How to Audit DirXML Events Using Stylesheets, Java, and JDBC
Articles and Tips: article
Senior Software Engineer
Novell Developer Solutions
kbunnell@novell.com
01 Feb 2002
This AppNote is the last in a series on advanced DirXML stylesheet authoring techniques. It describes mechanisms that allow DirXML event data to be "captured", analyzed, and recorded to a database using XSLT stylesheets, Java, and JDBC.
The previous AppNote in this series is "How to Implement Complex Business Rules Using DirXML Stylesheets and Java" in the January 2002 issue, available online at http://support.novell.com/techcenter/articles/ana20020103.html.
- Introduction Introduction
- Auditing Business Rule Transactions Within a Stylesheet
- Using Stylesheets to Capture Event Data for Auditing
- Using Java and Document Object Model APIs to Extract Event Data
- Conclusion
|
Topics |
DirXML, Novell eDirectory, XML, XSLT, Java |
|
Products |
Novell eDirectory, DirXML |
|
Audience |
Network administrators, programmers |
|
Level |
advanced |
|
Prerequisite Skills |
Java, JDBC, XML and XSLT proficiency |
|
Operating System |
NetWare 5.x, Windows NT or 2000 |
|
Tools |
none |
|
Sample Code |
yes |
Introduction
DirXML makes automated account provisioning a reality. However, the ability to audit the flow of business rule execution as data flows through the system and generate detailed reports of this activity is key to ensuring that business logic is being executed efficiently, accurately and in accordance with corporate standards. By providing fine-grained auditing of key event data to an RDBMS, corporate business architects can build detailed reports that allow them to evaluate the success of business logic execution, identify trends that may cause inefficiencies, and monitor key events that have security implications.
This AppNote outlines mechanisms that allow DirXML event data to be "captured", analyzed, and recorded to a database using XSLT stylesheets, Java, and JDBC (Java Database Connectivity).
Note: A complete functioning DirXML driver, associated stylesheets, and all the Java classes (including source code) described in this AppNote are available for download at http://www.novell.com/coolsolutions/tools/13808.html. A pure-Java RDBMS and associated JDBC driver are also included in order to demonstrate a complete, functioning system. Download the file named AuditDxmlDrv.zip, extract the contents of the archive, and follow the instructions outlined in the included README.TXT file to install and configure the example auditing/reporting system.
Auditing Business Rule Transactions Within a Stylesheet
The DirXML engine provides a built-in logging facility that allows DirXML drivers and stylesheets to log information to a DirXML log file. However, all event information is combined together in a text file in a proprietary format which makes it difficult to interpret and impossible to use as an effective auditing/reporting mechanism.
Fortunately, the extensibility of DirXML stylesheets allow any data that flows through the system, whether it be through the publisher or subscriber channels, to be passed to a Java class and submitted to a relational database using JDBC and SQL. XPath can be used to extract the data of interest from the source document. Java/JDBC is used to insert a snapshot of this data in a table that can be used to audit the flow of business logic execution.
To illustrate how such a system might be used, let's take a look at some real-world business logic and how such a system of logging event data for auditing purposes might work. Suppose you've been given the task to ensure that when a new User object is created in Novell eDirectory (via the publisher channel), it includes values for the "Manager" and "Assistant" attributes to identify the user's manager and administrative assistant.
These attributes have the "Distinguished Name" syntax, which means the values of these attributes must be the full distinguished name of the "Manager" and "Assistant" objects (for example, cn=Jsalvo.ou=Engineering.o=Novell). This is required to support a corporate organization chart that allows users of the application to click on the "Manager" or "Assistant" links and navigate to the corresponding object in eDirectory. ConsoleOne includes such an organizational chart (see Figure 1).
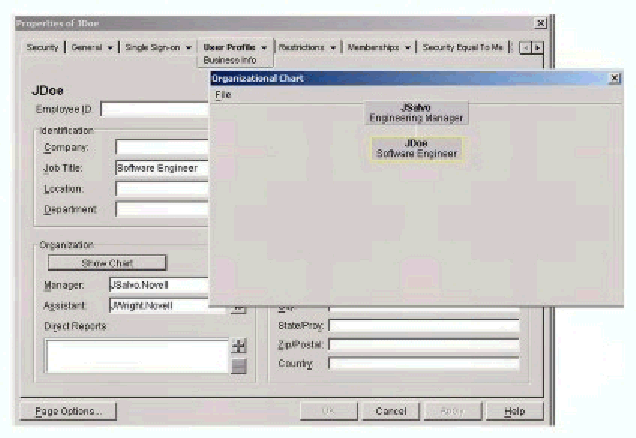
Organizational Chart included with ConsoleOne.
The problem is, how do you supply the eDirectory distinguished name (DN) for the "Manager" and "Assistant" attributes when the <add> document includes only the workforce (employee) ID for these users?
To accomplish this task, the publisher "Create Rule" must include logic that queries eDirectory using the manger and assistant IDs to retrieve the corresponding distinguished names. The returned distinguished names are then added to the source <add> document using the <add-attr> tags.
This all works nicely if the "Manager" and "Assistant" objects exist in eDirectory. If one of the objects is missing, the attribute cannot be added to the <add> document and the Organizational Chart will be incomplete. In order to track the instances where the Manager or Assistant objects do not exist in eDirectory, it is necessary to audit this query transaction so these failures can be reported and resolved.
The sample demonstrates a Create Rule style sheet that extracts the manager ID from the source document, queries eDirectory for the corresponding manager DN, logs a failure if no results are returned from the query and finally adds an attribute to the <add> document that contains the manager DN if the query for the manager DN succeeds.
Note: The code that adds the DN value for assistant has been omitted to conserve space.
01 <xsl:template match="add">
02 <!-- ensure we have required NDS attributes we need for the name -->
03 <xsl:if test="add-attr[@attr-name='Surname'] and add-attr[@attr-name='Given
Name']">
04 <!-- copy the add through -->
05 <xsl:copy>
06 <xsl:variable name="manager-id"
select="hrxyz:policy-attr[@hrxyz:attr-name='Manager ID'] /hrxyz:value"/>
07 <!-- search for manager, retrieve DN if exists and store in manager
attribute. -->
08 <xsl:if test="string-length($manager-id) !=0">
09 <xsl:variable name="foundMgrDN">
10 <xsl:call-template name="query-dn">
11 <xsl:with-param name="workforce-id" select=
"$manager-id"/>
12 </xsl:call-template>
13 </xsl:variable>
14 <xsl:choose>
15 <xsl:when test="string-length($foundMgrDN) != 0">
16 <add-attr attr-name="manager">
17 <value type="dn">
18 <xsl:value-of select="$foundMgrID"/>
19 </value>
20 </add-attr>
21 </xsl:when>
22 <xsl:otherwise>
23 <!-- Query for Manager association (id) returned
no results
so log to RDMBS -->
24 <xsl:variable name="type-mgr">Manager</xsl:variable>
25 <xsl:call-template name="audit-event">
26 <xsl:with-param name="missing-id" select=
"$manager-id"/>
27 <xsl:with-param name="empl-id" select=
"association"/>
28 <xsl:with-param name="id-type" select="$type-mgr"/>
29 </xsl:call-template>
30 </xsl:otherwise>
31 </xsl:choose>
32 </xsl:if>
33 </xsl:copy>
34 </xsl:if>
35 </xsl:template>
36 <!-- Build and Submit Query document -->
37 <!-- Query for objects with an association-->
38 <!-- that matches the supplied employee ID -->
39 <xsl:template name="query-dn">
40 <xsl:param name="workforce-id"/>
41 <!-- build an xds query as a result tree fragment -->
42 <xsl:variable name="query">
43 <nds dtdversion="1.0" ndsversion="8.5">
44 <input>
45 <query scope="subtree">
46 <association>
47 <xsl:value-of select="$workforce-id"/>
48 </association>
49 <read-attr/>
50 </query>
51 </input>
52 </nds>
53 </xsl:variable>
54 <!-- query NDS -->
55 <xsl:variable name="result"
select="query:query($destQueryProcessor,$query)"/>
56 <!-- return an empty or non-empty result tree fragment depending on
result of query -->
57 <xsl:value-of select="$result//instance/@src-dn"/>
58 </xsl:template>
The technique for adding the "Assistant" attribute is identical to the mechanism presented in the code listing above. Let's analyze how this is done.
Beginning on line 06, the Manager ID value is extracted from the source <add> document and stored in an XPath variable named "manager-id". In lines 09-13, an XPath variable named "foundMgrDN" is populated with the manager DN by calling a template named "query-dn" (lines 39-58). The "query-dn" template accepts the "manager-id" value in a parameter named "workforce-id" (line 40).
The query for manager DN is composed on lines 43-52 by building a result tree fragment that, once submitted to the DirXML engine via the query processor, will return all objects that have an association that matches the value of the manager ID. If a result is returned from the query, the manager object was found and the DN is returned; otherwise, a zero-length string will be returned.
Notice the use of the XSLT <xsl:choose> instruction (lines 14-31) which allows you to define a choice between a number of alternatives. Immediately beneath the <xsl:choose> node resides one or more <xsl:when> instructions that define one "choice" based on the outcome of the "test" expression (line 15). The final "choice", if none of the <xsl:when> expressions evaluate to true, is determined by the <xsl:otherwise> instruction.
You Java, C, or C++ programmers will recognize the similarity of these "choose-when" instructions to the "switch-case" instructions found in these programming languages. The choose-when/otherwise instructions provide a perfect mechanism to determine if the query for the manager or assistant DN was successful (that is, when the foundMgrDN length is greater than zero) and provide a different execution path based on the outcome of this logic. If the manager DN is found and therefore <xsl:when> expression evaluates to true, the manager DN is added to the <add> document (lines 16-20).
The <xsl:otherwise> instruction is reached in the event that the query yielded no instances of the manager object within eDirectory (that is, when the call to the query-dn template returns empty string). Here is where we need to audit the outcome of this transaction so that this failure can be quickly identified and resolved. This is accomplished by calling a template named "audit-event".
The "audit-event" template is passed three parameters that contain the workforce ID, the user's association value (workforce ID), and the workforce ID type (manager or assistant). This is enough information to identify the user for which a manager DN does not exist.
A sample "audit-event" template is shown in the following listing.
01 <xsl:template name="audit-event" xmlns:dxmlAudit="http://www.novell.com/nxsl
/java/com.novell.appnote.util.DxmlAudit">
02 <xsl:param name="missing-id"/>
03 <xsl:param name="empl-id"/>
04 <xsl:param name="id-type"/>
05 <xsl:variable name="dxmlAuditInstance" select="dxmlAudit:new() "/>
06 <xsl:variable name="result" select="dxmlAudit:log($dxmlAuditInstance,
$missing-id, $empl-id,$id-type )"/>
07 <xsl:copy-of select="$result"/>
08 </xsl:template>
This template accepts the data we want to log to the database as parameters (lines 02-04), instantiates a Java class named com.novell.appnote.util.DxmlAudit (line 05), and invokes the "log" method of this class with these parameters (line 06).
Let's take a closer look at the log() method of the DxmlAudit Java Class that is invoked from this stylesheet.
01 public void log(String missId, String emplId, String idType) {
02 try {
03 java.sql.Date ts = new java.sql.Date(System.currentTimeMillis());
04 // Create a Statement object.
05 PreparedStatement ps = connection.prepareStatement("INSERT INTO
Missing_Id ( missing_id, empl_id, id_type, time_stmp ) VALUES ( ?, ?,
?, ? )");
06 ps.setString(1, missId);
07 ps.setString(2, emplId);
08 ps.setString(3, idType);
09 ps.setDate(4, ts);
10 ps.executeUpdate();
11 ps.close();
12 }
13 catch (SQLException e) {
14 System.out.println("An error occured\n" +
"The SQLException message is:
" + e.getMessage());
15 }
16 }
The log method accepts the three parameters passed to it as invoked from the audit-event template in the stylesheet, builds a JDBC-prepared statement (line 05) to insert the supplied data into the Missing_Id table, and issues an update to insert the new row into the database (line 10).
The following Java/JDBC code can be used to retrieve all rows in the database in chronological order of all employees for which the query for manager or assistant DN failed:
statement.executeQuery("SELECT * FROM Missing_Id ORDER BY time_stmp");
The result set of the query could then be printed to the console as follows:
Wed Oct 31 12:39:14 MST 2001 Missing: 2001 Type: Manager For Employee: 8001 Wed Oct 31 12:39:14 MST 2001 Missing: 3001 Type: Admin For Employee: 8001
The result of this SQL query indicates that the business logic within the stylesheet that queries eDirectory (query-dn template) for the manager and administrative assistant objects failed to return any entries for the user with workforce ID 8001. The use of JDBC and SQL allows the IS staff to quickly identify and resolve the cause of failed links within the corporate organizational chart.
While this is a simplistic example, it demonstrates the power of using the combination of XSLT, Java, and JDBC to audit individual business rule transactions executed with a DirXML style sheet. More sophisticated reporting would involve the use of an SQL reporting tool to track, in real time, business rule execution within the stylesheet, such as the number of name collisions generated while executing the logic that implements the corporate naming policy, or the result of the user password generated by the corporate password policy (be careful with this one-it may violate your corporate security policy).
Thanks to the extensibility of DirXML stylesheets, the possibilities for fine-grained auditing and reporting of business rule transactions are limited only by your imagination.
Using Stylesheets to Capture Event Data for Auditing
In the previous section, we discussed how to use XSLT conditional instructions and Java extension functions to audit the outcome of specific business logic (mapping an manager/assistant by workforce ID to their corresponding DN within eDirectory) implemented in the Create Rule stylesheet. In this section, we'll look at a different approach.
Suppose you've been asked to audit specific change events that occur to objects of a specific class within eDirectory, and to do so without implementing the logic within the stylesheet. For example, suppose you've been given the assignment to audit the login time of users to eDirectory, as well as when objects are either added to or deleted from eDirectory. You need to devise a mechanism that can be added to any existing DirXML driver and do so with minimal change to existing stylesheets. Since you are interested in auditing changes to eDirectory, you need to implement changes to a stylesheet in the subscriber channel.
To accomplish that objective, you need to capture the eDirectory event data as it flows out the subscriber channel, pass it along to a Java class to extract the data of interest, and forward the data unmodified so the DirXML driver subscription shim can process the event.
Following is an XSLT stylesheet added as the "DirXML-EventTransformationRule" of the DirXML "Subscriber" object.
01 <?xml version="1.0" encoding="UTF-8"?>
02 <xsl:transform version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
03 <!-- This is for testing the stylesheet outside of DirXML so things are
pretty to look at -->
04 <!-- match all elements -->
05 <xsl:template match="/">
06 <!-- copy through -->
07 <xsl:variable name="event">
08 <xsl:copy>
09 <xsl:apply-templates select="@* | * | comment() |
processing-instruction() | text()"/>
10 </xsl:copy>
11 </xsl:variable>
12 <!-- Call template and pass current document -->
13 <xsl:call-template name="audit-event">
14 <xsl:with-param name="event-data">
15 <xsl:copy-of select="$event"/>
16 </xsl:with-param>
17 </xsl:call-template>
18 <!-- Copy contents through so subscription shim can process it -->
19 <xsl:copy>
20 <xsl:copy-of select="$event"/>
21 </xsl:copy>
22 </xsl:template>
23 <xsl:template name="audit-event"
xmlns:dxmlAudit="http://www.novell.com/nxsl/java/
com.novell.appnote.util.DxmlAudit">
24 <xsl:param name="event-data"/>
25 <!-- copy event data to a variable -->
26 <xsl:variable name="event-doc">
27 <xsl:copy-of select="$event-data"/>
28 </xsl:variable>
29 <xsl:variable name="dxmlAuditInstance" select="dxmlAudit:new() "/>
30 <xsl:message>**** Calling dxmlAudit:log method ******</xsl:message>
31 <xsl:variable name="result" select="dxmlAudit:log($dxmlAuditInstance,
$event-doc )"/>
32 <xsl:copy-of select="$result"/>
33 </xsl:template>
34 <!-- Template for everything else. -->
35 <xsl:template match="@*|node()">
36 <xsl:copy>
37 <xsl:apply-templates select="@*|node()"/>
38 </xsl:copy>
39 </xsl:template>
40 </xsl:transform>
This stylesheet defines a template that matches all documents (line 05), copies the entire source document as a result tree fragment into an XPath variable named "event" (lines 07-11), and calls a template named "audit-event" (lines 13-17) that accepts this XPath variable as a passed parameter (lines 23-39).
The "audit-event" template (lines 23-39) copies the source document from the "event-data" parameter (line 24) into an XPath variable named "event-doc" (lines 26-28). This ensures that the passed document is in the form of a result tree fragment.
Finally, a Java method "log" of the com.novell.appnote.util.DxmlAudit class is invoked (line 31) and the source document is passed to the "log" method as a result tree fragment in the "event-doc" XPath variable.
Notice that the source XML document is copied, unmodified, to the output of the result document for processing by the subscriber shim (lines 19-21). The stylesheet simply provides a way to extract the source document and pass it to a Java class for auditing purposes. The original source document is sent along to the subscription shim unmodified for processing by the driver.
To summarize, a DirXML stylesheet object is added as the DirXML-EventTransformationRule attribute of the DirXML "Subscriber" object. This can be accomplished by using ConsoleOne (see Figure 2).
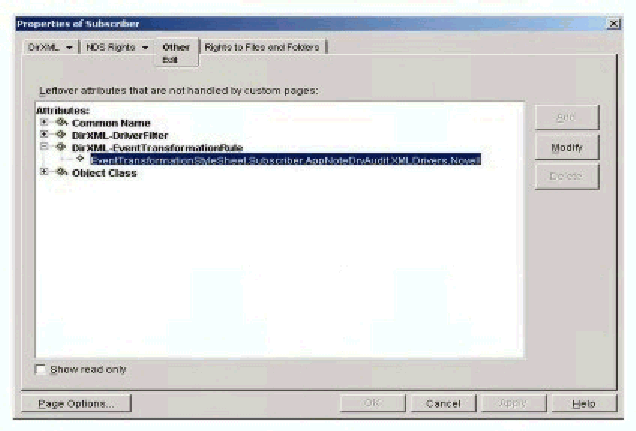
Adding a stylesheet object as an Event Transformation Rule.
The stylesheet is applied as the change event document is sent from the DirXML engine to the subscriber shim. The stylesheet "captures" the source document, passes it as a result tree fragment to a Java class, and forwards the original source document unmodified to the DirXML driver for processing.
This accomplishes our objective of extracting a source document for auditing purposes. However, now that the Java class has been passed a copy of the source document, how does it process it? We'll explore this in detail in the next section.
Using Java and Document Object Model APIs to Extract Event Data
In the previous section we discussed how to capture the source document and pass it as a result tree fragment to a Java class. The source code for the "log" method invoked within the stylesheet is as follows (error handling is minimized to conserve space):
01 public void log(com.novell.xsl.process.ResultTreeFragment doc) {
02 try {
03 Document nds = getDocumentFromResultTree(doc);
04 Element input = (Element)nds.getElementsByTagName("input").item(0);
05 if (input == null)
06 //iterate through the children, dispatching commands
07 Node childNode = input.getFirstChild();
08 while (childNode != null)
09 {
10 if (childNode.getNodeType() == Node.ELEMENT_NODE)
11 {
12 dispatch((Element)childNode);
13 }
14 childNode = childNode.getNextSibling();
15 }
16 } catch (Exception e) { }
17 }
In the previous article in this series (see "How to Implement Complex Business Rules Using DirXML Stylesheets and Java" in the January 2002 issue), we discussed how XPath variable data types are coerced to Java data types when invoking a Java method from a stylesheet. The above code demonstrates how to accept the XPath variable as a Java object class of type com.novell.xsl.process.ResultTreeFragment.
So what is a ResultTreeFragment and what can you do with it? If you take a look at the definition provided by the "XSL Transformations (XSLT) Version 1.0" specification (see http://www.w3.org/TR/xslt), a result tree fragment is described as follows:
"A result tree fragment represents a fragment of the result tree."
Not too helpful, is it? It also states the following:
"A variable may be bound to a result tree fragment instead of one of the four basic XPath data-types (string, number, boolean, node-set)".
The things you can do with a result tree fragment are rather limited. It can be converted to a string or it can be passed as a result to the final result tree. The Java class ResultTreeFragment is constructed from the passed XPath result tree fragment and provides methods to convert the contents to a string or one of the Java native types if possible.
For purposes of our sample application, it would be nice to operate on the result tree fragment using the Document Object Model (DOM) API, as parsing the string could be very inefficient and difficult. The DOM API is defined as a programming interface specification being developed by the World Wide Web Consortium (W3C) that lets a programmer create and modify XML documents as full-fledged program objects.
Suppose you wanted to operate on a result tree fragment such as the following:
<nds dtdversion="1.0" ndsversion="8.5">
<source>
<product version="1.0">DirXML</product>
<contact>Novell, Inc.</contact>
</source>
<input>
<add class-name="User" event-id="0" src-dn="\KBEDIR2-TREE\Novell\Admin"
src-entry-id="32819">
<association state="pending"></association>
<add-attr attr-name="Network Address">
<value timestamp="1008091873#3" type="structured">
<component name="netAddrType">9</component>
<component name="netAddr">BwGJQYoV</component>
</value>
<add-attr attr-name="Last Login Time">
<value timestamp="1008285212#1" type="time">1008284581</value>
</add-attr>
</add>
</input>
</nds>
It would be much easier to traverse the document as Java objects rather than trying to parse it as a string. Fortunately, the DOM API included with the DirXML engine libraries includes Java classes for converting an XML document represented as a string to a DOM Document represented as Java objects.
Notice on line 03 of the "log" method above that there is a method that accepts a ResultTreeFragment as an input argument and returns an object of type "Document". Following is the Java source code for the getDocumentFromResultTree() method that converts the ResultTreeFragment to a DOM document:
01 public Document getDocumentFromResultTree(ResultTreeFragment doc) {
02 String docAsStr="";
03 Document eventDoc=null;
04 try {
05 //First, convert RTF to string
06 StringWriter sw = new StringWriter();
07 DOMWriter dw = new DOMWriter(doc.getRoot(), sw);
08 dw.write();
09 dw.flush();
10 docAsStr = sw.toString();
11 //Next, convert string to a Document
12 StringReader sr = new StringReader(docAsStr);
13 XMLParser xmlParse = XMLParserFactory.newParser();
14 eventDoc = xmlParse.parse(sr);
15 }catch (Exception e) { }
16 return eventDoc;
17 }
Converting the ResultTreeFragment (RTF) to a DOM document consists of two steps. First, the RTF is converted to a string (lines 06-10) using the DOMWriter class. Second, the string is converted to a DOM Document (lines 12-14) using an XMLParser class that parses the supplied string and creates a DOM representation of the supplied XML document. The XMLParser class reads the XML representation of the data and converts all elements (tags) and the data between elements into an hierarchical object tree. The DOM API allows the developer to traverse the hierarchy of object nodes, read the contents of these object nodes, and modify the hierarchy by adding, modifying, or deleting object nodes.
Note: There is a "toString" method on the ResultTreeFragment class, but it only returns the string data between the XML tags, not the tags themselves.
Now that the source document is represented as a DOM document, you can take advantage of the DOM API to traverse the source document and extract the data you want to store in a relational database. The details of how to use the DOM API are much too vast to cover in this article. However, we will walk through the mechanics of traversing the document that was "captured" from the Event Transformation Rule stylesheet.
Refer to the "log" method source code presented at the beginning of this section. On line 04, you begin isolating the nodes you want to operate on by traversing the document down to the <input> tags. On lines 07-15, the child nodes of the input tags are iterated and dispatched to a handler routine that will process each child node according to type. The child nodes may consist of <add>, <modify> or <delete> tags.
Since we've covered a lot of territory, now is a good time to review the task at hand. You need to log object <add> and <delete> events to a relational database as well as user login events. Each time a user authenticates to eDirectory using LDAP or the Novell Client software, this results in a <modify> event on the User object for attributes such as "Last Login Time" and "Network Address" (see the example <modify> XML document above). The following "dispatch" method determines the node type and calls an appropriate handler to process the event.
01 private void dispatch(Element command) throws Exception {
02 String commandName = command.getNodeName();
03 if (commandName.equals("add")) {
04 logAdd(command);
05 } else if (commandName.equals("modify")) {
06 logModify(command);
07 } else if (commandName.equals("delete")) {
08 logDelete(command);
09 }
10 }
Notice from lines 04, 06, and 08 in the code above that a different handler is invoked based on whether the eDirectory event captured from the subscription channel is an <add>, <modify>, or <delete>. Although other events are possible, such as a <query>, all other events types are discarded.
For purposes of this application, the logAdd() and logDelete() handlers (methods) extract information about objects that are added to eDirectory to a relational database using JDBC. The following method is called by logAdd() and logDelete() to extract the desired event data and update a table in the database.
01 private void auditEvent(Element event) {
02 String eventName = event.getNodeName();
03 String dn = event.getAttribute("src-dn");
04 String timeStmpStr = event.getAttribute("timestamp");
05 timeStmpStr = timeStmpStr.substring(0, timeStmpStr.indexOf("#"));
06 System.out.println("TimeStamp: " + timeStmpStr);
07 long timeStmp;
08 java.sql.Date ts=null;
09 try {
10 try {
11 timeStmp = Long.parseLong(timeStmpStr);
12 timeStmp *= 1000; // convert to milliseconds
13 ts = new java.sql.Date(timeStmp);
14 } catch (NumberFormatException nfe) { }
15 // Create a Statement object to execute the queries on.
16 PreparedStatement ps = connection.prepareStatement("INSERT INTO
eDir_Events ( dist_name, edir_event, time_stmp )
VALUES ( ?, ?, ? )");
17 ps.setString(1, dn);
18 ps.setString(2, eventName);
19 ps.setDate(3, ts);
20 ps.executeUpdate();
21 // Close the statement.
22 ps.close();
23 }
24 catch (SQLException e) {}
25 }
Three data components are written to the database: the full distinguished name of the object (line 03), the event (line 02), add or delete, and the timestamp at which the event occurred (line 04). The timestamp value is parsed and converted to a date type supported by JDBC (lines 11- 13). A JDBC PreparedStatement object is used to write this data to the database (lines 16-22).
Again, this is a simplistic example. However, this same method could be used to extract any data from the source document and store it to the database, thus providing a fine-grained auditing system that can monitor change events on any attribute of a new, modified, or even deleted object.
The source for the logModify() method is not presented here. However, the mechanisms used to parse the distinguished name, login timestamp, and network address and write them to the database using JDBC are identical to those presented in the code above.
Conclusion
The capability to provide fine-grained auditing of business logic execution, system events, and data workflow is integral to a full-service account provisioning system. The broad extensibility provided by DirXML stylesheets and Java integration make this fine-grained auditing and reporting a reality. The scenarios presented in this AppNote represent solutions to real-world auditing scenarios and provide authentic examples for adding auditing and reporting capability to your own DirXML implementations.
How to Get Hands-On Development Help
Novell Developer Labs is available to assist developers who would like hands-on help integrating their products with technologies such as Novell eDirectory, LDAP, DirXML, Novell Portal Services, Novell Modular Authentication Services, and many more. For more information about how you can take advantage of Novell's convenient lab facilities, engineering assistance, and related resources, visit http://developer.novell.com/devlabs.
* Originally published in Novell AppNotes
Disclaimer
The origin of this information may be internal or external to Novell. While Novell makes all reasonable efforts to verify this information, Novell does not make explicit or implied claims to its validity.