Deploying an Effective Enterprise Inventory Management System Using ManageWise 2.6
Articles and Tips: article
Senior Consultant
Novell Consulting
01 Nov 1999
ManageWise has some great features for managing your hardware and software inventory. Get expert help on setting up a workable system for large enterprise networks.
Introduction
ManageWise's desktop inventory management, a subset of the desktop management package, provides for tracking of software and hardware assets. Today, companies are compelled to track their assets for such reasons as licensing compliance, asset depreciation, help desk support analysis, and auditing of software resources to keep their ISO9000 status. ManageWise provides this functionality in a scalable, efficient system of tools.
This AppNote discusses:
Inventory management issues in a global setting
Database performance
Fault tolerance
Interoperability with third-party packages
Readers of this AppNote should have some familiarity with ManageWise operations and a general understanding of enterprise system deployment strategies. This AppNote should be used as a resource for designing and deploying large enterprise inventory management systems.
Some of these deployment strategies could be used for ZENworks 2.0 inventory database deployment, but that will not be discussed here.
Inventory Management Issues
Inventory management consists of the ability to retrieve, store, and report hardware and software information for assets within an organization. This information can be as detailed as tracking a specific DLL file for all users of an application or summarizing the number of CPUs that have processor speeds in excess of 300 Mhz.
Small LAN Deployment
Traditionally, companies have deployed inventory management systems where a single master database communicates with all input resources. Figure 1 shows a typical installation for smaller networks (less than 1000 users), along with the flow of data in and out of the inventory system.
Figure 1: WAN infrastructure for traditional inventory system deployment.
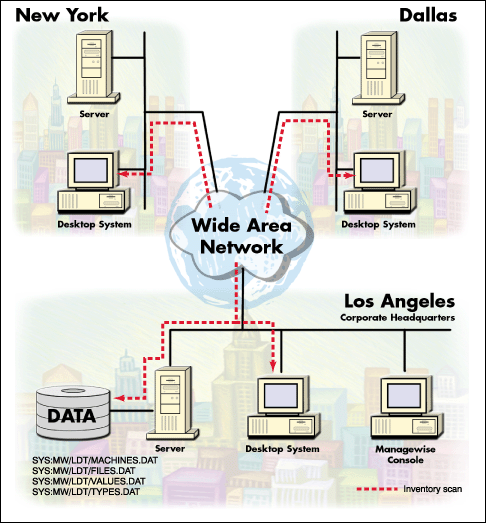
In this scenario, there is a single inventory database located centrally at headquarters. The inventory scan processing occurs across the WAN.
The advantages of this configuration are:
Suitable for small LAN environments
Can be deployed in large organizations with high-capacity WAN links
The disadvantages of this configuration are:
Limited scalability
Slow scan times
Large databases (resulting in long report processing times)
Limited fault tolerance
Here are some performance numbers typical of this configuration:
Normal (over the LAN) scan times of 30 seconds to 1 minute; could increase to 3-5 minutes depending on link speeds
Typical scan data over the WAN link averages 228 KB per machine for an initial scan
Large-Scale Deployment
An inherent problem that large organizations possess (but smaller companies do not) is how to capture this information in a consolidated manner with minimal effect on network and end-user resources. The following issues are typical concerns in a large-scale inventory environment:
WAN link utilization
End-user scan time
Database capacity and performance
Fault tolerance
Format and usefulness of collected data
The following sections of this AppNote will address these concerns in detail and will suggest different approaches for technical implementation and operational administration of the inventory management system. In addition, these scenarios will show the advantages and disadvantages of each to help design engineers customize a solution for their specific environment.
Implementation Scenarios
WAN Links
In today's enterprise networks, companies have deployed a wide array of communication links between branch office sites and the main headquarters. In some cases, these links were installed to manage a capacity of "daily user traffic" such as electronic mail, workflow applications, and minimal client-server database access. Whenever an additional application is added to the network that is outside the scope of this "daily user traffic," it is considered to be of a lower priority and hence is expected to function with little or no impact on end-user activities.
To minimize the impact of the inventory management system, you must install multiple inventory databases located strategically in the branch offices. All updates to the database occur locally, thus eliminating traffic over the WAN backbone for database interaction. It is also suggested to use a centralized server for database collection of all remote branch office databases. This will reduce reporting activity in environments where organizations have a need to report enterprise-wide information. To accomplish this, each branch office database is copied to a separate subdirectory on the centralized database server. From there it can be "merged" to the main database on the local segment.
Here is an example of the main server data structure that collects information from multiple regional databases
DATA:INV/ |&NEWYORK/MACHINE.DAT; |&LA/MACHINE.DAT; |&DALLAS/MACHINE.DAT; |&CHICAGO/MACHINE.DAT; |___CENTRALIZED/MACHINE.DAT
In the scenario depicted in Figure 2, a centralized inventory is dedicated for storage and processing of all inventory databases. The field office databases are batch-scheduled to be copied on a regular basis to the centralized server. (Just about any scheduling software can be used. Make sure copy operations are performed after hours when the impact of inventory scans on workstations is minimal.)
The operational personnel use the ManageWise LANdesk "Merge" operation to consolidate all copied databases. Operational reports are generated and distributed via ManageWise LANdesk reports or through SyncComplete, a third-party add-on that gathers data from the ManageWise alarm and topology database, NDS, multiple ManageWise inventory servers, and multiple NetWare file servers into a unified database. For more information, see:
Figure 2: Inventory deployment with distributed databases copied and merged into a centralized database.
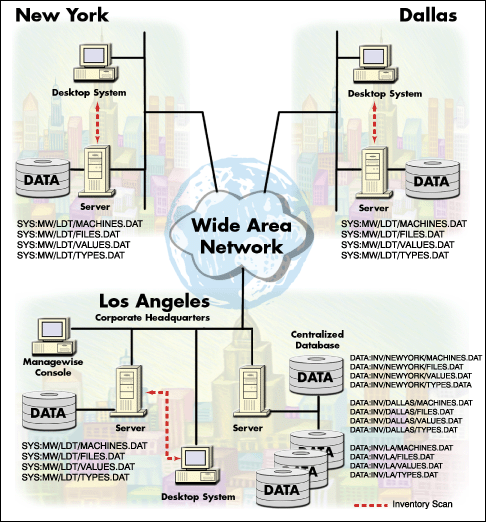
The advantages of this configuration are:
Database fault tolerance for field offices
Report processing occurs on local server/console
Reduced database size in field offices
Inventory scan processing occurs on local segments
The disadvantages of this configuration are:
Potential large copy operation over WAN links
Reports are not "real-time"
Custom reports require additional export/link to 4GL program
Consolidation or merge process requires operator intervention
Requires additional hardware for the centralized server
Here are some performance numbers typical of this scenario:
WAN sites with 1,000 to 5,000 users produce an average database size of 22 to 100 MB. Take this into account when doing copy operations over slower WAN links. As always, the number of scans retained per machine and the number of file revisions can increase the amount of data exponentially.
The time required to merge a 22 MB database over a 256 Kbps Frame Relay link with minimal line utilization averages 3 to 5 minutes.
The number of WAN links should be kept to a maximum of 10 - 20. (This number could increase if the copy operations were staggered to 2-4 per night.)
Scan Time
The location of the inventory database has a direct effect on scan time for an end-user machine because of the amount of time it takes to update the database. For instance, if you scan all the software objects on all machines on your network, the TYPES.DAT file will have to be updated with all the new component types. Traditional deployments (as depicted in Figure 1) would have had login scripts processing the scan data across the WAN, which is not really a good thing.
Obviously, if the database is located nearer to the workstation that is being scanned, there are fewer hops to cross and faster communication links are used instead of slower WAN links. Thus the interaction time between user and database is kept to a minimum. Such is the case for the deployment scenario depicted in Figure 2.
Scan times depend on the settings specified in the LDAPPL.INI file. For instance, if your intention is to retrieve all software for a given workstation, including what is not included in the LDAPPL.INI, you would set the scan mode parameter to "Mode=All". This setting is useful for organizations that have open desktops but are trying to maintain software accountability with regard to the number and versions of applications that are deployed.
Database Capacity and Performance
The four files of the inventory database are: FILES.DAT, MACHINES.DAT, TYPES.DAT, and VALUES.DAT. By default, these .DAT files are located in the SYS:MW/LDT directory, but they can be placed in a different location by using the following command line option in the MW_AUTO.NCF file:
load ldinv.nlm file=volume:path
The size of these files is determined by many settings chosen at installation time. The following is a list of variables that need to be accounted for in estimating the size of the database:
The number of machines scanned and the number of file revisions affects the size of FILES.DAT.
The number of components scanned per machine influences the size of MACHINES.DAT.
The size of TYPES.DAT is controlled by the number of component types defined and scanned.
The size of VALUES.DAT is controlled by the number of object IDs defined.
The "Mode" setting in LDAPPL.INI affects the size of FILES.DAT and TYPES.DAT dramatically.
The number of configuration files saved during scanning is set under Tools | Desktop Manager | Options | Software Scanning.
The table below will give you an idea of how much each DAT file can grow after one machine scan.
|
Filename
|
Base Size
|
Size After One Machine Scan
|
|
MACHINES.DAT |
72 KB |
148 KB |
|
TYPES.DAT |
64 KB |
104 KB |
|
VALUES.DAT |
56 KB |
168 KB |
|
FILES.DAT |
64 KB |
64 KB |
Fault Tolerance
Fault tolerance is built into the deployment strategy previously discussed in that databases are deployed locally, but an additional copy is stored on the centralized database at headquarters. Besides the normal disaster recovery options such as backups and hardware RAID systems, the engineer could recover from database corruption by copying the database back to the branch office.
Data Structure and Interoperability
Unless you are a seasoned programmer versed in the APIs to the Btrieve database that ManageWise uses, you will probably want to export data from the inventory database to a fourth-generation language (4GL) program such as Microsoft Access, or to a spreadsheet application such as Microsoft Excel. Figure 3 identifies the field layouts that can be imported from the comma-separated values (CSV) file through the Desktop Manager's "Print Inventory Data" feature. Notice that only components selected will be exported to the CSV file.
Figure 3: Selecting component types from the "Print Inventory Data" option.
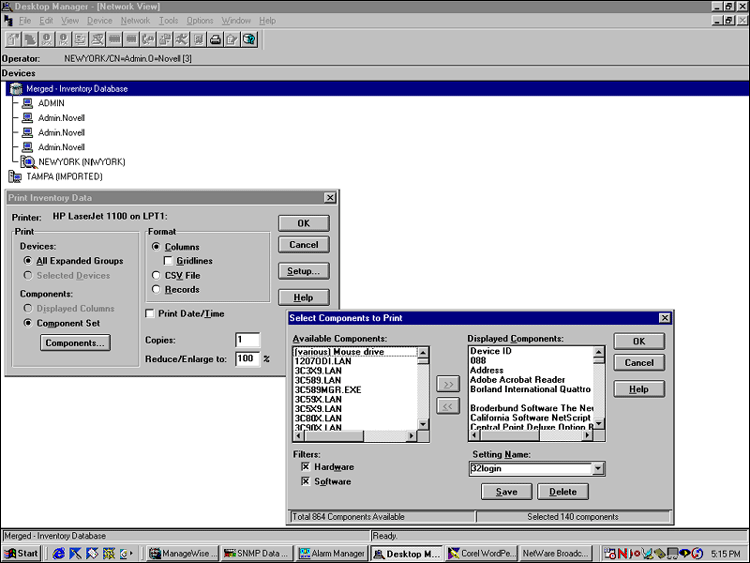
Linking the ManageWise Database to Other Programs
If you would like to expand on or create new comprehensive reports that are not included in the report features of "SynComplete", you may want to try using Microsoft Access to link the Btrieve databases via an ODBC driver from Pervasive Software. These drivers are located at:
http://www.pervasive.com/products/download/
Download the ODBC driver and the workstation software. The ODBC driver is free. The workstation software is a trial version that can be converted to full license for $49.00 per workstation. If you already have Btrieve for Windows 95/98/NT version 6.15, download only the ODBC driver version 2.04. This provides the ability to merge those branch office databases in real time.
Note: It is advisable to use a separate console station besides your ManageWise console because the Pervasive workstation software can conflict with the Btrieve files of the ManageWise console. Also, support from Pervasive Software is good as long as you are using one of their products (not just the ODBC driver). It is advisable to have in-depth knowledge of Btrieve file format, definitions and SQL before attempting the deployment.
Figure 4 illustrates a linked database deployment strategy. In this scenario, distributed inventory databases are located in each field office. A Microsoft Access database is set up with ODBC links to all Btrieve databases (any ODBC-compliant database can be used). The reports are then customized through Access.
Figure 4: Database deployment strategy with a 4GL program.
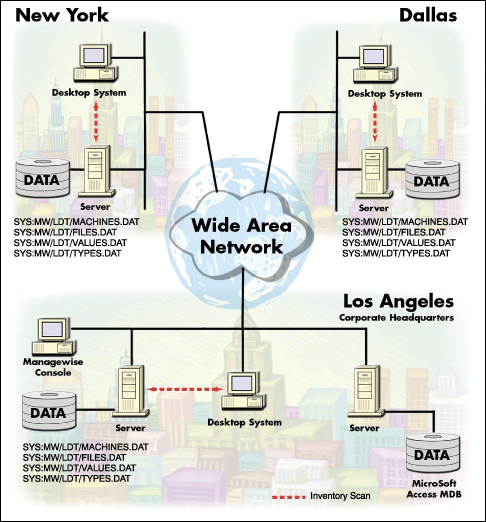
The advantages of this configuration are:
Centralized "real-time" custom reporting
No operational procedures for nightly copy/merge operations
Reduced size of databases in field offices
Inventory scan processing occurs on local segments
The disadvantages of this configuration are:
Report processing occurs over WAN links
Requires 4GL experience in creating reports and maintaining database links
Requires additional hardware for the centralized server
Requires optional DataBase Administrator to administer SQL, Oracle, or other SQL-based database
Here are some typical performance numbers for this scenario:
Fine tuning of SQL/ODBC parameters such as QueryTime=. The default is 60; increase in increments of 10 for large WAN environments or slow WAN links. Using the Registry Editor, change the following DWORD value to the desired setting:
HKEY_LOCAL_MACHINE_\Software\Microsoft\Jet\4.0\Engines\ODBC
Scales to 1000 - 5000 machines per WAN site
Allows a virtually unlimited number of WAN links
In this database model, your design has the option of leaving the databases remotely at the branch offices and linking or importing the Btrieve databases with Microsoft Access. Obviously, creating a link over slow WAN lines may cause ODBC timeouts and may be too slow for large production reports. In these cases, it may be necessary to import the data from the Btrieve database directly into Access. In large enterprise environments, notice should be taken of the size of the MDB file. The design engineer may decide to create multiple MDB files for reporting needs.
Note: For another approach to complex reports, see the AppNote entitled "Using Seagate's Crystal Reports 6.0 with ManageWise Inventory Database" in the May 1999 issue.
Figure 5 shows the relationships between the four Btrieve files when linked/imported to Microsoft Access. This relationship could be expanded to link in regions of data using the same model.
Figure 5: Inventory relationships defined in Microsoft Access.
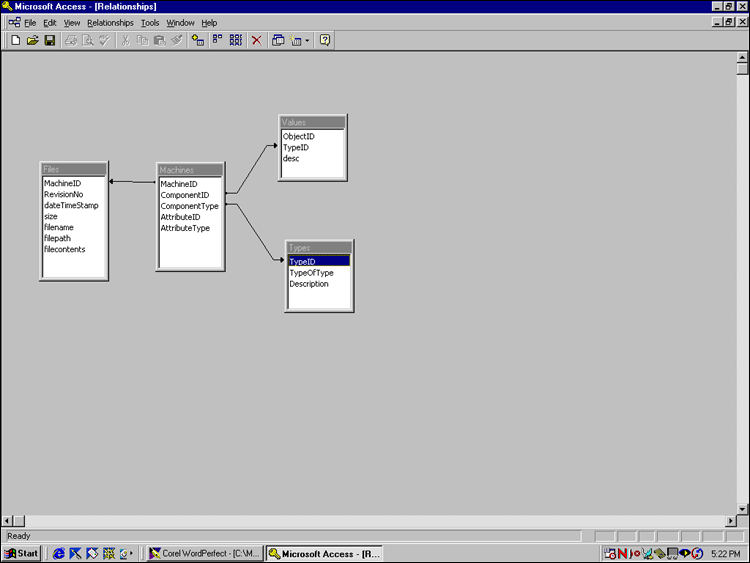
The tables below show the data definition files (DDFs) used to link the inventory files with Microsoft Access. Note that these DDFs are different in that the variable length record of FILES.DAT was ajdusted to work in an Access memo field with a size of 32,608 bytes.
FILES.DAT
|
Field
|
Type
|
Offset
|
Length
|
|
machineID |
integer |
0 |
4 |
|
revisionNo |
unsigned |
4 |
4 |
|
dateTimeStamp |
integer |
8 |
4 |
|
size |
unsigned |
12 |
4 |
|
fileName |
zstring |
16 |
13 |
|
filePath |
zstring |
29 |
128 |
|
fileContents |
note |
157 |
32608 |
|
Index #
|
Name
|
Case
|
Dup
|
Mod
|
Null
|
Sort
|
|
0 |
machineID |
N/A |
No |
No |
No |
Ascend |
|
0 |
fileName |
Yes |
No |
No |
No |
Ascend |
|
0 |
filePath |
Yes |
No |
No |
No |
Ascend |
|
0 |
revisionNo |
N/A |
No |
No |
No |
Ascend |
MACHINES.DAT
|
Field
|
Type
|
Offset
|
Length
|
|
machineID |
integer |
0 |
4 |
|
componentID |
integer |
4 |
4 |
|
componentType |
integer |
8 |
4 |
|
attributeID |
integer |
12 |
4 |
|
attributeType |
integer |
16 |
4 |
|
Index #
|
Name
|
Case
|
Dup
|
Mod
|
Null
|
Sort
|
|
0 |
machineID |
N/A |
Yes |
Yes |
No |
Ascend |
|
1 |
machineID |
N/A |
Yes |
Yes |
No |
Ascend |
|
1 |
componentID |
N/A |
Yes |
Yes |
No |
Ascend |
|
2 |
machineID |
N/A |
Yes |
Yes |
No |
Ascend |
|
2 |
attributeType |
N/A |
Yes |
Yes |
No |
Ascend |
|
3 |
machineID |
N/A |
No |
Yes |
No |
Ascend |
|
3 |
componentID |
N/A |
No |
Yes |
No |
Ascend |
|
3 |
attributeID |
N/A |
No |
Yes |
No |
Ascend |
|
4 |
attributeID |
N/A |
Yes |
Yes |
No |
Ascend |
|
5 |
machineID |
N/A |
Yes |
Yes |
No |
Ascend |
|
5 |
componentType |
N/A |
Yes |
Yes |
No |
Ascend |
VALUES.DAT
|
Field
|
Type
|
Offset
|
Length
|
|
objectID |
autoinc |
0 |
4 |
|
typeID |
integer |
4 |
4 |
|
desc |
zstring |
8 |
80 |
|
Index #
|
Name
|
Case
|
Dup
|
Mod
|
Null
|
Sort
|
|
0 |
objectID |
N/A |
No |
No |
No |
Ascend |
|
1 |
typeID |
N/A |
Yes |
Yes |
No |
Ascend |
|
2 |
desc |
Yes |
Yes |
Yes |
No |
Ascend |
TYPES.DAT
|
Field
|
Type
|
Offset
|
Length
|
|
TypeID |
autoinc |
0 |
4 |
|
TypeOfType |
unsigned |
4 |
4 |
|
Description |
zstring |
8 |
40 |
|
Index #
|
Name
|
Case
|
Dup
|
Mod
|
Null
|
Sort
|
|
0 |
TypeID |
N/A |
No |
No |
No |
Ascend |
|
1 |
Description |
Yes |
No |
Yes |
No |
Ascend |
Conclusion
The examples presented in this AppNote have attempted to demonstrate a different approach to inventory management. In the earlier versions of ManageWise, there was a tendency to think centralized or LAN specific. In fact, ManageWise was originally designed to be a LAN management tool. With later versions such as 2.6 and K2, the components have been enhanced to allow for decentralization. New design strategies are needed to address today's growing enterprise environments. We must find new approaches and be innovative in how we deploy network management tools.
Additional Resources
For additional information, refer to these resources:
ManageWise product Web site (http://www.novell.com/managewise)
TID 2916072 "Implementing Managewise on a Large NDS Tree" at http://support.novell.com
Pervasive Software Web site (http://www.pervasive.com)
Pervasive Software download page (http://www.pervasive.com/products/download/)
White Paper "Adding Relational Capabilities to Btrieve Environments" at http://www.pervasive.com/support/technical/white/w_ssql1.html
Microsoft Access information athttp://www.microsoft.com
Intel LANdesk software information at http://www.intel.com/support/landesk/mgtsuite/25x/software.htm
* Originally published in Novell AppNotes
Disclaimer
The origin of this information may be internal or external to Novell. While Novell makes all reasonable efforts to verify this information, Novell does not make explicit or implied claims to its validity.