An Object-Oriented Approach to Modeling Information Content
Articles and Tips: article
Senior Research Engineer
Developer Information
JAY M. JOHNSON
Software Engineer
Electronic Support
01 Oct 1996
This article is the second in a series covering an object-oriented approach to modeling information content-the sample problem domain used to this series of articles. The first article described the process of seeing a problem domain in terms of objects. This article moves forward with a discussion of problem diagnosis and resolution which serve as an example from which to derive a content model. These concepts are applied in the continued design and construction a class hierarchy. Sample code is provided.
- Introduction
- Information Consumption
- Diagnostic Information Object
- Diagnostic Content
- Descriptors and Indexes
- Schema
- Class Hierarchies
- Contracts, Services, and Other Behaviors
- Bibliography
Introduction
The first article in this series [1] suggested that modeling information consumption is the initial step in modeling information content. The principle here is simple: To build a hammer, nails (among other things) must be clearly understood; otherwise, design and implementation may yield a pair of pliers, a flashlight, or a toothbrush.
For the problem domain of information management within a technical publications operation, only one kind of information consumption is modeled in this article: Problem diagnosis and resolution. This model, or variations of it, can apply to other kinds of information consumption such as product installation, product upgrade, various stages of product use, and other activities on which the output of a technical publications process may focus. Problem diagnosis and resolution serves as an example from which to derive a content model for the information flowing in the process described in the first article in this series.
A problem, as the term is used in this article, is defined as a perceived incongruity between symptoms belonging to a desired condition and symptoms belonging to a perceived condition.
Information Consumption
Figure 1 presents a State Diagram [2] of a generic view of problem diagnosis. The diagram, for example, might apply equally to starting a car or to asking a computer system for a list of files in a directory. An explanation of the diagnostic process is provided here as the basis for the domain expertise required in modeling diagnostic information. Note that the states in Figure 1 model a user's perception of system condition. The proposed definition of problem thus confines a problem's existence to the user's perception.
Figure 1: Simple diagnostic scenario.
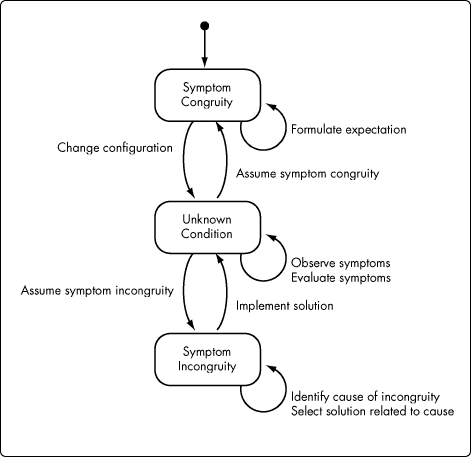
Starting a car: The scenario begins at the filled-in circle near the top of the diagram. The Symptom Congruity state is a state at which two sets of systems match:
Symptoms indicating the condition of the context
Symptoms indicating the desired condition ofthe context
"The context" refers to a system involving a user or agent (e.g., an automobile and a driver, a computer system and a user). "Symptoms" refers to indicators of the condition of a context (e.g., the whir of a starter motor indicates that the starter motor is running, the absence of the starter motor's whir indicates that the starter motor is not running).
At the Symptom Congruity state, perceived symptoms match expected, or desired, symptoms. For example, a person seated in the driver's seat of an automobile has not yet turned the key in the ignition. The fact that no sound is heard from either the starter motor or the engine is consistent with the person's expectation.
The event labeled "formulate expectation" would, in the case of starting a car, pertain to the driver's expectation that upon turning the key in the ignition the sound of the starter motor will be heard. Formulating an expectation does not move the user's perception to another state because the user has not yet acted on the expectation. By turning the key in the ignition, however, the person changes the configuration of the context. Changing configuration is here defined as changing the manner in which system components relate to each other. Such a change moves the person's perception of system condition to Unknown Condition.
At Unknown Condition, the driver evaluates symptoms (e.g., engine sounds like it's turning over, only a clicking is heard when the key is turned in the ignition, no clicking is heard, etc.). Having evaluated whatever symptoms were experienced, the driver either assumes that perceived symptoms match expected symptoms, or that the two sets of symptoms do not match. If expected symptoms do not match perceived symptoms, the person's perception of system condition moves to Symptom Incongruity where the person attempts to identify the cause of the disparity between perceived and anticipated symptoms (e.g., battery is dead, car is out of gas, etc.). Once a cause is selected, or hypothesized, the person chooses a solution from the solutions associated with a suspected cause. Having selected a solution, the driver implements it, which changes system configuration and moves the system to Unknown Condition. The scenario then repeats itself.
Directory listing of files: The cursor is at a system prompt. The user wants to know whether a particular file is in the default directory. The user's expectation is that by typing the appropriate command name at the prompt and pressing <Enter< a list of files will appear on the screen.
The user changes the configuration of the system by typing the command name and pressing <Enter<. (Using "configuration" in this sense may unsettle readers who think of configuration as the amalgam of hardware and software products constituting a system. From such a point of view, typing a command and pressing <Enter< would hardly equate to installing an OS upgrade or adding a tape backup unit to the system. Nevertheless, we've defined configuration as the relationship of system components. This definition includes what is typically thought of as configuration as well as the user's presence in the system.)
At Unknown Condition, the user evaluates symptoms apparently resulting from the action taken. If a list of files appears, the user assumes that command execution succeeded and the user's perception of system condition moves back to Symptom Congruity.
If a list of files does not appear, the user's perception moves to Symptom Incongruity where various causes might be considered, such as:
Command syntax was violated.
The directory contains so many files that a list cannot be returned as quickly as expected.
Symptom Congruity might well be decomposed into substates and events. The process of identifying a cause, for example, is not necessarily simple. For our purposes, however, it is sufficient to indicate that a cause must be hypothesized and a solution, associated with that cause, selected for implementation.
Information to be used in the kind of process presented in Figure 1 should be organized to facilitate that process. If, for example, symptoms are to be evaluated, the person or agent performing the evaluation must have descriptions of symptoms. If a solution is to be selected from solutions associated with a cause, cause and solution must have at least a one-to-many relationship and possibly a many-to-many relationship. With this in mind, we now consider an information object designed to facilitate the kind of diagnostic process presented in Figure 1.
Diagnostic Information Object
Figure 2 labels events (from Figure 1) that require the kind of diagnostic information just described. The following descriptions refer to labels in Figure 2.
Symptom Congruity
Formulate expectation-- The term "expectation" refers to anticipated symptoms. A description of those symptoms constitutes information.
Change configuration -- Information associated with this event describes what happened, or what was done, that changed the relationship of elements of the system.
Unknown Condition
Assume symptom congruity -- This event, for our purpose, has no information associated with it because none is required for its completion. The event is analogous to Assume symptom incongruity. These two events follow upon other events in which required information has been evaluated.
Assume symptom incongruity -- See Assume symptom congruity.
Observe symptoms -- This event represents the perception of symptoms resulting from either change configuration or implement solution. As the result of either of the two foregoing events, the information collected as part of the Observe symptoms event constitutes a description of system condition.
Evaluate symptoms -- This event requires information about anticipated symptoms as well as actual, or perceived, symptoms. Thus, two information items (or three, depending upon how information is modeled) are needed at this event: Information resulting from Observe symptoms, and information resulting from Formulate expectation and Change configuration.
Symptom Incongruity
Implement solution -- This event requires the description of a solution.
Identify cause of incongruity -- The description of a cause is assumed.
Select solution related to cause -- A relationship exists between cause and solution.
The information required in our generic model of the diagnostic process constitutes what we choose to call the diagnostic content of an information item.
Figure 2: Information required for events in diagnostic process.
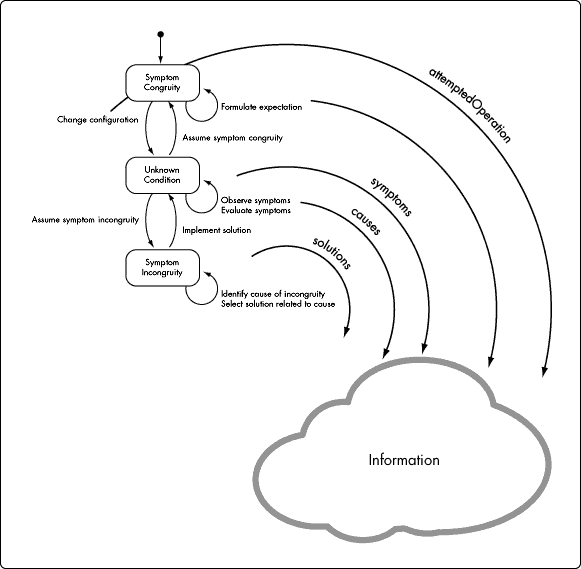
Diagnostic Content
A diagnostic information object suitable for the process described in Figure 1 has at least the following attributes:
Attempted operation: This attribute describes what happened to change the condition or configuration of a system. This attribute also describes desired symptoms, or what was being attempted when a problem was perceived. Information about attempted operation would be used in change configuration, implement solution, and evaluate symptoms events appearing in Figure 1.
Problem symptoms: The information object's problem symptoms attribute contains a textual description of symptoms perceived by the user/agent as incongruent with symptoms described in attempted Operation. This information is used at Unknown Condition in order to evaluate symptoms.
Causes: The causeis a textual description of the reason for incongruity between attempted operation and problem symptoms. Cause information is used at Symptom Incongruity.
Solution: This attribute describes what to do to correct the perceived incongruity between an attempted operation and problem symptoms. Solution information is used at Symptom Incongruity.
Figure 3 illustrates an implementation of the foregoing attributes as text. In Figure 3, each attribute of the memory-resident object is derived from a text value stored in the database table from which the memory-resident object is constituted. In Figure 3, and in the figures that follow, the design of the information object takes shape as though the design were being formulated. We anticipate that such a presentation reflects the kind of iteration typical of design activity, and facilitates an understanding of the finished product.
Note that in Figure 1, Symptom Incongruity has an associated action that we've named select solution related to cause. We intend that a cause can have more than one solution (i.e., that a one-to-many relationship exists between cause and solution). The implementation described in Figure 3 can accommodate the anticipated relationship between cause and solution; however, to do so the solution text would have to contain a description of all the solutions relating to a particular cause.
Figure 3: Information object: Draft #1.
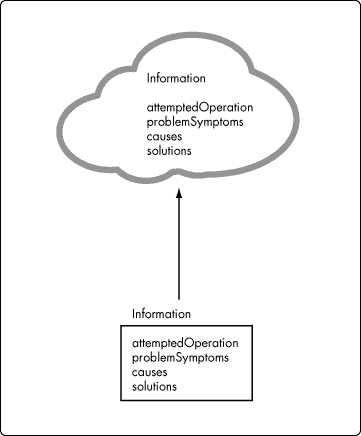
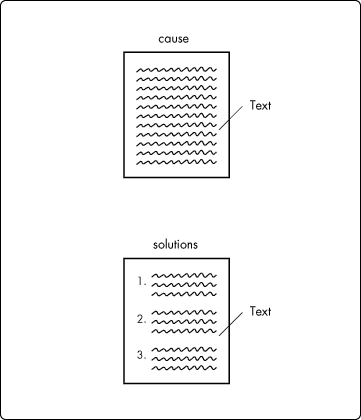
Figure 4 illustrates the condition that obtains when more than one solution pertains to the cause described in the text stored in an information object's cause attribute.
Figure 4: Text storage of multiple solutions associated with a cause.
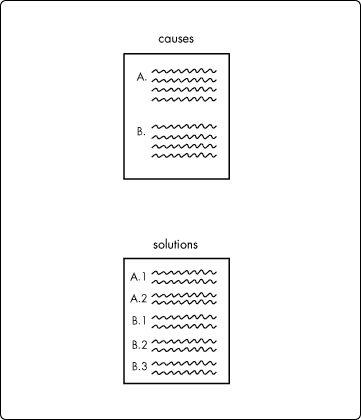
To make things worse, we anticipate that the problem described by an information object may have more than one cause. Keeping to the design presented in Figure 3, we move on to the data problem illustrated in Figure 5.
Figure 5: Text storage of multiple solutions associated with multiple causes.
Finally, let's suppose that either a solution or a cause is associated with more than one problem. In our hypothetical system we're using an information object to describe a problem, so if we have two problems we probably have two information objects. Figure 6 illustrates the data-problem we can anticipate if we keep to the design suggested in Figure 3.
Figure 6: Text storage of multiple solutions associated with multiple causes associated with multiple problems.
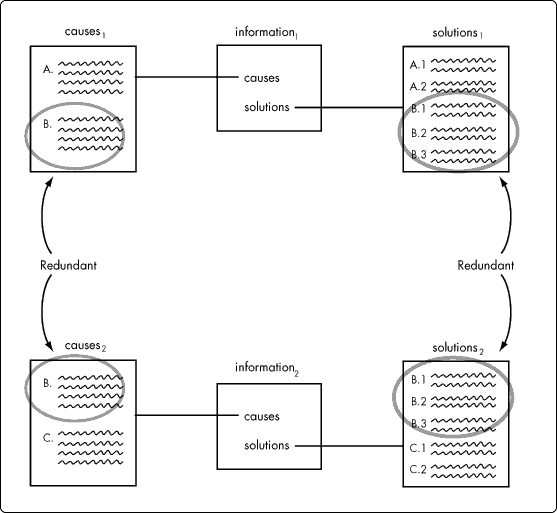
In Figure 6 we see that not only do we have redundant data, a circumstance that significantly increases the overhead required to maintain data integrity, we have no way to manage the relationship between the sets of redundant data.
(Note that if an organization's approach to information design is fundamentally the approach illustrated in Figure 3, the need to mark-up and distribute information in multiple formats compounds the data management problem beyond hope of resolution -- particularly where vast data sets are concerned.)
We present the design illustrated in Figure 3 as the first draft of a design for diagnostic content because the design reflects the way in which writers and editors may be used to thinking of the relationship between a document and the information it contains. According to this way of thinking, the document is both storage device and output. Figure 7 illustrates the relationship between information content and information storage in a paradigm where paper is the storage device.
Figure 7: Paper as both storage device and presentation medium.
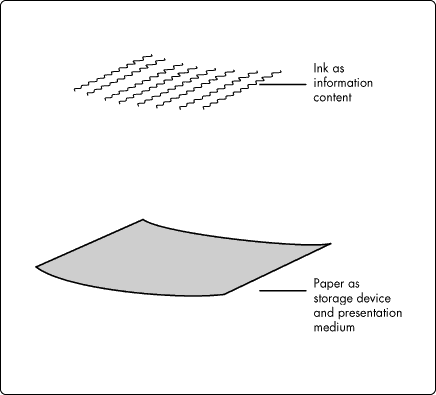
In Figure 7, we think of the ink as the stratum containing diagnostic content, and so separate it from the storage stratum. In Figure 8, we put a relational schema "under" the content stratum for the purpose of storage so that we can conceptualize the ink as being derived from the database before it is presented. This conceptualization opens the way for the situation illustrated in Figure 9, in which information content can be stored in either a relational schema or an object schema, and the information content can be output in a variety of formats and media.
Figure 8: Conceptualizing information apart from a paper paradigm.
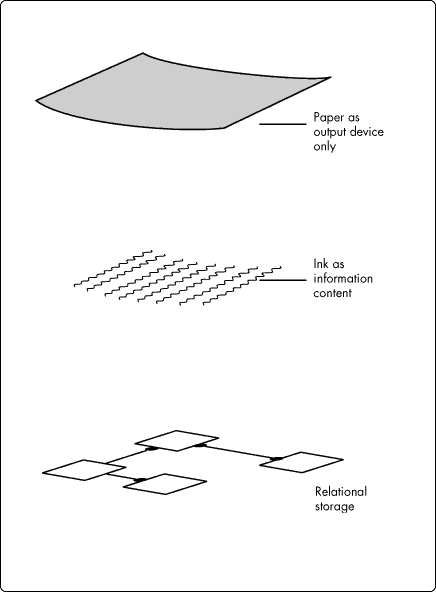
Figure 9: Initial view of technological context for information design.
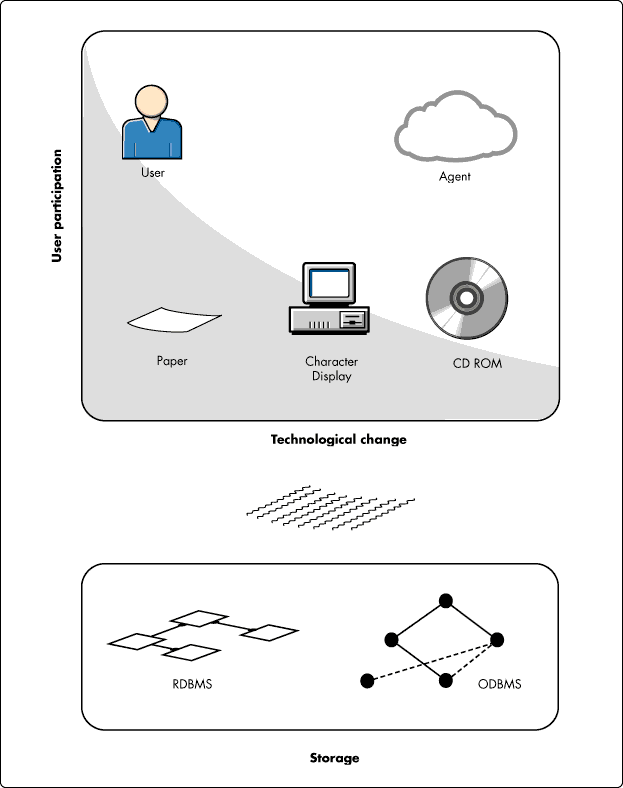
Finally, Figure 10 suggests that in a paper paradigm, a person brings to information consumption the intelligence required to extract and apply information. Paper is the storage device, and the manner in which the information appears on the paper is crucial to a person's ability to find and otherwise manipulate informational content. Moving to the right of the diagram, information presentation (represented by the ink, or text, stratum icon) lessens in importance as technologies move toward allowing intelligent agents to interact directly with the data repository. Figure 10 illustrates the context that this article assumes must be addressed by information design in order to promote the longevity of a design's usefulness.
Figure 10: Technological continuum that must be addressed in information design.
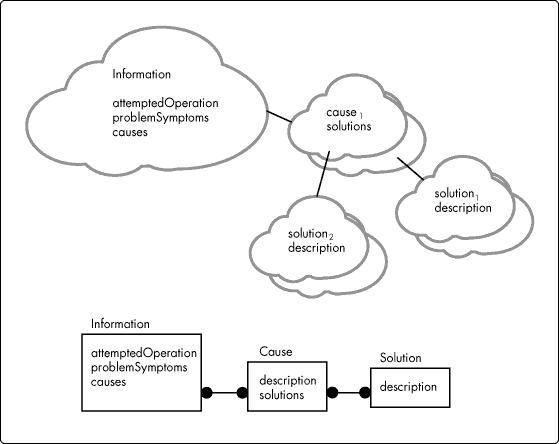
Given this context, we re-evaluate the design presented in Figure 3 and propose the next iteration. In Figure 11 we present a simple entity relationship (ER) diagram in which a many-to-many relationship exists between Information and Cause, and in which a one-to-many relationship exists between Cause and Solution. Corresponding memory-resident objects also appear in the diagram.
Figure 11: Information object: Draft #2.
The arrangement proposed in Figure 11 allows Information, Cause, and Solution items to be maintained independently. If we model the document as though the document is both storage and output, we wind up with the design illustrated in Figure 6, where the content of each causes field, and each solutions field is independent. In such a design, information is redundant. Search engines can be employed to find all the occurrences of redundant information, but search technology manages the situation from the output side of the problem. To manage information (which translates to data integrity, or information quality) some provision must be made on the storage end of the system to reduce or eliminate redundancy.
Using the approach presented in Figure 11, we might formulate a design that treats an Information object's attemptedOperation and problemSymptoms attributes similarly to the design shown in Figure 11 for causes and solutions. Thus, as Figure 12 suggests, an Information object constitutes its content through relations with tables containing data for attemptedOperation, problemSymptoms, and causes.
Figure 12: Information object: Draft #3.
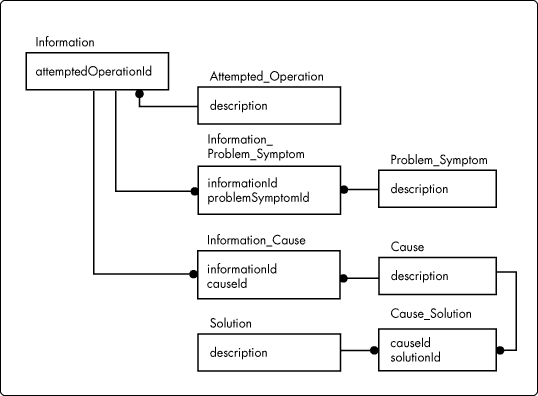
The design proposed in Figure 12 means that changing the description of an attempted operation changes every Information object to which that attempted operation is associated. This design enables the information management system to deal with a level of granularity of which the system is otherwise incapable. At least two things must be considered in adopting such a design:
Does the volume of information and do the resources and capabilities of the client (i.e., the customer) accommodate such granularity?
Version control of documents is affected as associated objects change.
The greater granularity of information management must be addressed by the customer at least in terms of the tools to be used to manage the information, and in terms of the mind set of customer personnel. Document-focused tools and a document-centric mind set, or paradigm, break down in the face of such granularity. Version control, in terms of document management, should also be evaluated, and tools and policies put in place for the purpose.
At the outset of this definition of diagnostic content, the following list of attributes was presented:
attemptedOperation
problemSymptoms
causes
solution
With the design presented in Figure 12, solution would no longer be an attribute of Information. Instead, solutions would be an attribute of Cause.
Descriptors and Indexes
So far, we've talked about designing an information object so that its attributes support the sample diagnostic process presented in Figure 1. We've suggested that these information attributes be grouped under the virtual heading Diagnostic content. We now propose two other virtual headings for attributes of an information item:
Descriptors
Indexes
Descriptors pertains to everything from creation date to attributes that determine whether an information object is proprietary, whether the information contained is considered urgent, etc. Descriptors are attributes that factor in the process of productization and distribution of information.
Descriptors to be included in the content model of our information object include:
id
creationDate
memo
disclaimer
trademark
These attributes are defined as follows:
id -- The id attribute of a memory-resident instance of Information corresponds to the unique identifier in the Information table of the database on the row containing the data from which the memory-resident object is constituted. Figure 13 shows the relationship between the attributes of a memory-resident instance of Information, and the database cell contents from which the memory-resident instance is derived.
Figure 13:Memory-resident and database cell values.
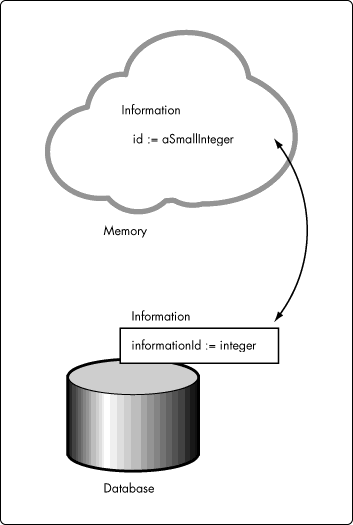
For example, the informationIdcolumn of the Information table in the database is populated with values, each of which is an integer. When an instance of Information is constituted in memory, the id value in the memory-resident object is an instance of SmallInteger (represented in Figure 13 in the Smalltalk nomenclature of "aSmallInteger", which represents an instance of SmallInteger, as opposed to the class SmallInteger). A discussion of the manner in which a memory-resident object is constituted is outside the scope of this particular article. It pertains to a discussion of data storage, considered later in this article series.
creationDate-- In the database, the creationDate column of the Informationtable contains datetime values. Within memory, each datetime value from the database is represented as an instance of Timestamp (again using Smalltalk nomenclature).
memo -- The database cell from which the memo attribute's contents is derived contains a varchar value. The memo attribute of a memory-resident information object holds on to an instance of ByteString. The purpose of a memo attribute is to contain commentary concerning the information item, such as operational commentary useful to the people responsible for managing the information.
disclaimer -- The disclaimer pertains to the presentation of the information item as a document. It contains the declaration that the information was received from outer space, that no earthly entity can, does, or even ought to be responsible for anything, and that, in fact, the purveyors have no knowledge of the information, did not exist when it fell from the sky, and cannot be contacted because they really don't exist either. The disclaimercolumn in the Information table contains data of type integer because each cell value in the column refers to a particular row in the Disclaimer table where the text of the disclaimer is actually stored. We might have modeled disclaimer as a varchar containing the text of a disclaimer, but doing so would have repeated that text on every row of the Information table, and would have made modification of the disclaimer burdensome. The proposed design allows for a single modification to affect all occurrences, and opens the way for multiple disclaimers.
trademark -- See disclaimer.
Indexes
Indexes pertains to structures that may be built into a system for accessing technical content. Use of the term, here, does not pertain to indexes implemented in a relational database. Key words, for example, provide a relationship between an object's information content and structures that enable navigation over that content. This article suggests only a product index; however, indexes of problem classification, for example, would be equally appropriate.
Our sample document includes the following attributes that are grouped under the abstract, or virtual, heading of indexes:
abstract
author
events
distribution
products
As described in the following definitions of these attributes, most of the attributes we've grouped under the heading of indexes constitute a relationship between an information item and some other entity within the system (e.g., User, InformationEvent). These relationships appear in the database schema as join tables between Informationand an associated table.
The primary purpose of such relationships is to facilitate information discovery. For example, the relationship between Informationand User lets us find information items on the basis of authorship, or to find authors on the basis of information. The relationship between Informationand Information_Event lets us find information items on the basis of where items are in the management process. The products attribute is a join between Informationand Product, allowing us to access, or index, information on the basis of known products.
One of the benefits of the kind of relationship enforced for such indexes as author, events, and products, is that a change in an entity on either side of the relationship shows up wherever the relationship is accessed. Were products, for example, maintained as a text attribute in the Information table, every occurrence of a product name would be distinct. Furthermore, products would benefit from none of the relational capabilities available to objects modeled as tables. The same is true of distribution, even though the value held onto by distribution is much less complex than Product.
Finally, abstract is presented, here, as a text field if only to illustrate the design required for such an attribute. Fundamentally, abstract may be thought of as keywords arranged in prose. Another approach to the design for an information item could just as easily include a join between an Informationtable and a Key_Word table. This functionality, however, is illustrated by products (even though a product is a much more elaborate entity than a key word might be).
These, then, are the definitions of the indexes associated with an information item:
abstract -- In the database, the cell containing the value to be assigned to abstract might contain a varchar. The abstract of a memory-resident instance of Information holds on to an instance of ByteString. The purpose of abstract is to provide a textual synopsis of the problem and the information content associated with it.
In choosing to implement abstract as a text field, we forego the possibility of using a relational architecture to associate information with key words. Given such a decision, we cannot use the database to efficiently index, group, or retrieve information on the basis of keywords. This circumstance is counterbalanced by the fact that the task of data management is greatly simplified. An organization's ability to ensure data integrity (a function of organizational culture, information-management maturity, and manpower resources) may be the gating factor in deciding how much the database must support retrieval and how much retrieval must be enabled apart from the database (e.g., typically via text retrieval).
author -- The proposed design for an information item models the author attribute as a one-to-many relationship between Information and User. Thus, each row in the Information table is associated with a single row in the User table. Conversely, each row in the User table can be referenced in any number of rows in the Information table.
The author attribute of a memory-resident instance of Information, holds on to an instance of User. That instance of User is constituted from the row in the User table whose userId matches the authorId on the row in the Information table containing the data from which the instance of Information was constituted. As noted in the previous article in this series, this explanation of corresponding IDs does not correlate with memory-resident object equivalence, but is presented merely to explain the relationship between the data in the database and the memory-resident objects constituted from that data.
A detailed definition of the proposed User table and corresponding memory-resident object is not presented in this article -- except as the table appears in the schema, and as instances of User figure in explanations of Information and related functionality.
events -- See the previous article in this series for an explanation of the relational schema associated with the events attribute. A memory-resident instance of Information uses events to hold on to a collection of instances of InformationEvent.
distribution -- The distribution attribute of a memory-resident instance of Information holds on to an instance of InformationDistributionClassification. Figure 14 illustrates the relational schema for the tables involved in the relationships between Information, User, and InformationDistributionClassification.
Figure 14: Relational schema for InformationDistributionClassification.
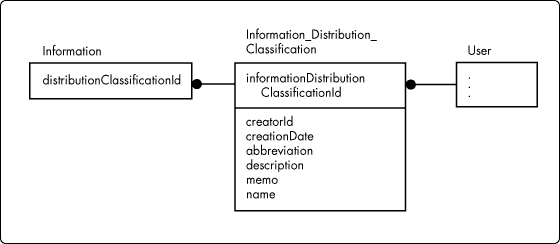
In Figure 14, the columns in the Information_Distribution_Classification table are similar to those same columns appearing in other tables defined in this and the previous article in this series.
The purpose of distribution, in our hypothetical information management system, is to indicate the community to which the information should be available. For example, a classification of "public" would indicate that the information should be made available to anyone. A "proprietary: need-to-know" classification would be commensurately limited.
products -- Designing the architecture for a product taxonomy should begin with a deep breath. For example, a product to someone in sales and marketing may be quite different from the bill-of-materials view of product common to manufacturing. The notion of product in engineering is also likely to differ from the perception of product in service and support.
For our hypothetical information management system, we present a supersimplified definition of product because our focus is diagnostic information rather than the domain of product definition, and because needless complexity in a sample system undermines our objective of introducing object-oriented design.
The proposed definition of product includes the following attributes:
productId
creatorId
creationDate
abbreviation
description
memo
name
partNumber
productClassificationId
vendor
Attributes, in the foregoing list, such as creatorId, description, memo, etc., have the same content in the database (i.e., data type) and the same corresponding memory-resident attribute contents as described earlier for other tables and memory-resident objects containing such attributes.
This is as good a place as any to comment on the importance of terminological consistency in both database schema and object attributes. We might say that terminological integrity pertains to whether the names of things appropriately reflects the nature of the thing itself. Terminological consistency pertains to whether similar database columns and similar object attributes are similarly named. The needless havoc engendered by a memo, for example, being named memo in one place and note in another is really inexcusable. The naming of things in an object-oriented approach is of almost paramount importance because until we can represent objects graphically, the name is the primary clue to the nature and behavior of the object.
The productIdcolumn in the Product table is defined similarly to each column in other tables in the schema containing the unique key for each row in a table. The productClassificationId is analogous to the distributionClassificationId in the Informationtable.
The partNumber column contains data of type integer, and a memory-resident instance of Product holds on to an instance of SmallInteger in is partNumber attribute.
Finally, vendor contains data of type varchar, and a memory-resident instance of Product holds on to an instance of ByteString in its vendor attribute. It might be desirable in an information management system to model vendors as objects derived from data in a Vendor or Company table; however, such complexity undermines the objective of this article series.
Schema
Figure 15 presents an entity relationship diagram for the database schema discussed throughout the foregoing definitions.
Figure 15: Partial entity relationship diagram for Information.
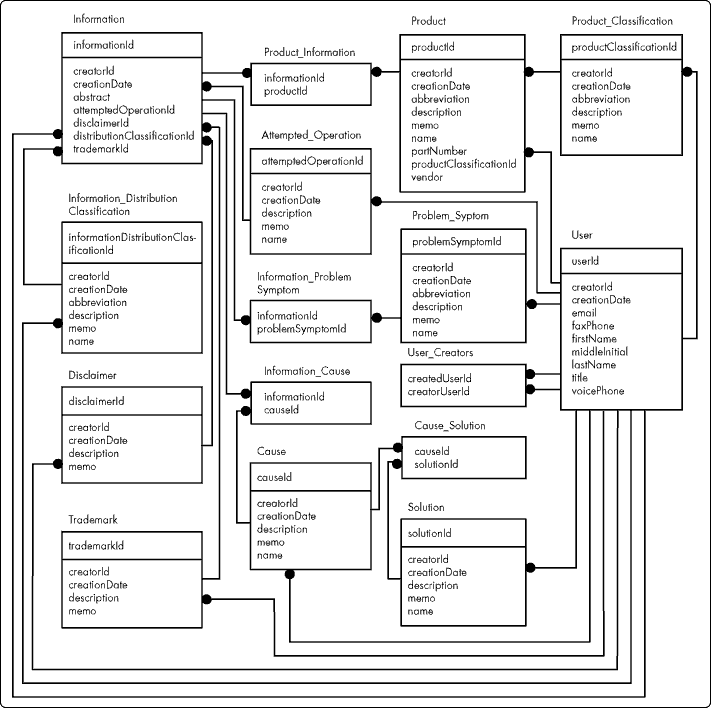
The schema does not include entities and relationships required to support:
Mark-up of information items
Distribution of information items
The focus of this article is the design of information content relative to the information consumption modeled in Figure 1. Mark-up, at least, will be discussed in a subsequent article in this series. A discussion of distribution, supported by similar schema and addressing various implementation constraints, is available in [3].
In Figure 16, then, we present the schema-to-date for our hypothetical information management system. The difference between Figure 15 and Figure 16 is that Figure 16 includes tables and relationships supporting the process management described in the first article in this series.
Figure 16: Complete (to-date) entity relationship diagram for Information.
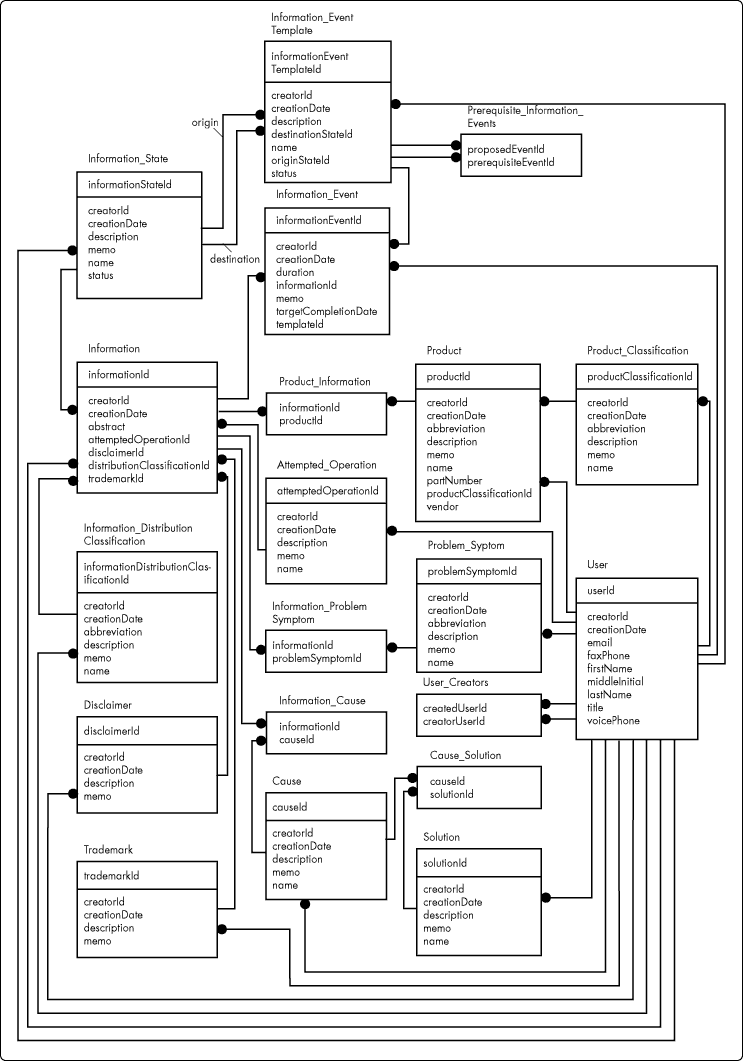
Class Hierarchies
The first article in this series proposed a class hierarchy to which classes representing states and events might be associated. Figure 17 presents a class hierarchy that includes objects from the previous article, as well as objects and attributes added in this article.
Figure 17: Class hierarchy showing instance variables.
Object()
EventAgent(event, managedObjectClass)
InformationEventAgent()
RequestCopyEditAgent()
PersistentObject(creator,creationDate, id)
AnnotatedObject(abbreviation,description, name, memo, status)
AttemptedOperation (informationObjects)
Cause (solutions)
Disclaimer (informationObjects)
Event(agent, destinationStateId,duration, originStateId, prerequisiteEvents, targetCompletionDate,
templateEventId)
InformationEvent(informationId)
InformationDistributionClassification(informationObjects)
InformationState()
ManagedObject(events)
Information(abstract,attemptedOperation, author, causes, disclaimer, distributionClassification,
problemSymptoms, products, trademark)
ProblemSymptom (informationObjects)
Product (informationObjects,partNumber, productClassification, vendor)
ProductClassification(products)
Solution (causes)
Trademark (informationObjects)
User (attemptedOperations,causes, disclaimers, email, faxPhone, firstName,
informationDistributionClassifications,informationObjects, lastName, middleInitial,
productClassifications,products, solutions, problemSymptoms, title, trademarks, voicePhone)
Partial class hierarchies were presented in the previous article. Those hierarchies are included in Figure 17, in which it may be noted that AnnotatedObject now has an abbreviation attribute. The abbreviation attribute is used in numerous subclasses, but not all. It seemed better to have this attribute higher in the hierarchy and allow subclasses to use or not use it, than to proliferate the same attribute and associated behavior in numerous classes.
The attribute informationObjects, on the other hand, appears seven times in the hierarchy because the hierarchy is organized according to the attributes in the table from which an instance of each class is constituted (e.g., the columns in the Informationtable, the columns in the Product table), not according to the relationships among the classes (i.e., the join tables in the relational schema, or the one-to-many or many-to-one relationships among the tables). As a result, these are the frequencies with which relationship attributes are repeated in the hierarchy:
|
7 informationObjects3 causes3products2 problemSymptoms2 solutions1attemptedOperations1 disclaimers1events1 informationDistributionClassifications1prerequisiteEvents1 productClassifications1trademarks |
Whether or not to allow such code redundancy may depend upon factors ranging from the configuration of the development team that will create and maintain the code, to considerations of the size to which the hierarchy may grow. It might, for example, seem desirable to migrate all relationship behavior to a single abstract class where any access of a relationship can be maintained. Figure 18 illustrates such a modification to the hierarchy by adding AssociatedObject as a subclass of AnnotatedObject.
Figure 18: Class hierarchy modified to include AssociatedObject.
Object()
EventAgent(event, managedObjectClass)
InformationEventAgent()
RequestCopyEditAgent()
PersistentObject(creator,creationDate, id)
AnnotatedObject(abbreviation,description, name, memo, status)
AssociatedObject(attemptedOperations,causes,disclaimers, events,
informationDistributionClassifications,informationObjects,prerequisiteEvents,
problemSymptoms, productClassifications,products,solutions, trademarks)
AttemptedOperation()
Cause ()
Disclaimer (informationObjects)
Event(agent, destinationStateId,duration, originStateId, targetCompletionDate, templateEventId)
InformationEvent(informationId)
InformationDistributionClassification()
InformationState()
ManagedObject()
Information(abstract,attemptedOperation, author, disclaimer, distributionClassification,
trademark)
ProblemSymptom ()
Product (partNumber,productClassification, vendor)
ProductClassification()
Solution ()
Trademark ()
User (email, faxPhone,firstName, lastName, middleInitial, title, voicePhone)
AssociatedObject provides attributes and behavior for each association in the foregoing list. Inasmuch as subclasses of AssociatedObject do not necessarily have any or all of the relationships assigned to AssociatedObject, each subclass must overwrite accessing methods for relationships irrelevant to the subclass. For example, the following methods are provided for accessing the informationObjects collection:
informationObjects
informationObjects:
addInformationObject:
removeInformationObject:
These methods would be provided by AssociatedObject. Any subclass not using the informationObjects attribute inherited from AssociatedObject would have to overwrite these four methods. (See Code Listing 1. Accessing methods are discussed in more detail under Accessing Methods, later in this article.)
Note: Strings, streams, and collections are handled similarly in Java and Smalltalk, but due to the maturity of the Smalltalk class hierarchy, many Smalltalk components are handled on a higher level than is currenly available in the standard Java class hierarchy. The Java listings in this article assume that methods and classes equivalent to those used in Smalltalk have been defined in appropriate Java packages. Such methods and classes will be italicized and underlined in the code.
Code Listing 1: Overwriting inherited accessing methods
Sample A: Java implementation
public int informationObjects() {
return shouldNotImplement;
}
public int informationObjects( anInformationObject) {
return shouldNotImplement;
}
public int addInformationObject( anInformationObject) {
return shouldNotImplement;
}
public int removeInformationObject( anInformationObject ) {
return shouldNotImplement;
}
Sample B: Smalltalk implementation
informationObjects
^self shouldNotImplement
informationObjects: anInformationObject
^self shouldNotImplement
addInformationObject: anInformationObject
^self shouldNotImplement
removeInformationObject: anInformationObject
^self shouldNotImplement
Thus, even though the addition of AssociatedObject to the hierarchy makes the hierarchy appear more efficient by centralizing association access in a single class, such an approach would mean that each association-accessing method not used by a subclass would have to be overwritten by that subclass. Cause, for example, would have to overwrite the accessing methods for the 11 associations that it does not use, resulting in a total of 44 methods. All told, the hierarchy would be burdened with a total of 480 such methods. These methods could be eliminated by providing versions of them in AssociatedObject that check the subclass of the receiver actually involved, but such checks can needlessly erode performance. Accordingly, we have opted to implement the hierarchy presented in Figure 17.
ManagedObject implements an events attribute, that does group classes according to table relationships; however, this relationship is significant to the objectives of the system because the relationship determines whether the system is used to manage an object. For example, the design presented in Figure 17 can be used to automate the management of information objects. The management of product objects, however, cannot be automated because states and events do not exist, within the system, for that purpose. Were Product made a subclass of ManagedObject, and the schema and corresponding objects implemented for Product that exist for Information, the system could be used to manage product objects as well as information items.
Accessing Methods
Once the class hierarchy has been defined to the extent that inherited knowledge is apportioned throughout the hierarchy, behavior concerning that knowledge must also be provided. The first step in this process is usually the creation of what are termed accessing methods in Smalltalk. Such methods enable a class or an instance of a class to assign or return the contents of a particular attribute.
Code Listing 2 provides the rudimentary functionality needed for each of the instance variables listed in the hierarchy in Figure 17.
Code Listing 2: Accessing methods for the informationObjectsinstance variable
Sample A: Java implementation
public int informationObjects() {
return informationObjects;
}
public int informationObjects( anInformationObject) {
informationObjects = anInformationObject;
}
Sample B: Smalltalk implementation
informationObjects
^informationObjects
informationObjects: anInformationObject
informationObjects := anInformationObject
When an instance of AttemptedOperation is created, for example, the informationObjects: method is used to assign an instance of an OrderedCollection to the informationObjects instance variable. Code Listing 3 provides an excerpt from the method in which this assignment occurs.
Code Listing 3: Assigning a collection at initialization
Sample A: Java implementation
public void initialize()
{
informationObjects ( new OrderedCollection());
. . .
}
Sample B: Smalltalk implementation
initialize
self informationObjects: OrderedCollection new
. . .
Other methods, or other versions of the accessing methods described already, may be necessary as development progresses. For example, assignment of a value to an instance variable may need to be logged so that when the data in the memory-resident instance must be written to the database, the log can be consulted to find out which instance variables have changed. A modification to an information items' abstract assignment method might be made for such a purpose. Code Listing 4 presents such a modification.
Code Listing 4: Using an accessing method for related purposes
Sample A: Java implementation
public void abstract (anAbstract) {
addToModifiedSet (abstract.asSymbol());
abstract := anAbstract;
}
Sample B: Smalltalk implementation
abstract: anAbstract
self addToModifiedSet: #abstract.
abstract := anAbstract.
Contracts, Services, and Other Behaviors
Two methods appear in Code Listing 5 that enhance the accessibility of instance variables:
addInformationObject:
removeInformationObject:
These methods are added to objects in the hierarchy to facilitate the practice of cascading messages. For example, the following code adds two information items to an instance of Cause:
aCause informationObjects add: aInformationObject; add: bInformationObject.
Availability of a method such as addInformationObject: not only allows the following kind of statement, but provides a method that can provide any behavior related to the addition (such as updating a list of modifications to the receiver):
aCause addInformationObject: aInformationObject; addInformationObject: bInformationObject.
Code Listing 5 presents the contents of addInformationObject: and removeInformationObject:. Such methods may be deemed necessary in simplifying an object's interface, or they may focus on the convenience or coding style of the development team.
Code Listing 5: Simple enhancements for accessing instance variables
Sample A: Java implementation
public void addInformationObject (anInformationObject) {
informationObjects.add (anInformationObject);
}
public void removeInformationObject(anInformationObject) {
informationObjects.remove (anInformationObject);
}
Sample B: Smalltalk implementation
addInformationObject: anInformationObject
self informationObjects add: anInformationObject
removeInformationObject:anInformationObject
self informationObjects remove: anInformationObject
A more complex enhancement of an object's interface can be illustrated by enabling an instance of Information to respond to an asString message by returning a String representation of itself. As a partial illustration of such functionality, let's begin by assuming that an asString method on the instance-side of an information item provides the behavior illustrated in Code Listing 6. We present the asString method with the caveat that it represents only a partial implementation.
Code Listing 6: An excerpt from the asStringmethod
Sample A: Java implementation
public String asString() {
WriteStreamOnString
aWS = new WriteStreamOnString (500);
aWS.writeChars ("Document number:");
aWS.writeChar (>\t=);
aWS.writeChars (id.toString());
aWS.writeChar (>\n=);
. . .
return (aWS.contents());
}
Sample B: Smalltalk implementation
asString
| aWS |
aWS := WriteStream on: (String new: 500).
aWS
nextPutAll: 'Document number:';
tab;
nextPutAll: self id printString;
cr.
. . .
^aWS contents
In Code Listing 6, an instance of WriteStream is assigned to a temporary variable. The asString method then adds items to the write stream and concludes by returning the write stream's contents. The document number is derived from the receiver's id attribute, and inasmuch as that attribute holds on to an instance of Integer, the printString message is sent to the integer to convert it to a string so that it can be added to the write stream.
Let's suppose that the next thing to be added to the write stream is the full name of the document's author. Code Listing 7 presents one way (and not the way we will recommend) to do so.
Code Listing 7: An expanded version of the asStringmethod
Sample A: Java implementation
public String asString() {
String aFirstName = creator.firstName;
String aMiddleInitial = creator.middleInitial;
String aLastName = creator.lastName;
String aFullname = aFirstName + " " + aMiddleInitial + " " + aLastName;
WriteStreamOnString
aWS = new WriteStreamOnString (500);
aWS.writeChars ("Document
number:");
aWS.writeChar (>\t=);
aWS.writeChars (id.toString());
aWS.writeChar (>\n=);
aWS.writeChars ("Author:");
aWS.writeChar (>\t=);
aWS.writeChars (aFullname);
aWS.writeChar (>\n=);
. . .
return (aWS.contents());
}
Sample B: Smalltalk implementation
asString
| aFirstName aMiddleInitial aLastName aFullName aWS |
aFirstName := self creator firstName.
aMiddleInitial := self creator middleInitial.
aLastName := self creator lastName.
aFullname := aFirstName, ' ', aMiddleInitial, ' ', aLastName.
aWS := WriteStream on: (String new: 500).
aWS
nextPutAll: 'Document number:';
tab;
nextPutAll: self id printString;
cr;
nextPutAll: 'Author:';
tab;
nextPutAll: aFullname;
cr.
. . .
^aWS contents
In Code Listing 7, the behavior for building a full name exists in the asString method on the instance-side of an information object, but the data involved in the behavior belongs to an instance of User. Wherever possible, behavior and data should belong to the same object. This promotes re-use and ease of maintenance. Also, the object containing the data is probably in the best position to evaluate the data and to handle problems that can arise when its data is requested. For example, a user object, such as might be returned by self creator in Code Listing 7, might not have a middle initial. If that user object's middleInitial attribute holds on to an instance of Nil, self creator middleInitial will return nil, which cannot be added to a write stream. Having such behavior in asString, introduces the need for the asString method, which belongs to an instance of Information, to perform error checking on data owned by an instance of User.
Code listing 8 presents the fullName method implemented on the instance-side of User.
Code Listing 8: A fullName method implemented on the instance-side of User
Sample A: Java implementation
public String fullName() {
WriteStreamOnString aWS = new WriteStreamOnString (int 20);
aFirstName = firstName;
If (aFirstName.notNil())
aWS.writeChars (aFirstName + " ");
aMiddleInitial = middleInitial;
If (aMiddleInitial.notNil())
aWS.writeChars (aMiddleInitial + " ");
aLastName = lastName;
If (aLastName.notNil())
aWS.writeChars (aLastNamel);
return (aWS.contents());
}
Sample B: Smalltalk implementation
fullName
| aWS |
aWS := WriteStream on: (String new: 20).
aFirstName := self firstName.aFirstName isNil
ifFalse: [
aWS
nextPutAll: aFirstName;
space.
].
aMiddleInitial := self middleInitial.
aMiddleInitial isNil
ifFalse: [
aWS
nextPutAll: aMiddleInitial;
space.
].
aLastName := self lastName.
aLastName isNil
ifFalse: [
aWS nextPutAll: aLastName.
].
^aWS contents
Given the fullName behavior provided by any instance of User, an information object's asString behavior can be simplified. See Code Listing 9.
Code Listing 9: A simplified version of the asStringmethod
Sample A: Java implementation
public String asString() {
WriteStreamOnString aWS = new WriteStreamOnString (500);
aWS.writeChars ("Document number:");
aWS.writeChar (>\t=);
aWS.writeChars (id.toString());
aWS.writeChar (>\n=);
aWS.writeChars ("Author:");
aWS.writeChar (>\t=);
aWS.writeChars (creator.fullName());
aWS.writeChar (>\n=);
. . .
return (aWS.contents());
}
Sample B: Smalltalk implementation
asString
| aWS |
aWS := WriteStream on: (String new: 500).
aWS
nextPutAll: 'Document number:';
tab;
nextPutAll: self id printString;
cr;
nextPutAll: 'Author:';
tab;
nextPutAll: self creator fullName;
cr.
. . .
^aWS contents
For the purpose of illustrating parameter passing, let's modify the asString method to pass the write stream around among objects providing data to be added to it. We don't need to make this modification, but do so only for purposes of illustration.
Code Listing 10 asks a user object to add to the write stream via the user object's fullNameOn:method.
Code Listing 10: A version of asString that passes a write stream to a user object
Sample A: Java implementation
public String asString() {
WriteStreamOnString
aWS = new WriteStreamOnString (500);
aWS.writeChars ("Document number:");
aWS.writeChar (>\t=);
aWS.writeChars (id.toString());
aWS.writeChar (>\n=);
aWS.writeChars ("Author:");
aWS.writeChar (>\t=);
aWS.writeChars (creator.fullName());
aWS.writeChar (>\n=);
. . .
return (aWS.contents());
}
Sample B: Smalltalk implementation
asString
| aWS |
aWS := WriteStream on: (String new: 500).
aWS
nextPutAll: 'Document number:';
tab;
nextPutAll: self id printString;
cr;
nextPutAll: 'Author:';
tab.
self creator fullNameOn: aWS.
aWS cr.
. . .
^aWS contents
Code Listing 11 illustrates the behavior provided in a user object's fullNameOn:method.
Code Listing 11: A version of the fullNameOn:method
Sample A: Java implementation
public String fullNameOn (WriteStreamOnString aWS) {
aFirstName = firstName;
If (aFirstName.notNil())
aWS.writeChars (aFirstName + " ");
aMiddleInitial = middleInitial;
If (aMiddleInitial.notNil())
aWS.writeChars (aMiddleInitial + " ");
aLastName = lastName;
If (aLastName.notNil())
aWS.writeChars (aLastNamel);
return (aWS.contents());
}
Sample B: Smalltalk implementation
fullNameOn: aWS
aFirstName := self firstName.aFirstName isNil
ifFalse: [
aWS
nextPutAll: aFirstName;
space
].
aMiddleInitial := self middleInitial.aMiddleInitial isNil
ifFalse: [
aWS
nextPutAll: aMiddleInitial;
space
].
aLastName := self lastName.aLastName isNil
ifFalse: [
aWS nextPutAll: aLastName
].
^aWS
In Code Listing 11, aWS is no longer a temporary variable, but is a write stream handed to the method. Note, also, that the method concludes by returning the write stream, not by returning the write stream's contents. Thus, the asString method (as it appears in Code Listing 10) can add a carriage return to aWSimmediately after sending fullNameOn: to the user object.
Thus far, our discussion of the asString behavior has involved only single-element attributes (i.e., elements containing one instance of a class). However, such attributes as problemSymptoms, causes, and others contain collections of objects. Code Listing 12 presents an excerpt from asString that illustrates the receiver's behavior concerning its collection attributes.
Code Listing 12: Handling a collection in asString
Sample A: Java implementation
public String asString() {
WriteStreamOnString
aWS = new WriteStreamOnString (500);
aWS.writeChars ("Causes:");
aWS.writeChar (>/n=);
aWS.writeChar (>/n=);
writeEachOn(causes, aWS);
return (aWS.contents());
}
Sample B: Smalltalk implementation
asString
| aWS |
aWS := WriteStream on: (String new: 500).
. . .
aWS
nextPutAll: 'Causes:';
cr;
cr.
self causes do: [ :aCause |
aCause asStringOn: aWS.
aWS cr
].
. . .
^aWS contents
The excerpt from asString in Code Listing 12 assumes that each cause implements an asStringOn: method. The behavior provided by such a method appears in Code Listing 13.
Code Listing 13: The asStringOn:method
Sample A: Java
implementationpublic String asStringOn(WriteStreamOnStringaWS)
{ aWS.writeChars ( name );
aWS.writeChars ( "--"
); aWS.writeChars ( description
); aWS.writeChar ( >(>
); aWS.writeChars ( creator.lastName
); aWS.writeChar ( >:=
); aWS.writeChars ( creationDate.toString()
); aWS.writeChar ( >)=
); return (aWS.contents());}Sample
B: Smalltalk implementation
asStringOn: aWS aWS
nextPutAll: self name;
nextPutAll: '--'; nextPutAll:
self description; nextPut: $(;
nextPutAll: self creator lastName;
nextPut: $:; nextPutAll:
self creationDate printString;
nextPut: $). ^aWS
The asStringOn: method adds to the write stream a presentation of the cause that puts it name first, followed by two dashes, followed by the cause's description. Then in parentheses the lastName of the cause's creator appears, followed by a colon, followed by the creationDate the cause was entered into the system.
Finally, the class hierarchy presented in Figure 17 indicates that AnnotatedObject and each of its subclasses have description and name attributes. Instead of implementing asStringOn: on the instance-side of Cause, and again on the instance-side of ProblemSymptom, and on the instance-side of each object with which an information item must interact in order to constitute a string representation of itself, we implement asStringOn: on the instance-side of AnnotatedObject. Any subclass can either use that behavior or overwrite the method.
Bibliography
1 Young, Al; Woolston, Dayle S; Johnson, Jay M. An Object-oriented Approach to Process Modeling in the Context of Information Management (Developer Notes, July 1996).
2 Booch, Grady; et al. Unified Method: Notation Summary Version 0.8. Rational Software Corporation, 1995.
3 Young, Al; Capel, Bob; Johnson, Jay M. The Problem of Document Distribution (Object Magazine, in press).
* Originally published in Novell AppNotes
Disclaimer
The origin of this information may be internal or external to Novell. While Novell makes all reasonable efforts to verify this information, Novell does not make explicit or implied claims to its validity.