Introduction to NetWare SMP Architecture and SMP NLM Development
Articles and Tips: article
Developer Support Engineer
Developer Support
01 Jan 1997
Explains the NetWare SMP architecture and demonstrates some basics of writing SMP-enabled applications.
- Introduction
- Terminology
- Architecture
- Sample Code Snippets
- Running PROCHOG.NLM
- SMP APIs
- Optimization
- Source & Utility Files
Introduction
NetWare SMP (Symmetric MultiProcessing) gives you the ability to offload threads to secondary processors, increasing the performance of your application on multi-processor machines.
Knowing when it's a good idea to spin off a thread to another processor and how to manage the locking of critical data on that thread is very important. Developing well-written SMP applications on any platform requires a good knowledge of the architecture, of your application, and how it will be used. It may even take experimenting with some what-if scenarios in an attempt to balance the number of threads and lock granularity for optimum performance.
This article will help you understand the NetWare SMP architecture and will demonstrate some basics of writing SMP Enabled applications.
NetWare SMP is not new to NetWare 4.11; it has been offered by several OEMs for NetWare 4.10 for about a year. However, several enhancements and fixes have been made to SMP in NetWare 4.11 resulting in better performance and greater reliability.
NetWare SMP enables threads to be offloaded to secondary processors, allowing the NetWare Operating System to utilize the primary processor, processor 0, for its own purposes. It also provides you with tools to protect global data from being corrupted if multiple processors are accessing the same data simultaneously.
To better understand how to write NetWare SMP applications, we need to understand some terminology, then discuss the architecture of NetWare SMP. Finally, we'll review some code which demonstrates some basics of a simple SMP application.
Terminology
The following table briefly describes a few terms that we will use throughout this article. Some term descriptions may seem vague at first, but will make more sense when you begin to understand the architecture of NetWare SMP.
|
Term
|
Description
|
|
SMP Unsafe |
Anapplication or function which cannot runsimultaneously on multiple processors withoutpossible corruption of global data occurring.To be safe, the loader assumes that all functionsit is exporting are "unsafe" unless specificallytold they are safe by the NLM in the XDCDataarea. This is discussed later in the MarshallingQ & A section. |
|
SMP Safe |
Refersto a function or application whose globaldata would be safe from corruption if itwere to run simultaneously on multiple processors.This is accomplished with the SMP synchronization APIs. |
|
Multithreaded |
Applicationsthat distribute their work into logical separateunits (threads), able to access shared memoryand resources. In SMP these threads can runsimultaneously on multiple processors. |
|
SMP Aware/SMP Enabled |
A function or application that is SMP Safe and multithreaded. |
|
Thread Migration |
Whena thread is moved from the NetWare run queue serviced by processor 0 (primary processor),to the SMP run queue serviced by processors 1 - n (secondary processors) and vice versa. |
|
Marshalling |
Theprocess by which SMP Unsafe functions are still able to be called by SMP Enabled applicationsby forcing the unsafe function to be executed on processor 0 only. |
|
Load Balancing |
Balancingthe thread load among all processors. |
Architecture
SMP Modules
In order to write a well-tuned SMP application, it is critical to understand some architecture basics of NetWare SMP.
SMP on NetWare 4.11 is made possible by several modules that interact with the base NetWare OS to provide SMP services. If specified during NetWare installation, these modules were placed in STARTUP.NCF automatically.
PSM (Platform Support Module). This module knows how to interface with the specific SMP hardware. Intel has developed a specification which OEMs can follow when developing their hardware; or OEMs can develop their own specs. NetWare 4.11 ships with the following PSMs:
MPS14.PSM (Intel MP Spec. v1.4)
CBUS_II.PSM (Corollary)
CPQSMP.PSM (Compaq)
NFPSM.PSM (Netframe)
TRI_SMP.PSM (Tricord)
SMP.NLM. The SMP environment (scheduler, etc.).
MPDRIVER.NLM. Initializes the processors and starts a worker thread on each processor's run queue.
SMP Environment
One other utility that may prove helpful in troubleshooting is MPDETECT.NLM. This NLM will attempt to discover the type of SMP hardware and the number of CPUs in your system.
Once the appropriate SMP modules have been loaded, the SMP environment similar to Figure 1 is active.
Figure 1: SMP Environment.
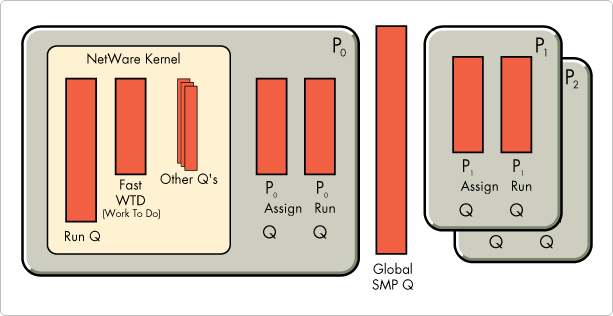
The NetWare kernel is active in its entirety on Processor 0 (P0). Also active on P0 are queues specific to SMP (P0's Assign and Run queue). All other processors also have their respective Assign and Run queues.
The Global SMP queue is used as a storage facility for threads that are currently unassigned to a particular processor. At each context switch, the scheduler will look at this "unassigned" queue and assign threads to a processor that can handle the load.
Each processor has an assigned queue which we will not discuss in this article. Its use is limited in this version of NetWare SMP.
Thread Behavior
All threads begin in the NetWare OS run queue on P0. A call to NWSMPThreadToMP() will place the current thread on the Global SMP Queue, ready for assignment by the scheduler. The scheduler looks at the number of current threads in each processor's run queue, as well as the utilization of the processor. If it determines that a processor can handle the additional thread, it will place the thread on the processor's run queue. This thread will remain in the same processor's run queue until one of the following occurs:
It has completed
It gets offloaded because of excessive processor load
It is explicitly migrated back to the NetWare run queue using NWSMPThreadToNetWare()
Marshalling
As you will recall from the terminology table above, marshalling refers to the process by which SMP Unsafe functions are still able to be called by SMP Enabled applications by forcing them to be executed on processor 0 only. In other words, if a thread is executing on Pn, and it calls a function that is deemed SMP Unsafe, the thread on Pn's run queue will be marked "migrating," then the SMP Unsafe function is scheduled on the NetWare Fast Work To Do queue for near immediate processing on P0. Once this unsafe work has completed, the thread in Pn's run queue will be marked runnable again.
Marshalling Q&A & XDC Data
Q: How does SMP know that a function is SMP Unsafe?
A: It is actually handled by the loader at the time a function is exported. The loader will look into an NLMs XDCData area for a list of SMP Safe functions. If a function to be exported is not found in this area, the loader places a special Marshalling layer around the function, so when the function is called, it will migrate to NetWare on P0before execution.
Q: How do I place function names in the XDCData area of an NLM to assure that the loader knows they are SMP Safe?
A: Depending on your development environment, there is a linker switch that allows you to specify the name of an XDCData file. This file is generated by a DOS utility called SMPRPC.EXE, which simply takes a text file with a list of SMP Safe functions that you are exporting. The format of this text file is one function name per line with no delimiters. Or you can tell SMPRPC, with the -a switch, to create an XDCData file which states that all exported functions are SMP Safe. The SMPPRC utility is in the file TSMP1.EXE and can be found on the URL ftp://ftp.novell.com/pub/ndevsup/05/tsmp1.exe.
Manual Marshalling
There are two new console commands that allow you to manually marshall and unmarshall functions. These commands should be used strictly for testing purposes since marshalling is taken care of by the loader as discussed above. The commands are as follows:
marshall <symbol>
unmarshall <symbol>
It is not a good idea to manually unmarshall a function unless you know it is SMP Safe.
These commands can also be used as a tool to verify if an exported function is marshalled. If you attempt to marshall a function that is already marshalled, it will issue a message to that effect.
Sample Code Snippets
The following sample code snippets are from prochog.c, available in its entirety on the various Novell electronic distribution channels as XSMP3.EXE.
Prochog is a simple SMP application demonstrating what it takes to make an SMP Enabled NLM (SMP Safe and multithreaded). Prochog.NLM takes an argument indicating the number of threads it will start on secondary processors. These threads simply count to random large numbers - utilizing the secondary processors. It displays the number of times per second all of the counting threads are executed. Since there is not an API available yet to retrieve utilization on secondary processors, you must go to Monitor -> Multiprocessor Information to check utilization. In Monitor you can also see thread and mutex information.
Migrating to MP
The entire reason why an SMP application is created is to take advantage of secondary processors. This is accomplished with NWSMPThreadToMP() which migrates the current thread to the Global SMP Run Queue. This is illustrated in Code Sample 1.
Code Sample 1: Thread Migration to SMP.
**Start the new thread from main BeginThread(StartHogThread,NULL,0,NULL); . . . **The new StartHog thread migrates itself to MP /***************** * Start a Busy Thread on MP - Called by BeginThread *****************/ void StartHogThread(void *arg) { long I; long bignumber; /* migrate thread to mp */ NWSMPThreadToMP(); . . .Mutex Locks
A Mutex (MUTually EXclusive) lock is an SMP API that allows mutually exclusive access to specific pieces of code which should not be executed on multiple processors at once, resulting in protected shared data. Prochog allocates one (1) mutex and is used whenever the global variable NLM_threadCnt is modified.
Lock Granularity
In the following example, prochog uses the mutex only during modification of the variable. You could however lock larger sections of the code if several variables were being updated. This is what is knows as lock granularity. It is your job to determine if you want to lock in many places, once for each variable (fine locks), or lock larger sections of code (course locks). Each method has its pros and cons. Many fine locks cause overhead, whereas course locks only allow one processor at a time to execute the code segment.
To Lock or Not To Lock
Since locks translate into overhead, keep in mind that some global data may not be critical. For example, if you are gathering statistics it may not matter if a counter is off by 1 in 1000 or 2000 updates. In prochog, the variable LoopCntr is global, and is being updated by multiple threads on multiple processors - however it is not critical data, so I chose not to use locks to protect it.
Code Sample 2: Mutex locks.
/**************
* global variables
**************/
int NLM_threadCnt = 0; /* counter to keep track of how many threads are running*/
mutex_t hogmutex; /* mutex */
.
.
.
**Mutex is allocated in main
hogmutex = NWSMPMutexSleepAlloc("ProcHog");
.
.
.
** Mutex is destroyed just before main terminates
NWSMPMutexDestroy(hogmutex);
.
.
.
** Mutex is used in threads running on secondary processors
/**************
* lock to update global var
**************/
NWSMPMutexLock(hogmutex);
NLM_threadCnt++;
NWSMPMutexUnlock(hogmutex);
/* make a busy loop by counting to some random number
* and keep a counter of how many times this loop is run.
* go until NLM_exiting is set to true by NLM_SignalHandler or main */
while(!NLM_exiting) {
bignumber = rand() * 5;
for(I=0;i<bignumber;i++);
LoopCntr++; /* no mutex is used because accuracy is not critical */
ThreadSwitchWithDelay();
}
Migrating to NetWare
Migrating a thread currently executing on a secondary processor, to NetWare (processor 0) is useful when you are about to do many successive disk or LAN I/O operations. Since these I/O operations must be executed on processor 0, by forcing this migration to NetWare before this series of I/O operations begins, it circumvents the marshalling process from doing it for you for each individual operation, thus avoiding the thread "ping pong" effect going back and forth from NetWare to SMP. Migrating to NetWare is done with NWSMPThreadToNetWare().
Once the I/O sequence has completed, simply migrate your thread back to MP using NWSMPThreadToMP().
Running PROCHOG.NLM
Because of the architecture of modular CLIB in NetWare 4.11, even if the SMP modules are not loaded, any SMP application will still load and run. Because of this, you can experiment with Prochog on a uni processor machine, or comment out the SMP modules in STARTUP.NCF and run your SMP machine in uni processor mode. By doing this, you will be able to compare how Prochog runs on one processor vs. multiple processors.
Another interesting test is to reduce the number of currently active processors. Try unloading MPDRIVER, which reduces the number of active processors to 1 (processor 0). You can then:
LOAD MPDRIVERn
where n is the processor number to activate (1 - N).
By doing this, you can get an idea of how NetWare SMP scales and how each processor makes a difference in the amount of "work" Prochog can accomplish.
Note: If the SMP modules are loaded there must be at least one secondary processor active or Prochog cannot start any threads.
Prochog also allows you to specify, as a parameter, the number of threads to begin. The default is 10 threads. Try different thread counts to see where the (performance/# of threads) curve begins to flatten or drop.
SMP APIs
The following table is a summary of most of the SMP APIs prototyped in nwsmp.h and listed in threads.imp. These APIs are discussed in detail in the SDK documentation.
|
Category
|
APIs
|
|
Thread Migration & Misc. |
voidNWSMPThreadToMP();void NWSMPThreadToNetWare();nuint32NWNumberOfRegisteredProcessors();nuint32 NWSMPIsAvailable(); |
|
MutexLocks For exclusive access |
mutex_tNWSMPMutexSleepAlloc(char *name);nuint32NWSMPMutexLock(mutex_t);nuint32 NWSMPMutexTryLock(mutex_t);nuint32NWSMPMutexUnlock(mutex_t);nuint32 NWSMPMutexDestroy(mutex_t); Also available are recursive Mutex locks which allow the locks to be applied recursivelyto the same area. These APIs are identical to the ones listed above except they haveR before Mutex, i.e., NWSMPRMutexLock |
|
Read/Write Locks Multiple reader /Single writer |
rwlock_tNWSMPRWLockAlloc(char *name);nuint32 NWSMPRWWriteLock(rwlock_t);nuint32NWSMPRWReadLock(rwlock_t);nuint32 NWSMPRWTryWriteLock(rwlock_t);nuint32NWSMPRWTryReadLock(rwlock_t);nuint32 NWSMPRWLockDestroy(rwlock_t); |
|
Condition Locks Threads wait for a condition to be met. Used with a mutex lock. |
cond_t NWSMPCondAlloc(char *name);nuint32 NWSMPCondWait(cond_t, mutex_t);nuint32 NWSMPCondBroadcast(cond_t);nuint32NWSMPCondSignal(cond_t);nuint32 NWSMPCondDestroy(cond_t); |
|
Barrier Locks Define a rendezvous point for threads |
barrier_tNWSMPBarrierAlloc(long count, char *name);nuint32 NWSMPBarrierWait(barrier_t);nuint32 NWSMPBarrierDestroy(barrier_t); |
Mutex vs. Spin Locks
Also available, but not mentioned in the API table, are Spin Locks. This lock type was not mentioned because they should be avoided. When waiting on a Mutex lock, it will busy spin for a short period of time in case the lock becomes available almost immediately. If the lock is still not available, the Mutex lock will sleep. This is why Mutex locks are referred to as "adaptive."
Spin locks however, will busy spin until the lock is available, not allowing anything else to execute on the processor. Spin locks are used only when you know the lock wait will be very short, but as a general rule, try to avoid them.
Optimization
The following is a summary of some things to watch out for and to keep in mind when developing SMP applications.
Think Parallel
When designing and coding, "think parallel." Always keep in mind that this code could be executing at the same time on multiple processors, accessing the same areas in memory or cache. Protect the data accordingly, and watch out for race conditions.
Lock only when Necessary
Only use locks when they are absolutely necessary. If you are gathering statistics, and the numbers don't need to be absolutely accurate, don't use locks.
Balance Fine and Coarse Locks
Getting a lock takes overhead, so if you are updating a structure or multiple structures in the same block of code, it may be best to place a lock before the updates, and unlock after all updates are complete. Bear in mind that coarse locks of this nature do prevent parallel processing of the code, but it may be worth it in some situations.
Localize Data To The Thread If Possible
Minimize the use of global data when possible. Let's say one thread accesses a piece of global data causing the data to be placed in that processor's (P1) cache. If another thread on another processor (P2) modifies that same data, it causes cache invalidation of P1's cache, slowing the next access to that data for P1.
In reality, global data is necessary in many cases, but keep in mind when you are coding that if you can avoid it, it may eliminate cache invalidation resulting in cache misses which can have an impact on performance.
Source & Utility Files
The SMPPRC utility to generate the XDCData file used to tell the loader that exported functions are SMP Safe is in the file TSMP1.EXE. The sample code, prochog.c, discussed in this article is found in file XSMP3.EXE.
STATS.NLM is a utility that reports various statistics and may be useful in optimizing your SMP applications. It is contained in a file called TMISC1.EXE.
All three files can be found on the URL ftp://ftp.novell.com/pub/ndevsup/05.
* Originally published in Novell AppNotes
Disclaimer
The origin of this information may be internal or external to Novell. While Novell makes all reasonable efforts to verify this information, Novell does not make explicit or implied claims to its validity.