other replicas of the partition. There is a ten-second hold-down time to allow several updates to be propagated in one update session. Replica synchronization proceeds one replica at a time throughout the replica ring of a partition.
After a server successfully sends all pending updates to one replica, it goes on to the next replica until all replicas have been updated. If the operation fails for one or more replicas and they are not updated in one round of the synchronization process, it reschedules them for a later synchronization cycle.
Since obituaries are attribute values, NDS synchronizes them the same way it synchronizes other attribute values in the replicas.
Other Synchronization Processes
The replica synchronization process synchronizes all changes to the entries and attributes in the NDS database. However, it does not synchronize everything in the database. It does not purge deleted entries and attribute values or synchronize external references and back links. Besides the replica synchronization process, NDS uses the following processes for synchronization:
Janitor process
Limber process
Back link process
Flat cleaner process
Schema synchronization process
Janitor Process. The janitor process runs after a replica synchronization cycle has completed successfully. It purges deleted entries and values that have been synchronized with all replicas. It also checks any entry that has been renamed, moved, or deleted. All of these operations involve the Remove Entry operations, which adds an obituary on the object being removed. If the janitor process finds any back links, it notifies the server that contains the entry's external reference to update that external reference.
Limber Process. At certain times, each server in the NDS tree checks and verifies that it still knows the correct tree name. This check occurs when
The server boots
The NDS processes are restarted
The server receives such a request from another server
A server can receive a tree check request when the server holding the master root partition of the tree sends out such a request because the tree name has changed. Other servers send out such requests when they initiate a server-to-server exchange and discover the other server has a different tree name. The limber process verifies the server's NDS tree name and updates it if the name has changed.
Back Link Process. This process verifies external references by checking to see if the original entry still exists and if the reason for its existence is still valid. If the external reference is no longer needed, the back link process removes it. By default, this process runs every 25 hours (1500 minutes). The default value can be modified with a settable parameter in the SET DSTRACE console command.
Flat Cleaner Process. This process updates the status and version attributes of the master replicas of NCP Server objects.
Schema Synchronization Process. The NDS schema can be modified by changing or creating attribute definitions and object class definitions. Such changes need to be replicated among all the servers containing replicas. This synchronization is done through the schema synchronization process. This process is started within 10 seconds following completion of the schema modification operations. The 10 second delay enables several modifications to be synchronized at the same time.
The updates to the schema are automatically propagated from one server to another, similar to the replica synchronization process. However, the schema synchronization process does not use a replica ring to determine which servers to send the schema updates to.
Schema updates are sent to servers that contain
Replicas of a given partition
Child partitions of the given partition
* Originally published in Novell AppNotes
Disclaimer
The origin of this information may be internal or external to Novell. While Novell makes all reasonable efforts to verify this information, Novell does not make explicit or implied claims to its validity.