An Object-Oriented Approach to Process Modeling in the Context of Information Management
Articles and Tips: article
Senior Research Engineer
Novell Systems Research
DAYLE S WOOLSTON
Senior Software Engineer
Advanced Development Group
JAY M. JOHNSON
Software Engineer
Electronic Support
01 Jul 1996
This article is the first in a series focusing on object-oriented design and development. By the conclusion of the article, we're examining Java and Smalltalk code. Thus, even though the discussion at the outset is filled with diagrams and the nomenclature of object-orientation, we move rather quickly from design to implementation. The purpose in this is to show the relationship between seeing a domain in terms of objects and implementing solutions for that domain in an object-oriented tool. Across the contemplated series of articles, the discussion also moves from the more general, or seemingly theoretical, to development details that, frankly, have more of a tendency to warm the cockles of the engineering heart.
- Introduction
- Overview
- Importance of the Design Activity
- Domain-Information Management
- Modeling the Productization of Information
- Class Diagrams of States and Events
- Event Agents
Introduction
Object-oriented development involves more than learning to program in yet another language. A purely object-oriented tool like Java, Smalltalk, or the object-oriented use of C++ requires that problem domains be conceptualized in terms of the paradigm inherent in object technology.
The task of transitioning from a procedural mindset to an object-oriented paradigm can seem overwhelming; however, the transition does not require developers to step into another dimension or go to Mars in order to grasp a new way of doing things. In many ways, the object-oriented approach to development more closely mirrors the world we've been living in all along: We each know quite a bit about objects already. It is that knowledge we must discover and leverage in transitioning to object-oriented tools and methodologies. (See Booch's Object-Oriented Analysis and Design with Applications for a good introduction to the world of objects.)
While information management is the problem domain from which this series draws hypothetical examples, the concepts presented can be applied to virtually any domain. This article, for example, focuses on process modeling. Concepts presented here apply, to a greater or lesser degree, to any domain involving a process.
Material presented in this article is intended for use whether a developer implements in the Java language, Smalltalk, C++, or any other object-oriented language. Presentation of modeled objects attempts to conform to the Unified Method for Object-Oriented Development specified by Grady Booch and James Rumbaugh. The documentation set for the Unified Method (or Unified Modeling Language) is available from Rational Software Corporation at the following web site:
The Version 0.8 documentation set includes the following:
Overview Reference Manual Metamodel Guide Notation Summary User Guide
The primary purpose of this article is to introduce a discussion of object-oriented design. As the Novell development community looks toward Java, an understanding of the paradigm inherent in that development environment is crucial. A discussion of design may seem focused on architects and designers; however, engineers assigned to implement an architecture in an object-oriented tool soon discover the relevance of such discussions.
Information management is the domain from which examples in this article series are drawn; nevertheless, the concepts and principles presented are intended for general application. Designers and developers responsible for process automation may find the content of this first article particularly useful.
Figure 1 presents a simple kind of Platform Diagram (see Notation Summary, p. 44) summarizing a system configuration for the hypothetical domain. The configuration summarized in Figure 1 is by no means the only configuration to which concepts in this article series apply. The sample configuration serves only as a point of orientation for applying this discussion to other contexts. The material in this article is applicable whether TCP/IP or SPX/IPX is used, whether the database is Oracle, SYBASE, etc., or whether the applications running on the client are written in the Java language, Smalltalk, C++, or another environment.
Figure 1: Sample Platform Diagram.

In Figure 1, the database located on the server contains the information to be managed by an information management system. The term "information" is used in this article to apply to material appearing in the real world as documents (e.g., legal documents, financial records, medical records, and any of the myriad forms by which organizations conduct business in every industry).
The PCs in Figure 1 represent workstations at which client application(s) run as components of an information management system. Each workstation connects to the server via TCP/IP, and SQL is used to query the database. Details of the hardware as well as the software infrastructure supporting the configuration shown are not discussed in this article.
The phrase "information management system" refers to technology(ies) used in dealing with information. Systems typically include automated and non-automated technologies. The phrase, as used here, pertains to the entirety of policies, procedures, and activities associated with the information managed as well as with the information itself.
Overview
This DevNote covers five main topics:
Importance of the design activity
Hypothetical domain--Information management
Modeling the productization of information
Class diagrams of states and events
Event agents
Importance of the Design Activity. The article begins with a brief statement about the importance of the design activity within the development process. Attention to design is paramount in any development effort; however, in the context of development efforts involving a paradigm shift for the development team (e.g., shifting from procedural programming to object-oriented programming), the importance of the design phase cannot be over-emphasized. In the context of such a paradigm shift, the design phase affects not only the quality of the result, but the ability of developers to change mindset.
Hypothetical Domain-Information Management. A description of the sample domain is provided. The sample domain serves as a real-world environment from which examples can be drawn for this discussion of object-oriented design.
Modeling the Productization of Information. As the article progresses, the focus on the sample domain necessarily becomes more granular. Information management, for example, is first divided into two broad activities:
Management
Consumption
Inasmuch as this article focuses primarily on modeling processes, the activities grouped under management are subdivided into three groups:
Capture
Productization
Distribution
The concept of states and events is then presented as a way of conceptualizing processes. Productization of information is used as an example of state-transition modeling.
Definition of the sample domain concludes by listing the models to be formulated in developing the hypothetical information management system:
Management
Consumption
Content
Storage
A more detailed discussion of management is presented. Sample states and events for productizing information are discussed.
Class Diagrams of States and Events. A generic class hierarchy is presented that can be used to implement states and events for managing almost any kind of object. Class diagrams and a database schema for states and events are presented.
Event Agents. Finally, event agents are described as a way of implementing policies and procedures governing the assignment of an event to a managed object. The behavior of a sample event agent is presented in methods coded in both the Java language and Smalltalk (in this particular case, ParcPlace-Digitalk's VisualWorks).
Importance of the Design Activity
Frequently, modeling is either skipped or given only a nod in a headlong rush to begin coding. And why not? More than one factor can impel developers and development teams to do so; nevertheless, the importance of modeling can hardly be overemphasized. It provides stability to the organization as well as the development effort over the long term. More specifically, modeling that is done well:
Enables incremental implementations.
Facilitates greater coherence among diverse tool sets, as diverse applications speak to a common design.
Allows shared services and functionalities to be migrated to application layers so that development time and talent can be more cost-effectively focused.
Clarifies an organization's thinking in its own eyes so that operational and cultural initiatives can be shaped to facilitate application deployment and use.
Stabilizes an organization's development efforts.
Incremental Implementations. Progress is generally made incrementally. A comprehensive design helps ensure that partial implementations are part of a coherent whole. Incremental implementation can also enable an organization to take advantage of maturing technology. If an organization understands, for example, that it must take three steps in implementing an advanced tool, the time taken to complete steps one and two provide an opportunity for the tool itself to mature or for the organization to identify a better tool.
Coherence Among Diverse Tool Sets. Applications that interface to a common architecture can be as diverse as the individuals who champion them, or as diverse as an organization's culture allows. A comprehensive design facilitates diversity in tool sets by forcing conformity on the back end, where users may have little interest. This can diffuse much of the combat that invariably ensues over tool preference.
Application Layers. A comprehensive design clusters behavior and knowledge so that development efforts are insulated from each other. For example, class hierarchies that broker SQL transactions between information objects and the database containing the data from which those objects are built, can be maintained apart from classes focused on information capture. Thus, issues relating to database interaction need have only minimal affect, if any affect at all, on development efforts focused on information capture. This enables both development efforts to move forward essentially parallel to each other.
Organizational Thinking. Changing requirements is one of the greatest vulnerabilities for both the development team and its customers. Automation frequently requires customers to understand their own processes to a degree of detail previously unexamined. A thorough design effort clarifies requirements up front. Without this clarification, requirements and expectations constantly change. Software development clarifies a customer's thinking concerning customer policies and procedures. If this clarification occurs as part of a thorough design phase, the costs are minimal, at least in comparison with the costs of having the clarification occur during implementation or deployment.
Stability. A thorough design narrows the gap between development and deployment. An organization is also buffered against turnover within its development team.
Domain-Information Management
Product documentation is the domain on which examples in this article focus. Nevertheless, the concepts and techniques can be adapted to any information management system, and to numerous other domains.
Figure 2 presents a simple diagram from which to derive a more detailed conceptualization of information management. The universe of things constituting the sample domain is initially divided into management and consumption. In this DevNote, management constitutes things that act and things that are acted upon in the creation of information. Information, in the broadest sense, is knowledge about things (i.e., symbolic representations or descriptions of things).
Thus, information management is the creation and manipulation of symbols. Consumption, as the term is used here, may be thought of as the interpretation of information as well as experience gained through actions taken based on the interpretation of information.
The arrows in Figure 2 suggest that output from information management is given to consumption and that feedback from consumption returns to management. The figure also implies that the effectiveness of consumption and management are interdependent.
Figure 2: Information consumption and management.

The management circle in Figure 2 can be divided into the following kinds of activities:
Capture involves creating information. A technical writer, for example, working in the sample domain might interview an engineer to collect explanations that are captured in the system as illustrations or text. The same technical writer might work with a product to formulate an installation procedure, also captured in the system as the steps in a process. Information from product testing might be captured in the system as work-arounds, etc. Information systems in other domain contexts might capture information via the completion of a form by a data-entry clerk, by the description of a customer's problem reported to a help desk technician, by a sales representative filling out an order. Information capture is the point at which information enters the system.
Productization is the synthesis of the information. For a publisher, productization involves everything from copy editing to mark-up. In organizations for which the information itself is not a product, productization may consist primarily of quality assurance activities.
Distribution involves the actual transfer of information to customers. Such activities may include HTML mark-up for displaying the information in a Web browser, or preparation of soft-copy for transmittal to a publishing house, etc. Contemporary information management systems typically distribute to multiple destinations/formats.
These three groups of activities may be thought of as states. A state, as defined by Booch and Rumbaugh, "represents a period of time during which an object is waiting for an event to occur." (Notation Summary, p 32). The information, in the sample domain, is "the object" and the events constituting productization, for example, are the things done to that object to make it a product. Fundamentally, object oriented design endeavors to model real-world objects and processes. Thus, an analogy to the sample domain can clarify the concept of state as it relates to information.
In the sample domain, information may be processed as documents in a paper paradigm. Such a process necessarily provides for the routing of documents. In-baskets and out-baskets, for example, are used to hold documents while they await processing. As a document is worked on, it is removed from a basket, a task is completed, and the document is returned to a basket from which it is moved to another desk or office where other tasks are performed.
Figure 3 illustrates a simple component of such a process, in which the desk is a state and the arrows are the events that move items from one state to another.
Figure 3: Segment of traditional management process.

In Figure 4, an analogy is presented between a state in a traditional management process, and the manner in which such a state would be represented in Unified Method notation. Note that the in-baskets and out-baskets are simply devices in the paper system, and do not have a direct corollary in the diagram.
Figure 4: Analogy to state diagram. .

Sometimes several tasks may be performed at a single state. For example, copy editing in a technical publications department might be defined as including the checking of spelling, grammar, usage, etc. Figure 5 illustrates how this might be represented in a State Diagram.
Frequently, events within a process move an item from state A to state B and back to state A. For example, copy editing might include checking of references to graphics as well as text, and the checking of graphics might occur at another state. Figure 6 illustrates this situation.
Figure 5: A more complex state.

State diagrams presented in this article appear in the idiom of the Unified Method formulated by Grady Booch and James Rumbaugh. Each state is represented by a round-cornered rectangle in which the state's name appears. Arrows in the diagram indicate direction of flow, and the label associated with each arrow names the event that moves an item from one state to another.
For example, the arrow labeled check graphic references moves a document from the Copy Edit state to the Graphic Edit state. Inasmuch as the events labeled check spelling and check grammar do not move a document to a state different from the state of origin, the arrows for such events simply curve back onto the state of origin.
Figure 7 presents the information Management state in the idiom of the Unified Method.
In this article, the approach to designing an information management system involves a scrutiny of the following aspects of information management:
Management
Consumption
Content
Storage
Figure 6: A sample relationship between states.

These are not necessarily the only facets of information management that must be documented; however, they provide an overview for most, if not all, of the aspects of such a system. And design is not so much a discrete phase in the development life cycle, as it is a thread running through the entire lifecycle.
At some points in that lifecycle, design may be the dominant activity. At other times, design may occur here and there to accommodate the overlooked, or to elucidate some aspect of the system that was anticipated, but which belongs to a level of detail too granular to have been addressed during initial stages of a project.
Figure 7: Management as a state diagram.

Figure 8 suggests the relationship among the general items to be modeled:
Management. The management model may be thought of as modeling the infrastructure in which information flows. This article focuses on preparing design documentation for management activities. In terms of the Unified Method, this article suggests that a Use Case Model should first be prepared, followed by the preparation of a State Diagram.
Consumption. Consumption is the manner in which output from information management is used. Whether or not documentation of consumption is used to automate consumption, the documentation is important because consumption determines the nature of the information that flows in the management process (i.e., consumption is a major determinant of content).
Technical publication, as a sample domain, would model the use made of product documentation. An information management system associated with a helpdesk, would model the diagnostic process in which that system's diagnostic information is used.
Figure 8: Detailed summary of information management.

In terms of the Unified Method, this series of articles discusses the formulation of a State Diagram as a model of information consumption.
Content. A model must be formulated also for the information itself. In this article, we refer to this design documentation as the content model because this model pertains to the information itself (i.e., the thing consumed, managed, stored).
One of the primary reasons for preparing the set of model suggested here is to insulate aspects of information management from each other. For example, providing a design that separates management process from the item managed insulates both the process and the managed object from changes in each other.
An analogy to the world of transportation may be useful: The relationship between a train and the track on which it travels is much closer, much more interdependent, than the relationship between an automobile and a road. Automobiles can vary greatly in wheel-base size, weight, length, etc., and yet all travel the same road. Furthermore, the network of roads on which widely divergent kinds of automobiles can travel can consist of everything from dirt lanes to superhighways. While the trains that can travel a particular rail system vary in major ways, they do not vary as greatly relative to the rail system on which they move.
One of the primary objectives in designing an information management system (or any system for that matter) is to insulate process from content and vise versa. Doing so promotes the resilience and longevity of the system as it faces organizational, procedural, and technological change. (See Booch's discussion of coupling in "Measuring the Quality of an Abstraction," Object-Oriented Analysis and Design with Applications, p. 136.)
Storage. Finally, a model must be formulated for data storage. This model includes such considerations as the database(s) constituting the system's data warehouse, client/server issues, etc. In terms of the Unified Method, design documentation for the storage aspect of an information management system would include at least a Platform Diagram, a State Diagram, and a Class Diagram.
Applications developed for the domain require yet another model; however, such models tend to be implementation-specific and therefore are beyond the scope of this series of articles.
Modeling the Productization of Information
The first task in modeling what we have termed the management aspect of the information management system is to prepare a Use Case Model for the domain. One of the primary reasons for doing so is to clarify, in the mind of the client or customer for whom the system is being developed, what the system will automate and what it will not automate.
Figure 9 presents a Use Case Model for a hypothetical technical publications department. Represented in Figure 9 are the various activities in which members of the department are involved.
Figure 9: Use Case Model for technical publications department.

Use cases highlighted in Figure 10 involve the processing of a single object (i.e., the information that flows in the system). Each use case, however, can be expanded to a more detailed view and each expanded view may involve objects other than the information to be managed. For example, the Draft Manuals use case might be expanded to show that a writer is responsible for filing a request specifying equipment to be made available so that a product to be documented can be used as part of creating the documentation. The request for equipment, and the process by which it is resolved might fall outside the scope of the information management system.
Figure 10: Use cases to be included in the hypothetical information management system.

In Figure 11, a state diagram is provided for the use cases highlighted in Figure 10. States presented in Figure 11 include: Authorize, Cancelled, Draft, EngineeringReview, Quality Assurance, CopyEdit, GraphicsEdit, Format, Production, and Distribution.
These states are presented only as a sample of the way in which a technical publications department might organize its process for productizing documentation. At each of these states, certain tasks can be performed on the information objects at the state. Some actions leave the information at a state, some actions move the information to another state.
Figure 11: State diagram for management.

At Authorize, for example, two actions are available (i.e., two events can occur in the lifecycle of an information object): cancel and launch project.
Cancel moves the information object to Cancelled. Launch project moves an information object from Authorize to Draft.
As with any state in a system, an organization's operating procedures may require that for an information item to be assigned to a particular state that item must have complied with certain prerequisites.
For example, assigning launch project to an information object may require that the object have a team of system users assigned to it (e.g., technical writer, editor, production supervisor, graphics artist, etc.). Such requirements can be handled in rules built into the applications that implement the models discussed here.
It may be noted that several events are available at Cancelled for moving an information object from Cancelled to such states as Draft, CopyEdit, etc. A unique event for each destination-state is required to eliminate ambiguity as to the state to which a cancelled item is to be assigned upon reactivation of the item.
Class Diagrams of States and Events
Having modeled the process of information management, we now create a model of the objects constituting the state diagram itself:
Event
State
Rumbaugh explains the difference between a state diagram for modeling "sequences of changes to objects" and the modeling of states and events:
A single object can have different states over time--the object preserves its identity--but it cannot have different classes. Inherent differences among objects are therefore properly modeled as different classes, while temporary differences are properly modeled as different states of the same class. (Rumbaugh, et al, Object-Oriented Modeling and Design, pp. 110-111.)
Technical information, as the managed object within the sample domain, corresponds to the "single object" in the foregoing excerpt. For an information management system to include events that act on that managed object, it is necessary to model the events and their associated states. Accordingly, Figure 12 presents a simple hierarchy showing the static relationship of event and state objects.
Figure 12: A simple hierarchy for events and states.
Object()
PersistentObject(creatorId, creationDate, id)
AnnotatedObject(description, name, memo, status)
Event(duration, originStateId, destinationStateId, targetCompletionDate,
templateEventId, prerequisiteEvents)
InformationEvent(informationId)
InformationState()
Object is the root class for all classes in the system.
PersistentObject provides attributes and behavior pertaining, generally, to the relationship between an object stored in memory and the data from which that object was derived (e.g., the data in a relational database). A more detailed discussion of this aspect of an information management system will appear later in this article series. Nevertheless, some discussion of the subject is necessary here because system design cannot be completed without at least some attention to data storage.
The value assigned to a PersistentObject's creatorId attribute comes from the unique key (in the database) assigned to the user responsible for creating an object. (See Figure 13.)
Figure 13: The creatorId attribute of an object in memory and its relationship to the data to which it corresponds in the database.

An instance of PersistentObject, such as a User or an Information item, is instantiated in memory. When an instance is created, values stored in the database are assigned to attributes of the memory-resident object. Figure 13 shows only the derivation of one such value, and one example of that value's use in the relationship between a memory-resident User object and a memory-resident Information object.
In the database, the unique key serves to uniquely identify a row in a table. In memory, however, the attribute to which such a value is assigned does not necessarily uniquely identify the instance of the memory-resident object. Such a value can be used to ensure that the object in memory corresponds to a particular row in a database table, but the equivalence of memory-resident objects is another matter.
Figure 13 simply shows the relationship between a cell in a database table, an attribute of a memory-resident object, and an attribute in one memory-resident object (an Information item) that refers to another memory-resident object (a User).
The creationDate is the timestamp assigned to an event or a state (i.e., to any subclass of PersistentObject) upon creation of an instance of a PersistentObject subclass.
Finally, id is a value assigned to each instance of a PersistentObject subclass. In terms of the relational database underlying the system, an id is derived from the unique key assigned to the row in a table containing the data from which the object-instance is constituted.
AnnotatedObject is an abstract superclass that adds these attributes to the hierarchy: description, name, memo, status. Description, name, and memo are text fields to be used according to policies governing the system's data integrity.
For example, the name of an InformationEvent might be "Check spelling" while the name of a State might be "Copy Edit." Other subclasses of AnnotatedObject, such as a class representing an information object might use name to contain the title of the information (which could be used as the title of a document were that information formatted for presentation as a document). An AnnotatedObject subclass representing a system user might uFr use. This is important because, in the proposed designed, neither states nor events can be deleted. Deleting a state or event would mean that associated Information items, for example, would essentially be lost. The capability of assigning "Active" or "Inactive" as status values preserves required associations among database entities while disabling use of the state or event.
Event is an abstract superclass for events available for assignment to information objects. The design proposed in this article suggests that a subclass of Event be created for each object to be managed within the system. For example, information is the object to be managed by the kind of process described in Figure 11; however, the creation of user accounts, assignment of rights, etc., constitutes another process that would need to be modeled. And for that process, a user object would be the object managed. Thus, in terms of the class hierarchy presented here, UserEvent would need to be added as a subclass of Event so that management of user objects could be included in the system.
The attributes of Event include:
duration
originStateId
destinationStateId
targetCompletionDate
templateEventId
prerequisiteEvents
The duration and targetCompletionDate attributes contain values specific to each InformationEvent. The duration, for example, would record the length of time taken by an InformationEvent, and targetCompletionDate would contain a timestamp assigned for Event completion.
The originStateId is the unique key, in the State table, of the state at which an Event can occur (i.e., at which an Event can be assigned to an information item).
The destinationStateId is the unique key, in the State table, of the state to which an Event moves a managed object.
Finally, prerequisiteEvents holds on to a collection of events that must have been assigned to an instance of a ManagedObject before a particular Event can be assigned to the instance of ManagedObject.
InformationEvent adds to the hierarchy a single attribute, informationId, for the purpose of associating a particular event with a particular Information object.
The proposed design, presented graphically in Figure 14, would require that for each kind of object to be managed within the system (such as Information, User, etc.), tables similar to those associated with Information in Figure 14 would need to be created.
For example, were it necessary to manage User objects in the manner in which Information objects are managed, the following tables would need to be created for User:
User_Event
User_State
User_Event_Template
Prerequisite_User_Events
The foregoing tables would have the same relationships among themselves, and to the User table, reflected in Figure 14 for Information.
Figure 14: Simple database schema for states, events, and information.
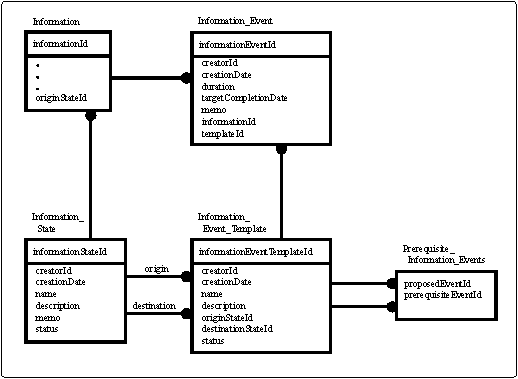
Figure 14 shows the relationship among the database tables for the data from which information related state and event objects are constituted. The diagrammatic presentation in Figure 14 is necessary in explaining the need for the templateEventId attribute of Event. The schema appearing in Figure 14 enables the database to store every InformationEvent assigned to an information object.
The schema presented in Figure 14 does not address performance-related issues that must be addressed in application implementation. Such issues are outside the scope of this article. The purpose of the sample schema is to illustrate, in the simplest terms possible, the kind of relational database schema that may be needed in supporting an implementation of a state-transition model.
The Information_Event_Template table contains data common to each kind of information event. The Information_Event table contains data describing each event associated with Information items. For example, the "Request copy edit" event (see Figure 11) would have a name, description, originStateId, distributionStateId, and status common to all instances of that event throughout the system; however, the duration of a particular instance of that event must vary from instance to instance. The proposed schema stores data common to each event in an Information_Event_Template table, and stores instance-specific data in an Information_Event table.
The class hierarchy presented in Figure 12 does not mirror the relational schema in Figure 14-the class hierarchy does not present a one-to-one class-to-table correlation.
For example, data from both the Information_Event_Template and Information_Event tables are used to instantiate an InformationEvent object. In terms of the class hierarchy presented in Figure 12, the value assigned to templateId in the Information_Event table is the value that gets assigned to the InformationEvent(templateEventId) object. Thus, templateEventId is the informationEventTemplateId in the Information_Event_Template table whose associated row was used to constitute a particular InformationEvent object.
Figure 14 also presents an Information_State table in which each row contains data by which an InformationState object is defined. The Prerequisite_Information_Events table is discussed later in this article.
State adds no attributes to the class hierarchy. However, Figure 14 indicates that the Information_Event_Template table contains two state-related attributes: destinationStateId, originStateId.
Each state can be the destination for one or more events. For example, in Figure 11, the Copy Edit state is the destination state for the following events:
Request copy edit
Reactivate to Copy Edit
Complete copy edit
Check spelling
Check grammar
Check usage
A destination state is the state to which an event moves a managed object.
A state of origin is the state from which an event moves a managed object. The state of origin may be thought of as the state at which an event can occur.
The following list can be compared with corresponding states and events in Figure 11:
|
Event
|
Stateof Origin
|
DestinationState
|
|
Request copy edit |
Draft |
CopyEdit |
|
Reactivateto Copy Edit |
Cancelled |
CopyEdit |
|
Complete copy edit |
GraphicsEdit |
CopyEdit |
|
Check spelling |
CopyEdit |
CopyEdit |
|
Check grammar |
CopyEdit |
CopyEdit |
|
Check usage |
CopyEdit |
CopyEdit |
Figure 15 presents an inheritance class diagram for the object hierarchy just described. Figure 15 is a graphic rendering of the hierarchy presented in Figure 12.
The proposed model for state-transition functionality within an information management system can be generalized to apply to almost any process.
Furthermore, the proposed architecture focuses to a greater or lesser degree on these general objectives:
Allow states to be added to or removed from the system without interrupting production (i.e., without requiring re-coding, -compiling, and -releasing the management application).
Allow the configuration of states to change (e.g., change the destination state for an event).
Add or remove events without interrupting workflow.
Rename states or events without interrupting workflow.
Allow domain experts, as opposed to engineers, to make the foregoing changes. In other words, not only must changes be made without re-coding, -compiling, and -releasing the application, but system users must be able to make changes "on the fly" as their process changes.
Enable system users to view an information object's action history.
Figure 15: Class diagram-inheritance.

Event Agents
Booch talks about conditional state transition:
Generally, a given state transition will either have an event or an event and a condition. We also permit a state transition to have no associated event. In such a case, the transition is triggered immediately after the action of the source state has completed; exit actions are also carried out as a consequence. If the state transition is conditional, then the transition will be triggered only if the expression evaluates true. (Booch, Grady. Object-Oriented Analysis and Design with Applications , pp. 204, 205.)
In terms of our hypothetical information management system, the Request copy edit event moves an information object from the Draft state to the Copy Edit state. The policies and procedures of the technical documentation department, however, may require that before an information item can be assigned to the Copy Edit state, the following events must have occurred (see Figure 11):
Launch project
Research
Rough draft
Request engineering review
Request technical corrections
Request QA
Request QA corrections
The transition from the Draft state to the Copy Edit state is, therefore, conditioned upon whether the foregoing events have been associated with the information object being assigned to Copy Edit. The application that implements the process model must audit events assigned to an information object in order to verify that the object is ready for copy editing.
To incorporate this functionality into our hypothetical information management system, this article proposes a class of EventAgent objects:
Objec t() EventAgent(event, managedObjectClass) InformationEventAgent()
A hierarchy this deep would be necessary only were the application to be used to manage objects other than information (e.g., user objects). Furthermore, an InformationEventAgent class would be necessary only if there were multiple information events that each required its own agent. For example, if the transition from the Draft state to the Copy Edit state requires behavior unique to that transition, a final subclass could be added to the foregoing hierarchy:
Object() EventAgen t(event, managedObjectClass) InformationEventAgent() RequestCopyEditAgent()
When an event is instantiated, an event agent must be assigned to it. This means that the class hierarchy for InformationEvent (see Figure 12) must be modified to include one more attribute: agent. The modified hierarchy appears in Figure 16.
Figure 16: A modified hierarchy for events and states.
Object()
PersistentObject(creatorId, creationDate, id)
AnnotatedObject(description, name, memo, status)
Event(agent, duration, originStateId, destinationStateId, targetCompletionDate,
templateEventId, prerequisiteEvents)
InformationEvent(informationId)
InformationState()
An information event for moving an information object from the Draft state to the Copy Edit state, might be instantiated with the following values:
|
InformationEvent
|
Description
|
|
creatorId |
IDof user attempting to assign the event to an instance of Information. |
|
creationDate |
Dateand time of attempt to assign the event. |
|
id |
Uniquekey of row in Information_Event table. |
|
description |
Textdescribing event. |
|
name |
Textconstituting event's name. |
|
memo |
Textcontaining user's comments concerning event. |
|
status |
Textindicating whether or not the event is activeor inactive (i.e., available for assignment). |
|
agent |
Aninstance of RequestCopyEditAgent. |
|
duration |
A period of time. |
|
originStateId |
TheoriginStateId in Information_Event_Template table. |
|
destinationStateId |
ThedestinationStateId in Information_Event_Template table. |
|
targetCompletionDate |
Dateand time assigned for event completion. |
|
templateEventId |
Uniquekey assigned to row, in Information_Event_Templatetable, containing the data used as the templatefor this informationEvent. |
The remainder of this section focuses on the agent assigned to an InformationEvent.
Thus far, we have focused on inheritance of data via attributes belonging to classes within a hierarchy. We now consider inheritance of behavior, and begin by discussing the assignEvent: method implemented in the Information hierarchy. Figure 17 presents a simplified version of this hierarchy.
Figure 17: Simplified Information hierarchy.
Object()
PersistentObject(creatorId, creationDate, id)
AnnotatedObject(description, name, memo, status)
ManagedObject()
Information()
The assignEvent: method is invoked when an Event is to be assigned to an instance of Information. For example, an information object at Authorize (see Figure 11) might be assigned the Launch project event in order to move the information object to the Draft state. Assignment of that event might involve the behavior implemented in Code Listing 1. In Code Listing 1, as well as in other code listings in this article, Sample A presents a Java language implementation while Sample B presents a Smalltalk implementation of the same behavior.
Code Listing 1: Behavior for assigning an event object to an information object
Sample A: Java implementation
assignEvent ( anEvent ) {
/* declare aDiagnostic to be of type Diagnostic and initialize it to the
results of anEvent.qualifyOn ( this ) this is a reference to the current
object, similar to Smalltalk's self. It is implied in Java -- any
function call refers to the current object unless otherwise stated..*/
Diagnostic aDiagnostic = anEvent.qualifyOn ( this );
if (aDiagnostic.status) addEvent ( anEvent )
else raiseErrorOn ( aDiagnostic );
}
Sample B: Smalltalk implementation
assignEvent: anEvent
| aDiagnostic |
aDiagnostic := anEvent qualifyOn: self.
aDiagnostic status
ifTrue: [
self addEvent: anEvent
]
ifFalse: [
self raiseErrorOn: aDiagnostic
].
In the assignEvent: method, a temporary variable is created for the purpose of holding on to the result of:
anEvent qualifyOn: self
Self is the instance of Information performing the assignEvent: method. The qualifyOn: message names behavior provided by anEvent.
The assignEvent: method assumes that an Event qualifyOn:self returns aDiagnostic. Once returned, the status of aDiagnostic is evaluated. If the status evaluates true, the information object performs its addEvent: method, if the status of the returned diagnostic is false, the information object performs its raiseErrorOn: method.
Figure 18 presents an Object Message Diagram that may be helpful in understanding the relationships between the objects and messages described in this section. In terms of the objects represented in Figure 18, Event exists primarily for the purpose of modeling the events that transition an information item from one state to another. The Diagnostic object exists for two purposes: reporting status and minimizing database accesses.
This latter purpose is not addressed in this article; therefore, the existence and use of a Diagnostic object may appear superfluous. That appearance is relative only to the scope of this article, not to the scope of the system generally. Agent exists for the purpose of implementing policies and procedures that are not modeled by Event or State. Thus, a request originating with Information is passed from Information to Event and from Event to Agent.
Figure 18: Object Message Diagram for event assignment.

Event implements qualifyOn: in the manner presented in Code Listing 2.
Code Listing 2: Behavior for qualifying an event object's assignment to an information object.
Sample A: Java implementation
qualifyOn ( aManagedObject ) {
aDiagnostic = Diagnostic.newOn ( aManagedObject );
return agent.qualifyAssignmentOn ( aDiagnostic );
}
Sample B: Smalltalk implementation
qualifyOn: aManagedObject
| aDiagnostic |
aDiagnostic := Diagnostic newOn: aManagedObject.
^self agent qualifyAssignmentOn: aDiagnostic
In the text of the method presented in Code Listing 2, aDiagnostic is created as a temporary variable. The contents of that temporary variable are then passed on to the Event's agent via that agent's qualifyAssignmentOn: method. Unless a subclass of Event needs to re implement a qualifyOn: method, the foregoing behavior can be used by any of Event's subclasses. By passing the request for qualification on to an agent, Event remains free of information and behavior associated with qualification. This means that states and events can be constituted exclusively from database values, at least in terms of the qualification described in this article.
EventAgent implements the version of the qualifyAssignmentOn: method presented in Code Listing 3. The first version of the method presented in Code Listing 3 is simplified in that the only qualification performed determines whether the class (or type) of the ManagedObject is appropriate for the Event to be assigned to an instance of ManagedObject. A more involved version of this method is presented later.
Code Listing 3: An agent's behavior for qualifying the assignment of an event.
Sample A: Java implementation
qualifyAssignmentOn: aDiagnostic {
return qualifyOnManagedObjectClass ( aDiagnostic )
}
Sample B: Smalltalk implementation
qualifyAssignmentOn: aDiagnostic
^self qualifyOnManagedObjectClass: aDiagnostic
The behavior provided in qualifyOnManagedObjectClass: could have been implemented in the qualifyAssignmentOn: method; however, by having the class evaluation performed in a separate method, subclasses of Agent can re implement a qualifyAssignmentOn: method and selectively invoke inherited behavior.
Agent's qualifyOnManagedObjectClass: method provides the behavior presented in Code Listing 4:
Code Listing 4: Qualifying an event assignment based on the class of the managed object.
Sample A: Java implementation
qualifyOnManagedObjectClass ( aDiagnostic ) {
If ( !( ( aDiagnostic.managedObject () ).isKindOf ( managedObjectClass() ) ) )
aDiagnostic.fail();
return aDiagnostic;
}
Sample B: Smalltalk implementation
qualifyOnManagedObjectClass: aDiagnostic
(aDiagnostic managedObject isKindOf: self managedObjectClass)
ifFalse: [
aDiagnostic fail
].
^aDiagnostic
In Code Listing 4, a single test is performed to determine whether the ManagedObject assigned to aDiagnostic is the kind of ManagedObject on which the agent is supposed to act. In other words, when an Agent is created, a class is assigned to its managedObjectClass attribute. In the foregoing method, if the class assigned to an Agent's managedObjectClass is the kind of class to which aDiagnostic's managedObject belongs, aDiagnostic whose status is true is returned as the result of the evaluation.
Otherwise, aDiagnostic is set to false (via a fail method implemented in the Diagnostic hierarchy) and then aDiagnostic is returned. (The status of aDiagnostic is set to true when aDiagnostic is created, and is changed only via its fail method.)
This discussion of qualifyAssignmentOn: presents behavior provided by EventAgent. Such behavior may not be sufficiently specific to an Event; therefore, it may be necessary to re implement the behavior in a subclass of Event. For example, RequestLaunchAgent might provide the implementation of the qualifyAssignmentOn: method that appears in Code Listing 5:
Code Listing 5: Adding qualifications to qualifyAssignmentOn:
Sample A: Java implementation
qualifyAssignmentOn
( aDiagnostic ) {
if (( qualifyOnManagedObjectClass ( aDiagnostic ) ).status())
qualifyEventOnHistory ( aDiagnostic );
return aDiagnostic;
}
Sample B: Smalltalk implementation
qualifyAssignmentOn: aDiagnostic
(self qualifyOnManagedObjectClass: aDiagnostic) status
ifTrue: [
self qualifyEventOnHistory: aDiagnostic
].
^aDiagnostic
In the qualifyAssignmentOn: method text, two evaluations are performed. The first evaluation, performed in the qualifyOnManagedObjectClass: method, invokes behavior inherited from the Agent's superclass. (Recall that in discussing Event's implementation of the qualifyAssignmentOn: method, we pointed out that by having each evaluation in its own method, a subclass might selectively invoke inherited behavior.)
The qualifyOnHistory: method is, in this example, implemented in the RequestCopyEditAgent and provides the behavior presented in Code Listing 6. (Note, however, that the method text is provided only as a sample of the kind of event-specific checking that may be necessary. The method is not written with any view toward performance considerations, iterating across collections, etc.)
Code Listing 6: Sample behavior for qualifying an event assignment based on the history of a managed object.
Sample A: Java implementation
qualifyOnHistory ( aDiagnostic ) {
int i; // loop index
OrderedCollection prerequisiteEventNames = new OrderedCollection();
for ( i = 0; i < event.prerequisiteEvents.length(); i++ )
prerequisiteEventNames.add( event.prerequisiteEvents[i].name );
for ( i = 0; i < aDiagnostic.managedObject.events.length(); i++ )
if ( prerequisiteEventNames.includes (
aDiagnostic.managedObject.events[ i ].name ))
prerequisiteEventNames.remove ( aDiagnostic.managedObject.events[ i ].name );
If ( prerequisiteEventNames.length() > 0 )
aDiagnostic.fail();
return aDiagnostic;
}
Sample B: Smalltalk implementation
qualifyOnHistory: aDiagnostic
| prerequisiteEventNames |
prerequisiteEventNames := OrderedCollection new.
self event prerequisiteEvents do: [ :anEvent |
prerequisiteEventNames add: anEvent name
].
aDiagnostic managedObject events do: [ :anEvent |
(prerequisiteEventNames includes: anEvent name)
ifTrue: [
prerequisiteEventNames remove: anEvent name
].
].
prerequisiteEventNames isEmpty
ifFalse: [
aDiagnostic fail
].
^aDiagnostic
In the method text for qualifyOnHistory:, the events assigned to an information object already are evaluated to determine whether at least one instance of each required event has been assigned to the information object. Upon finding any required event absent, the method returns a diagnostic whose status is false. Otherwise, the status of aDiagnostic remains unchanged and aDiagnostic is returned.
Such methods enable an information management system to qualify the proposed assignment of an Event on any bases. This is the mechansim by which a system can implement policies and procedures governing transitions from one state to another, or assignment of events that leave an information object in its current state.
Bibliography
Booch, Grady. Object-Oriented Analysis and Design with Applications. The Benjamin/Cummings Publishing Company, Inc., 1994.
Booch, Grady, et al. Unified Method: Notation Summary Version 0.8. Rational Software Corporation, 1995.
Rumbaugh, James, et al. Object-Oriented Modeling and Design, Prentice Hall, 1991.
* Originally published in Novell AppNotes
Disclaimer
The origin of this information may be internal or external to Novell. While Novell makes all reasonable efforts to verify this information, Novell does not make explicit or implied claims to its validity.