The Anatomy of a Simple IntranetWare Client/Server Application: Part 1
Articles and Tips: article
Senior Research Engineer
Developer Information
01 Sep 1997
Centers on the development of a real client/server application called API_Info and covers such topics as construction and operation of NLMs, thread management, CLIB context, and communicating over the network.
- Introduction
- Part 1: The Anatomy of a Simple NLM
- Introducing the Server's Local IntranetWare OS
- Introducing CLIB Context
- Communicating Over the Network
Introduction
Novell Developer Information, the source of this publication, recently developed a CBT CD-ROM entitled "Intranetware Programming Fundamentals." This article is the first in a series which will take selections from the CBT and condense them for presentation to you in this magazine.
The purpose of this series is to give new Novell programmers a wholistic view of Intranetware developer issues and tasks. To enable that to happen, the discussions in the articles will revolve around the development of a real client/server application called API_Info.
Figure 1: User view of the client side of API_Info.
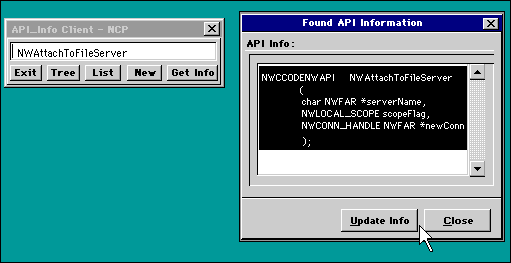
API_Info is a simple application designed to allow developers to access a trivial database of API prototypes located on a server.
The API_Info application itself consists of:
any number of API_Info clients running on Intranetwareclient32 enabled stations.
any number of API_Info NLMs running on Intranetware servers.
and an appropriate number of NDS objects in multiple NDS trees representing instances of the NLMs running on servers in those trees.
To give you an overview of the skills needed to develop an Intranetware client-server application, let's look at the Intranetware programming skills addressed and not addressed by this series.
In order to make the maximum use of this series, you must already have these prerequisite skills:
Be able to program in C.
Be able to program to your target client's desktop GUI.
your client and server development environments-if you are not using a special link tool like Base's NlinkPro product, you will probably need to use two different environments, your favorite environment for target client development,and WatCom for NLM development.
Able to perform basic Intranetware administration-e.g., install a server, an NDS tree, load and run an NLM, etc.
During this series , the development of API_Info will be discussed in the following order:
Article 1-The Anatomy of a Simple NLM
some simple load balancing guidelines.
how to develop a simple NLM
Using an NCP (NetWare Core Protocol) extension to expose your NLM's service on the network.
Article 2-Developing a Snapin
NDS schema composition
Designing new classes and attributes
Extending an NDS schema
The NWAdmin/snapin protocol
Article 3-The Anatomy of a Simple Client
How to develop a simple Intranetware client
Searching an NDS tree to acquire the optimal service instance for your client
Connecting to the service
Navigating NDS trees in a multi-tree environment
In IntranetWare, services are composed of NetWare Loadable Modules or NLMs. A service can consist of any number of NLMs on a single server or multiple NLMs communicating accross the network. On the NLM side of a client/server application, you need to be able to develop a service engine part of the NLM to perform the work of your application. This could be a database engine or a print service or any number of other things. The service engine part of API_Info's NLM is completely generic and has nothing to do with Intranetware. Therefore, after the release of the next article, we will provide you with the source for API_Info's trivial engine via the web.
Since multiple API_Info service NLMs can be installed on various servers throughout a tree, the client needs a way to find the service instance that is best for it and then connect to the service. To enable the client to find API_Info services, API_Info utilizes a special NDS object designed to contain network location information for an instance of an API_Info service NLM.
To provide for the administration of API_Info's NDS objects, a snapin for the NetWare Administrator application is needed. The second article of this series will discuss how to develop the API_Info snapin.
In the last article, we will discuss how to develop a client to find API_Info objects in NDS trees and then log in to the appropriate server and use a Intranetware feature, called an NCP extension, to communicate with the referenced NLM.
Part 1: The Anatomy of a Simple NLM
On the server side of an Intranetware client/server application, you must understand the construction and operation of an NLM so that you can make good NLM design decisions. The following discussion is intended to give you some guidelines that will help you determine what functionality you want to go into your NLM.
Drawing the Line and Sharing the Load
Programmers who are beginning to develop for NetWare are often experienced in single-platform development. In that kind of environment, applications are often monolithic; that is, their functionality is in a single executable file. Assume that API_Info exists as a monolithic application and that it is your task to decide which functionality should go into the client and which into the server. This decision-making process is called load balancing.
Figure 2: List of API_Info operations.

First let's draw an imaginary line to divide the two halves of our client-server application and then take the simplest and silliest course of action. We'll put all the application's functionality into the service, leaving the client with nothing to do but send commands to the service.
Figure 3: First attempt at balancing API_Info's functionality.
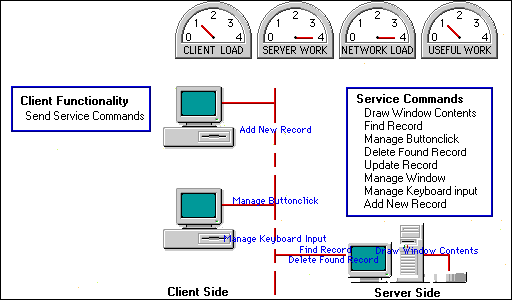
Let's also imagine that we have monitors which indicate the load on the three resources in a client-server scenario (the client, the service, and the network) and also tell us how much real work is actually being done.
As you can see in the monitors, in this configuration, the client's load is very light, while the server and network loads are maxed out resulting in very little real work being done.
Because that didn't work very well, let's try a different approach. Try to place each bit of functionality as physically close as possible to the resources which it needs to use.
Figure 4: Second attempt at splitting API_Info's functionality.
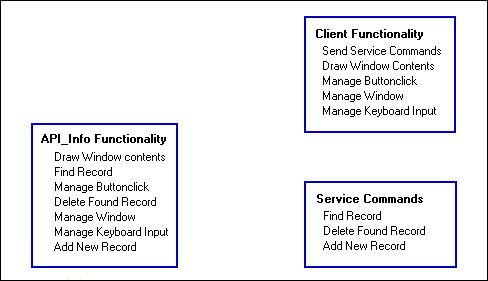
First of all, the client obviously needs to send commands to the service. In addition, the client should perform all user interface functions because the resources needed for the user interface reside with the desktop operating system on the client's machine.
Because the database file accessed by the server resides on the same machine as the API_Info NLM, all database access functionality should be put into the NLM.
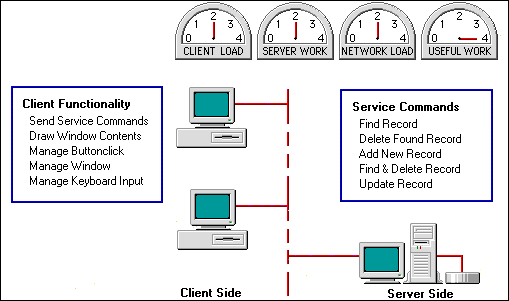
Figure 5: Results of the second attempt.
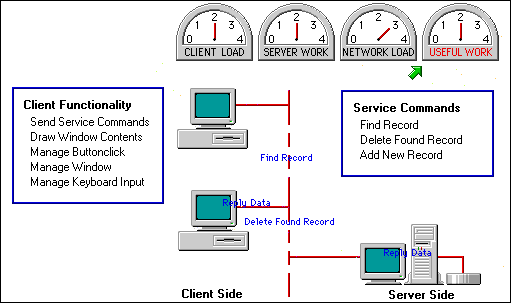
This adjustment balances the client and server loads, resulting in substantially improved work, but the network load seems a little high.
Figure 6: Consolidating operations to minimize network traffic.
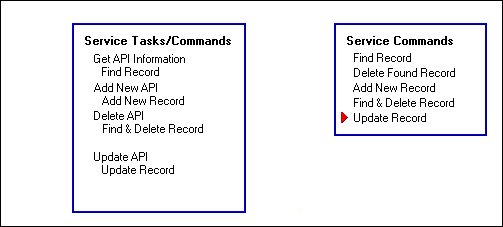
Perhaps we can lower the network load by optimizing the commands sent by the client to the NLM. Getting an API prototype requires one command to be sent over the network.
Adding a new API prototype record also requires one command.
This version of API_Info, however, requires two commands to delete a record and three to update one. We can achieve an optimization by adding two new commands to the NLM. When the NLM receives a single command to delete a record, we will make the NLM behave as if it received both the find and delete commands. When the NLM receives a single command to update a record, we will make the NLM behave as if it received the find, delete, and add commands.
This last adjustment balances the load among the client, server, and network to achieve the maximum work possible. This has been a very simple example using a very simple application but the concepts of load balancing and network optimization are still applicable, even to complex applications.
Figure 7: A well balanced application.
Introducing the Server's Local IntranetWare OS
The NetWare operating system is a 32-bit, multitasking operating system. When you launch SERVER.EXE from the DOS partition on a server's hard disk, SERVER.EXE spawns a loader and an NLM called SERVER.NLM into the server's extended memory. SERVER.NLM is the NetWare operating system.
Figure 8: Server.NLM is the server operating system.
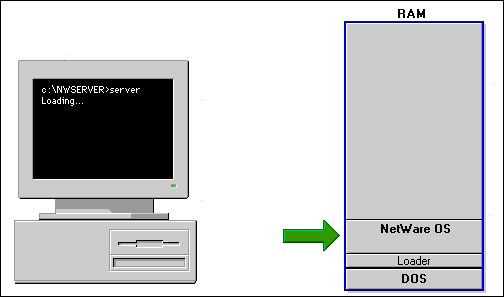
Figure 9: NetWare threads are managed by the local server OS.
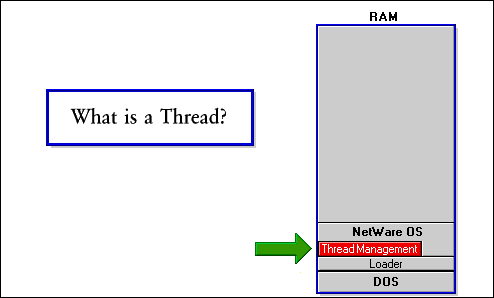
Thread management code is a very important part of the OS. Thread management is implemented by a set of NetWare routines used by regular NLMs and the operating system to manage threads. But what is a thread?
A thread is a path of program execution that can be suspended and then reactivated at the point of suspension.
You see here flowcharts depicting program flow for two very simple NLMs. Let's imagine that these NLMs have lots of clients and no shortage of work to do. In C programming, we are used to routines having a beginning and an end with lots of potential paths, in this case three, in between. Each path that actually gets run is called a thread.
Figure 10: A blocking thread will not stop other threads from running.
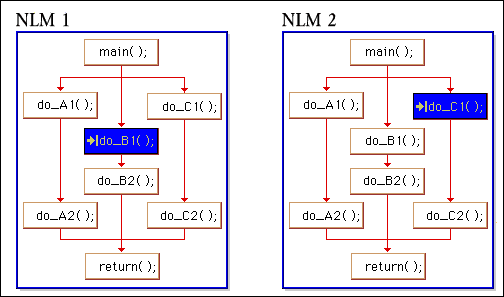
In some operating systems, if one of the threads encounters a delay of some sort (reading from a disk for example) other threads are forced to wait their turn. The thread causing this delay is said to have blocked or gone to sleep. The arrow with the opposing line symbol that you see here is meant to indicate this sleeping or blocked condition. Calls which cause threads to sleep can be frequent in any operating system.
NetWare is a cooperative multitasking operating system, which means it doesn't allow sleeping to delay other threads. Instead, NetWare allows threads to switch control of CPU time among themselves.
A thread can be put to sleep by calling a thread management routine to put itself to sleep, by terminating itself, or by accessing a resource for which it must wait, such as a file, causing the system to put it to sleep. When a thread goes to sleep, NetWare will perform a switching operation to give CPU time to another thread.
When NetWare's thread management routines perform this switching operation, NetWare will preserve the now sleeping thread's necessary processor and OS state (also called its context). NetWare will then set up another thread's context, set the program counter to point to the appropriate instruction in the soon-to-be-activated thread, and then give the other thread CPU time.
While a thread in an NLM is sleeping, other threads in other NLMs and other threads in the sleeping thread's NLM can still be run.
When a sleeping thread wakes up, the thread management routines set up its context and give it CPU time so that it can continue execution.
Every NLM that is run has just one context, as shown here for the NetWare operating system NLM. Every thread that is run must have a process control block (PCB), located in its NLM's context. An NLM's context will have one PCB for each of its threads.
Figure 11: An OS context contains minimum info needed for the OS to manage it's thread.
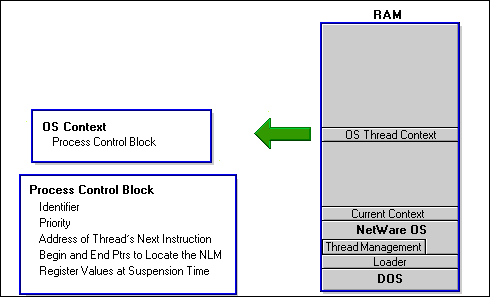
PCBs have just enough context information for the thread management routines to be able to manage all threads waiting for CPU time. PCBs typically provide a unique identifier for the thread, a priority, the address of the next instruction to be executed after the thread wakes up, pointers to the NLM's memory location, and the values of relevant processor registers at the time of suspension.
Before any thread receives CPU time, the thread management routines set the current context to the relevant values of the thread's context.
For example, the NetWare OS has a thread that receives CPU time periodically to monitor the console for input. When a load command is received, the loader is invoked to load the NLM.
An NLM is composed of two main sections: the first section contains the NLM header, which is processed by the loader, and the second section which contains the NLM's data and executable code.
Figure 12: Most AutoLoad lists contain an entry for the CLIB NLM.
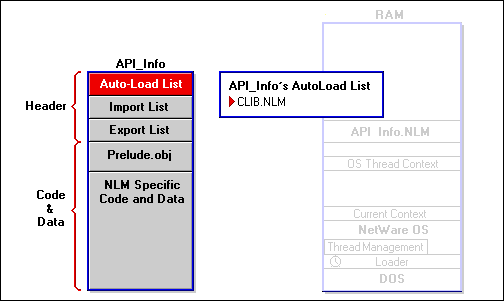
The NLM header consists of three main parts:
the autoload list
the import list
the export list
These lists are composed by the programmer during the NLM build process.
The autoload list is a list of the prerequisite NLMs that the loader will load before continuing to process the header. For example, the autoload list for API_Info contains a reference to an NLM called CLIB.
The loader loads CLIB before continuing to process API_Info's header.
After CLIB has been loaded, the loader begins to process the CLIB header. To simplify the explanation, we will show just one NLM, STREAMS, in CLIB's autoload list. After loading STREAMS and any other prerequisite NLMs, the loader processes the next part of CLIB's header, the import list.
Figure 13: An Import List provides offsets to an NLM's references to routines in other NLMs.
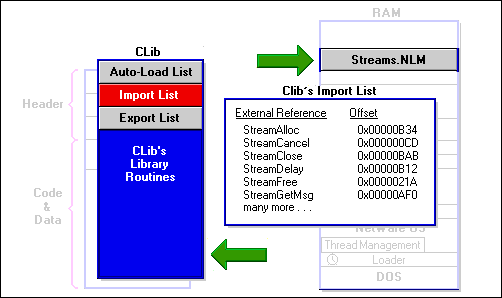
The import list is a list of all the external routine references and their offsets in the NLM's code. In the example, CLIB makes calls to the routines in STREAMS, among others.
The last part of the header processed by the loader is the export list.
Figure 14: An NLM's Export List provides routine offsets to other NLMs.
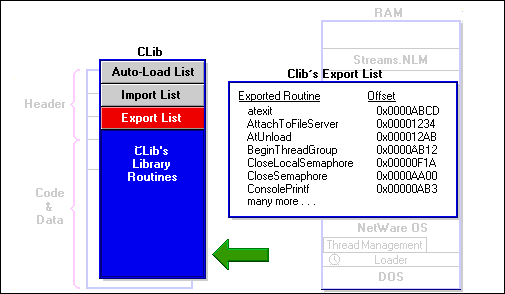
An NLM's export list contains the names and locations of all the NLM's routines that are to be made available for external reference by other NLMs. CLIB is a library NLM. A library NLM's main purpose is to provide functionality to other NLMs. Therefore, CLIB contains a large number of exported routines.
The CLIB library is extremely important because it contains the most basic and commonly used NetWare routines. Other NLMs, such as API_Info, include the CLIB library in their autoload list so that they can access the NetWare calls that they need.
The loader will not allow a library NLM to be loaded more than once. The loader maintains a table of every NLM's exported routines and calculates their locations in memory by adding the given offset to the load address of the NLM.
Initially, newly loaded NLMs have placeholders embedded in their code at the location of each external reference. When the loader processes an NLM's import list, it uses the offset of each external reference from the NLM's import list to locate the external reference placeholders.
Figure 15: The Loader keeps track of exported routines for all loaded NLMs.
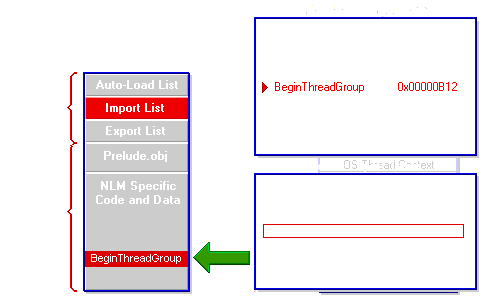
The loader then accesses the exported routine table to obtain the addresses of the routines loaded in memory and replaces the placeholders in the NLM's code with those addresses.
Every call in every import list has to be found in the exported routine table or the loader will abandon loading both the prerequisite NLMs and the NLM the user originally attempted to load.
API_Info's export list is empty. If we wanted to use multiple NLMs for the API_Info service, we would list some of API_Info NLM's calls in the export list.
When the loader has finished loading API_Info and all its prerequisite NLMs, the thread management routines give CPU time to an OS thread to allocate a context for API_Info.
Figure 16: By default, all NLMs are initialized with OS context.
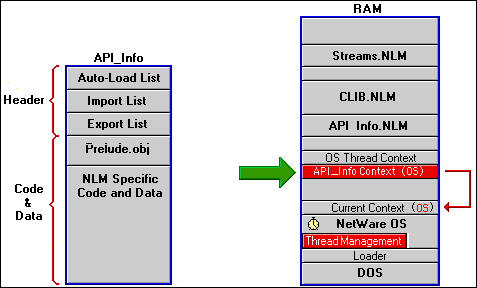
After the context has been created, the thread management routines spawn a default thread for the API_Info prelude and main routine, and pass control to it. In this way, API_Info begins running its prelude code. PRELUDE.OBJ is provided for you in the SDK. You need to link your NLM with PRELUDE.OBJ so that common NLM initialization tasks can be performed automatically.
One of the things that the prelude routines do is solve a context problem.
Initially, the newly created context for an NLM is set to OS thread context which is, as you recall, simply a PCB, just enough for the thread management routines to begin running API_Infos code.
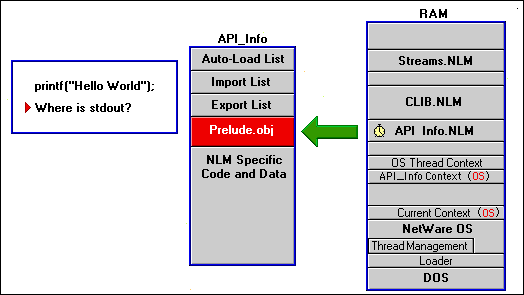
Suppose you want one of the threads in your NLM to use printf. Printf is an ANSI call that sends output to a buffer, called stdout, which should already be set up. Before you make a call to anything that requires a system state like this, you should ask yourself, does the current context have access to that state. Well does it have access?
In the example shown in the following figure, the current context is set to that of the new API_Info context, which is an OS thread context, nothing more than a PCB. Well, does the PCB have a reference to stdout? The answer is no. We can't use printf unless we can use a context that has a reference to stdout.
Figure 17: PRELUDE.OBJ is provided by the SDK.
Introducing CLIB Context
Here is a high-level view of CLIB context. CLIB context is used by most NLMs because it gives NLMs the system state that they need to make NetWare, ANSI, and other types of calls.
Figure 18: A CLIB context contains much more info than an OS context.
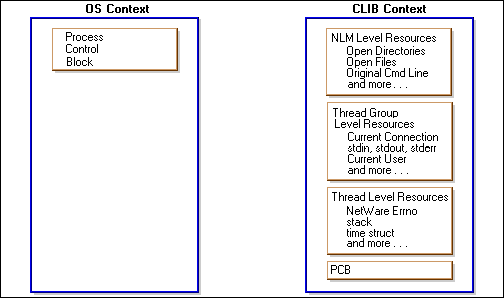
Let's compare CLIB context with OS context. Naturally, they both have a PCB, because all threads need to have a PCB in order to provide the thread management routines with the information they need to manage threads.
But CLIB context also has thread level context resources, thread group level context resources, and NLM level context resources.
The NLM level has resources such as the NLM's open directories and files, the original command line used to launch the NLM, and many more.
The thread group level has resources such as the current connection, stdin, stdout and stderr, the current user ID, and many more.
The thread level has resources such as a NetWare error number variable, a stack given to the thread when it was created, a time variable, and of course, many more.
And you have already seen the contents of the PCB.
As was mentioned earlier, NetWare is a multithreaded operating system. Shown in the following figure is an NLM with three sets of thread level context resources, one set per thread.
Figure 19: NLM Context for three threads in two thread groups.
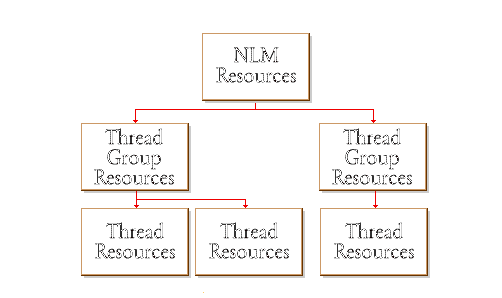
Notice that each set has a parent, called a thread group. The thread groups are grouped within an NLM.
Thread resources are not actual threads; they simply provide the context resources for threads.
NetWare provides you with thread groups to help you organize your thread context resources. You could, for example, create a new thread group for each of your clients while using the threads within each thread group to manage the appropriate client's tasks.
A thread group is really just an identification device to help manage thread context resources. However, every thread in an NLM must belong to a thread group so that its resources will be properly organized.
When an NLM is loaded, it is allocated one context. However, if the NLM's context is a CLIB context, then the context has three levels of scope.
Resources at the NLM resource level are accessable by all the threads in the NLM no matter what thread group the threads are in.
When we say a resource is accessible, what we really mean is that system calls such as printf can access the context resources, but not your code. Your code cannot do direct assignments and the like with these context resources, although CLIB routines can be used to get or set some of them.
Resources, such as stdout, at the thread group level, are available to all the threads in that thread group but not to threads from other thread groups. Each thread group will have its own thread group level context resources in the NLM's context.
Resources at the thread level are available only to the thread. Each thread will have its own thread level context esources in the NLM's context.
That brings us back to the question, where is stdout? Well, if you set current context to a context that has been initialized for CLIB, the answer is, right where it should be.
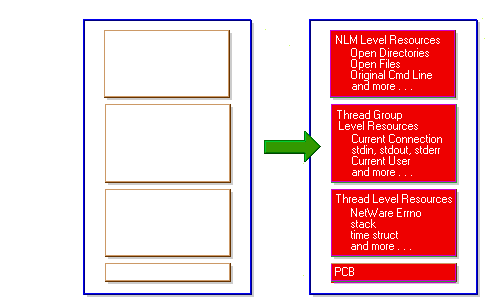
This is why the prelude code that is linked with NLMs initializes the NLM's context for CLIB- so that it can make NetWare and ANSI calls.
Figure 20: An NLM's Prelude code changes it's context from OS to CLIB.
Communicating Over the Network
Most networked computers communicate by modulating their data into electrical signals and transmitting those signals to each other over wires.
These messages are often viewed in their digital form.
Figure 21: The main components of a packet.
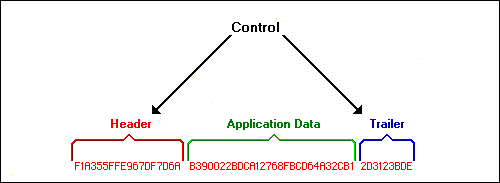
Each message, called a packet, is composed of three main sections: the header, the data, and the trailer.
The header and trailer are used to control and preserve the integrity of the data portion. The data portion is the true message. Like a letter's envelope, the header and trailer are discarded after the message has been received.
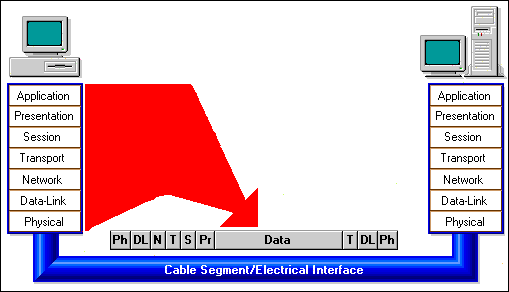
The Open Systems Interconnection or OSI Reference model is commonly used to describe the network communication process.
Figure 22: OSI Network Communications Model.
The OSI Reference model has seven layers. Each layer provides services to the next higher layer and shields that higher layer from the details of how the services of the lower levels are actually implemented.
The Application layer is where network and application functionality interface. In your applications, this layer is composed of the NetWare calls that you make from your client and NLM code.
In the Presentation layer, transmit data received from the Application layer is translated into the network's data format for transmission. For example, data encryption and little and big endian byte ordering translations are often performed at this level. On the receiving side, the Presentation layer translates the data back to its original form for presentation to the Application layer.
The Session layer is responsible for turning communications between computers on and off and for establishing naming and addressing conventions.
At the transmitting end, the Transport layer can break a message down into smaller sequentially numbered chunks. Since smaller messages have a better chance of error-free transmission, this improves the chance that most of the original message will get through without error.
On the receiving side, the sequentally numbered chunks are reassembled. The Transport layers from the receive and send stations interact over the network to resend any missing or damaged chunks.
The Network layer deals with packet addressing and routing. NetWare's IPX protocol and the IP protocol, for example, perform tasks at this level.
The Data-Link layer deals with how transmitting stations gain control of the wire so they can send their messages and how receiving stations check the integrity of the messages once they receive them. Ethernet, ARCnet, and token ring are common implementations of this layer.
The Physical layer handles data modulation on the wire. This layer is mainly concerned with the type of hardware used to transmit the data between stations.
Each layer of the model uses a different part of the header and trailer. As the application's data moves down through the OSI stack, each layer performs its functions and adds its control information to the message.
At the receiving station, the control information is interpreted and acted upon in reverse order. The idea is to encapsulate each layer so that it can provide services to the next higher layer and shield that higher layer from the details of how the services of the lower levels are actually implemented.
Figure 23: Each layer is responsible for generating and interpreting it's own information.
As shown in the following figure, different parts of a message's address are checked at different layers to optimize efficient message processing. Unintended recipients stop processing the message at the Physical layer.
Figure 24: The Internetwork Address is checked at three levels.
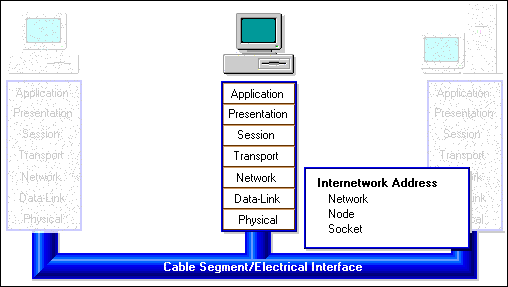
The address used to identify recipients on a local area network (LAN) is commonly called an internetwork address because a LAN is often composed of many smaller networks all hooked together.
The Network portion of the internetwork address identifies the target cable section in the internetwork and is checked at the Network layer.
The Node portion of the internetwork address identifies the intended network interface card on the cable section and is checked at the Physical layer.
A single computer can have many applications or processes which communicate over the network. The Socket portion of the internetwork address identifies the intended application or process in the station and is most often checked at the Session or Transport layer.
When a message is transmitted, each station must check the message's address to determine whether it is the intended recipient. The first check, the node address, is made at the Physical layer. If the node address disagrees with the station's node address, the message is ignored.
If the node address matches, the Network address is checked at the Network layer. Many stations on a network can server as routers. Routers serve as connection points between cable segments on an internetwork.
A station will send messages to a router on the station's cable segment so that the router can forward the messages to the intended recipients on other cable segments.
If a message's Network address disagrees with the station's network address and the station is a router, then the router will use a routing table to determine how to reroute the message.
If the message is intended for the station's cable segment, the message is passed up the stack.
Finally, the socket identification is checked to see if the intended process or application is running on the station. If so, the message is formatted for and presented to its intended recipient.
The OSI Reference model provides general guidelines. Different vendors implement their network communication in different ways.
For example, NetWare allows applications to control how the Application and Presentation layers are implemented.
Figure 25: NetWare functionality.
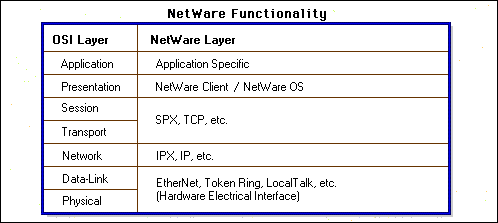
NetWare's SPX protocol is often used to implement the Session and Transport layers, but other protocols, such as TCP, can be used as well.
NetWare's IPX protocol is often used to implement the Network layer, but other protocols, such as IP, can also be used.
At the Data-Link and Physical layers, Ethernet, token ring, and LocalTalk are popular methods used.
In addition, NetWare has the NetWare Core Protocol (NCP) that is always used to implement the distributed contol of stations throughout a NetWare network.
Figure 26: The NCP layer implements distributed control throughout the network.

The remainder of this article will discuss three stages of NLM operation as they pertain to the API_Info NLM:
initialization
the transaction
NLM termination
The following figure reconfigures the diagram used earlier to discuss the OSI Reference model so that it can be used to discuss the NetWare model with API_Info implementing the Application layer.
As you recall from earlier in this article, when SERVER.EXEis executed from DOS, SERVER.NLM is launched in the server's extended memory and becomes the server's local NetWare operating system.
Figure 27: The Application's NLM implements the Application Layer on the server.

Every NLM that is run has just one context, e.g., the operating system NLM. Before any thread receives CPU time, the thread management routines set the current context to the relevant values of the thread's context.
For example, the NetWare OS has a thread that receives CPU time periodically to monitor the console for input. When a LOAD command is received, the loader is invoked to load the NLM.
The autoload list in the API_Info header will cause the CLIB NLM to be loaded. The API_Info prelude code will set API_Info's context to CLIB context.
If any of these concepts seem unfamiliar to you, now would be a good time to review the earlier part of this article.
The code examples that will be shown in this article have been modified for instructional purposes. For example, if a call has parameters which are self-explanatory and not needed for the discussion, the parameters are left out to simplify the explanation.
The API_Info NLM has three routines:
main
API_Info's NCP extension handler
NLM's termination code
Figure 28: The API_Info NLM has three main sections.
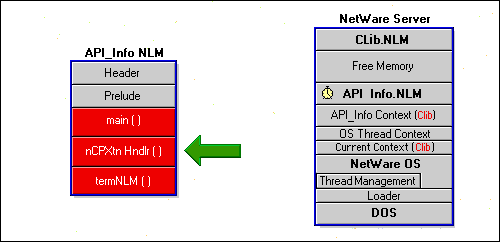
NLM Initialization
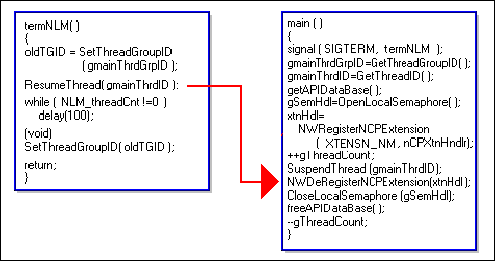
The first call in the main routine is to an ANSI API called signal( ).
The call's parameter is the address of API_Info's NLM termination routine. The NetWare constant SIGTERM will cause the signal routine to register the NLM termination routine to be called by the operating system when the NLM is unloaded. TermNLM( )will then interact with the main( ) routine so that your NLM can terminate gracefully. We will explain later how TermNLM( ) and main( )interact.
Figure 29 API_Info's main( ) routine.
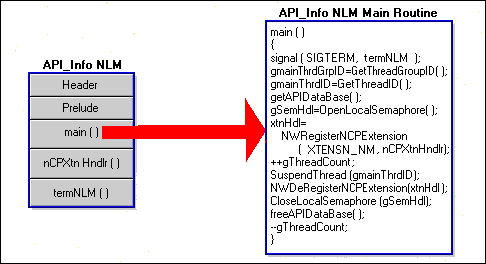
The next call in our NLM's main( ) routine is concerned with the NLM's context. GetThreadGroupID( ) gets an identifier for main's thread group context. Recall that prelude set main up for CLIB context. This thread group identifier will be used later to convert threads using OS context to the CLIB context of our main( )routine so that they can make CLIB calls.
main( )also calls a routine called GetThreadID( ) which returns an identifier to main's thread. Although this call may seem redundant, it isn't,this identifier identifies a thread's PCB only and not its thread level context. This thread identifier will be used as a parameter for two important routines that we will discuss later.
The application-defined routine, getAPIDataBase(), allocates and initializes the databaseused by API_Info.
The NetWare routine, OpenLocalSemaphore(), is used to create a semaphore which will be used to protect the API_Info database and its file. But why would the API_Info database and its file need protection?
The problem is that a multithreaded operating system like NetWare has no direct control over what its threads do and when. This means that while one API_Info client is updating a record in the database another could be deleting the same record. To prevent this from happening, we use semaphores as flags to let each thread know independently if another thread is attempting to access the same resource. (We will discuss much more about protecting shared resources in later articles of this series.)
Next, you need to register your NCP extension handler routine. This handler provides the code that will be executed to satisfy API_Info's client requests. Each client request received will cause a separate thread, running this NCP extension handler, to be spawned. The client side of API_Info will be discussed in greater detail in the last article.
NWRegisterNCPExtension( ) has many parameters. For our purposes, we will focus on the name of the handler, provided by the application defined string constantXTENSN_NM, and the address of NCPXTNHandler( ) in memory. The local NetWare OS provides a unique identifier for the installed handler in its NCP extension lookup table.
The application-defined global variable gThreadCount will be used to keep track of how many API_Info threads are currently alive. Each thread will increment gThreadCount when the thread begins and decrement gThreadCount when the thread ends. main( )increments gThreadCount once to account for its own thread.
SuspendThread( ) is one of two important routines that need main's thread identifier. We obtained this identifier earlier with GetThreadID( ). main( )calls SuspendThread( )to put itself to sleep. It has finished its work for now.
The Transaction
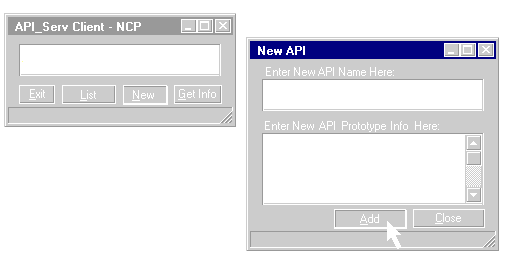
The API_Info service is now available for client use. In this example, the client user will add a new API to the API database. The NCP extension must handle this operation carefully because the API database is a shared resource and other threads created to handle requests from other clients could try to access this resource at the same time.
Figure 30: Windows displayed when adding an API prototype to an API_Info database.
The client side of API_Info calls the NetWare API NWNCPExtensionRequest( ).
You will learn more about this and the other calls the client makes to connect to the service in the last article of this series. This call causes a request to be sent over the network to the server running API_INFO.NLM.
Figure 31: The client side of API_Info call NWNCPExtension Request( ).

On the server side, the NCP extension identifier is found and the NetWare operating system spawns an OS thread for the handler. Since this is an OS thread, the current context is set to OS context.
Among other parameters, the handler receives two buffers, one containing the request data and the other a presized reply buffer. When you use NCP extensions, you don't have to manage buffers as you would with other communication models, unless you want to. Otherwise, you just specify the appropriate buffer sizes and NetWare takes care of the rest.
Since this is a new thread, we must account for it by incrementing the thread count variable.
Next we must make sure that the current context is set to CLIB so that we can make CLIB calls. You can use SetThreadGroupID( ) to do this. SetThreadGroupID( ) receives the identifier for the current context in oldTGID, giving us a way to restore the context when the handler is finished. SetThreadGroupID( ) then sets the current context to the context associated with the gMainThreadGroupID value. Recall that this value was obtained during the initialization portion of the main routine.
Figure 32: Context must be set to CLIB before making CLIB calls.
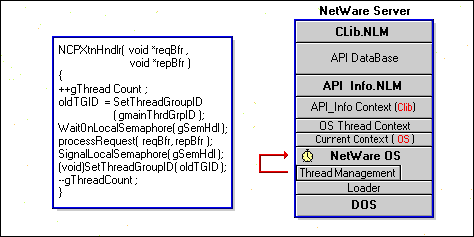
WaitOnLocalSemaphore( ) checks to see if any other threads are currently accessing the API database. If threads are accessing the database, the operating system will put this thread to sleep until the resource becomes available.
The application-defined routine processRequest( ) is the service engine that actually performs the work of the service. The request buffer from the client contains a request code and the data necessary to respond to that request. In this case, the request data will be the new API data to be added to the API database.
The reply buffer will be filled in by processRequest( ). After the transaction is processed, the reply buffer will contain either reply data (if some was requested) or an error string (if a problem was encountered).
Calling SignalLocalSemaphore( ) signals the operating system that this thread is through with the shared resource, in this case, the API database. The operating system will then give time to the next thread waiting to use the resource.
The call to SetThreadGroupID( ) restores the current context to its initial state at the beginning of this handler.
The thread count is decremented just before the thread ends.
NLM Termination
If a thread allocates resources which must be freed, a termination handler must be installed for its NLM. Recall that the first line in main( ), used the signal( ) routine to install TermNLM( ) as API_Info.NLM's termination handler. When API_Info is unloaded, the operating system generates a SIGTERM signal. This signal causes the operating system to spawn an OS thread running API_Info.nlm's termination routine TermNLM( ).
Figure 33: NLMs that allocate resources which must be freed must have a termination routine to free them.
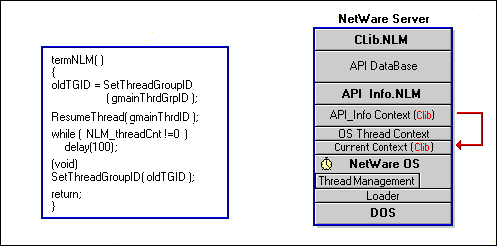
TermNLM( )first uses SetThreadGroupID to set the current context to that of API_Info's main thread group, effectively giving CLIB context to the OS thread running TermNLM.
Next, ResumeThread( ) is called to wake up the main thread so that main( ) can clean up API_Info's shared resources and threads. ResumeThread( ) is the second important routine that needs main's thread identifier that was obtained earlier with GetThreadID( ).
After resuming, main( )deregisters the NCP extension handler for API_Info.
Figure 34: ResumeThreads( ) causes main( ) to resume.
Then main( ) closes the semaphore used to protect the API database. Failure to close a semaphore may cause undesirable consequences after the NLM terminates.
Next, main( ) deallocates the API_Info database and decrements the thread count to reflect the fact that the main thread is ending. Note that in this example, API_Info has no outstanding client requests, so no other API_Info threads exist and threadcount will equal 0.
After control returns to the OS thread running TermNLM( ), a while loop is entered to allow remaining API_Info threads to clean up their resources before they terminate.
In this loop, a NetWare routine called delay( ) is used to put TermNLM to sleep for 100 ticks each time it is called, thereby giving time to other threads. Eventually, time is given to all API_Info threads so that they can terminate and the loop can be ended.
There are no other API_Info threads in existence so TermNLM( ) resets the current context back to the OS context originally given to its OS thread. Failure to do this would, of course, have disastrous results because the OS would attempt to run under CLIB context when TermNLM( ) ends.
During this article, we have discussed:
how an NLM is composed of a header and code.
the NLM header is composed of an autoload list,an import list, and an export list.
that the NLM code section is composed of a preludeprovided by the SDK and your compiled code.
NetWare is a multithreaded operating system that uses cooperative multitasking to manage its threads.
NetWare threads have two kinds of context, OS and CLIB.
CLIB context resources are accessed by NetWare routines called from a thread at three levels: NLM, Thread group, and thread levels.
the seven layers of the Open Systems Interconnection model and how the NetWare communications model compares to it.
that an internetwork address has three parts network, node, and socket.
the three stages of API_Info.NLM operation, initialization, the transaction, and termination.
that shared resources must be protected with semaphores, locks, and so on.
that all NLMs which have threads which allocate resources such as memory and semaphores, must install a termination routine to free the resources.
During the next article we will discuss:
how to extend API_Info to use NDS to enable theuser to acquire an API_Info service on any tree.
about the NDS schema and its constituent parts, how to define attributes, and how to add a new class for API_Infoto a schema.
how a snapin module interacts with NetWare Administrator.
how to write NDS code for an API_Info snapin module that will enable it to respond to messages from the NetWare Administrator application so that users can edit API_Info's NDS attributes using the NetWare Administrator application.
Disclaimer
The origin of this information may be internal or external to Novell. While Novell makes all reasonable efforts to verify this information, Novell does not make explicit or implied claims to its validity.