Managing the Physical Network: A Beginner's Guide
Articles and Tips: article
President, LAN Utilities, L.L.C.
Pleasant Grove, UT
01 Jan 1997
Introduces the topic of physical network management and discusses some methods and tools for troubleshooting problems with cabling, network cards, and connection devices.
- Introduction
- The Importance of Physical Network Management
- Three Example Troubleshooting Scenarios
- Tips for Stress-Testing the Physical Network
- Act, Don't React
Introduction
The emergence of sophisticated network management systems over the last several years has enabled better network troubleshooting. However, traditional network management systems concentrate on higher level network problems; they do not generally deal closely with the actual physical network of cabling, cards, and physical connections that underlie the network. When problems do occur in the physical network, most system administrators using traditional network management software are informed only that the physical network is not working. New and easy methods to detect, anticipate, and repair problems in the physical network will go a long way toward improving physical network management.
This is the first in a series of AppNotes on physical network management, also known as cable or cable plant management. This introductory AppNote discusses:
What physical network management is and why it is important
How the physical network functions and how it fails
Methods and tools for managing the physical network
Tips for troubleshooting the physical network using an engineered diagnostic approach
Future AppNotes in this series will cover topics such as installing, optimizing, maintaining, and debugging the physical network.
The Importance of Physical Network Management
As more and more organizations depend on fully operational LANs for their critical business processes, an unseen and seldom-considered aspect of the network becomes increasingly important: the "physical" network consisting of cabling, network interface cards, connectors, hubs, and other hardware. According to a December 1993 report from McGraw-Hill's Datapro unit, more than half of all network outages are attributed to problems at the physical level. In light of such statistics, it makes sense to look at physical network management in addition to traditional network management.
Even in installations that show a reduction in the number of failures from year to year, the rapid rise in the cost of each failure far outruns the reduction in failures. And as LAN dependency and usage grows, existing LAN equipment is subjected to increasingly greater stress. These issues combine to create a current problem that almost all network administrators face: more users and more traffic creating the need to frequently upgrade and improve the LAN and its bandwidth.
Traditional vs. Physical Network Management
To understand how physical network management differs from traditional network management, picture a typical manufacturing operation. The president of the company sits in an office away from the production floor and learns about problems only after they have been filtered through the management chain of command. However, the president suspects that there might be some trouble brewing that his managers are shielding him from. So the president stations one of his assistants out on the production floor to alert him directly of any potential problems. Both methods of informing the president are vital to the smooth operation of the company; using one without the other can lead to difficulties.
Traditional network management software is like the chain-of-command method of reporting problems. These products don't alert the system administrator to failures in the physical level of a network until the failures have been passed up through the network software to the network management software. Management software based on Simple Network Management Protocol (SNMP) resides on top of the actual network communication software (for example, NetWare). The management software is shielded from individual network failures by the underlying network communication software's built-in resilience to physical failures on the network.
By contrast, physical network management software resides at the same level as the networking software (at the level of the client, protocol stack, and LAN drivers). This software tests the health of the physical network and communicates failures directly to the system administrator. Like the assistant on the production floor, physical network management software bypasses the chain of command-the network and network management software-that filters failures up through the network to the system administrator.
How Network Failures Occur
Networks rarely go down as the result of some catastrophic failure, such as Hooch Magruder and his perilous backhoe slicing through the underground cabling between two buildings. Far more commonly, physical network failures are caused by malfunctioning parts and faulty physical connections. What most network administrators don't realize is that these common reasons for failures aren't micro-catastrophes either-they don't happen all of a sudden. Most of the time, the network fails little by little, day by day, until it fails completely and causes a major problem.
The Failure Threshold. As described in the previous section, current network management software is designed to track failures. But most network software is designed to hide physical failures from users as much as possible. For example, rather than bombarding users with error messages every time there is a problem sending a packet of data, the network software performs a number of retries automatically, without bothering users. Thus failures are ignored until they exceed a certain threshold. Generally, it takes 15 back-to-back physical failures for network management software to be alerted to a failure at the physical level (see Figure 1).
Figure 1: For traditional network management software, the threshold of 15 back-to-back failures is the baseline for detecting failures.
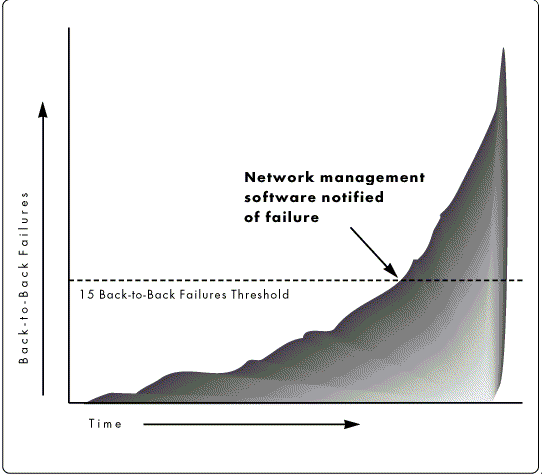
This tolerance to physical faults is good for users, who generally don't care what the network software does as long as the network keeps running, even if it means that the network can't handle as large a workload. However, the network's built-in fault tolerance can hide developing problems from the administrator. In NetWare, for example, administrators only become aware of physical failures when either of two conditions exist:
15 failures occur back-to-back and the network management software notifies the system administrator
The failure becomes fatal and the network "crashes"
Naturally, administrators want to keep the network up and running as much as users do. But they also need to know when failures occur so they can fix them before they become catastrophic.
The Ebb and Flow of Network Traffic. Another danger in ignoring physical failures has to do with the normal "ebb and flow" nature of network traffic. Typically, the traffic or load pattern on a network over time manifests peaks and valleys: at some points the network load tends to be low, then gradually rises to a peak, only to drop back to the lower point and eventually rise again (see Figure 2).
Figure 2: When plotted over time, network usage typically exhibits peaks and valleys of high and low use.
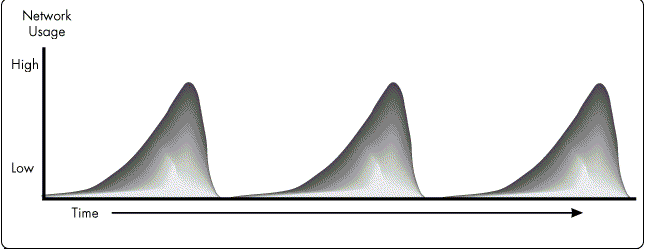
Peaks are generally created by end-of-the-month and end-of-the-quarter activity, when the network is being used more heavily. As the load on the network increases, the number of failures tends to rise as well. A flaky connection that nearly reaches 15 failures during low usage periods would fail catastrophically during usage peaks-the most mission-critical time for a network. For example, during month end when the accounting department is closing out the books, the load on the network increases dramatically, increasing the probability of a failure since more stress is being put on the physical network.
To put it another way, your LAN is more likely to fail when your company needs it the most, not the least. Without adequate management of the physical network and early warning systems for physical failures, administrators will have a difficult time keeping the network up, especially during critical peak usage periods.
The Need for Effective Tools
Because traditional network management and networking software isn't designed to inform administrators of developing problems on a failure-by-failure basis, there is no way to find out when and where problems start to develop. The current method for dealing with physical problems-waiting until they violently manifest themselves-is similar to driving a car without the warning lights and noises that alert you to a developing problem. Without these warning devices, you would keep driving the car until it completely breaks down. Only then would you know that there is a problem and seek a mechanic to fix it.
What administrators need is a way to find out about problems while they are still smoldering, before they become full-fledged fires. To do this, however, administrators need a tool to help them effectively test the condition of the physical network. Let's look at what such a tool should be able to do.
The Stress Test. Since network failures are more likely to occur during periods of peak usage, it would be helpful to be able to "stress test" the network by subjecting it to brief bursts of high load. During these micro-bursts, the physical network will be stressed to the point of failure; when the stress is removed, the network will recover. By tracking these failures, you can better predict where the physical network might fail under a more sustaned high load.
For a micro-burst test to be effective, it should stress every component of your physical network: network cards, cables, connectors, hubs, MAUs, and so on. To do this, the test should traverse every LAN segment, be transmitted and received by every network interface card, and reach every cable, connector, and hub on your network. However, the micro-burst test should be short enough that it will not impact network users or endanger the physical network.
|
New Media, More Problems? The migration to wireless andhigher speed media impacts the physical network. Both have greaterprobability of failure than current media. This is especiallytrue of wireless media, which depends on transmission across airwaves.As more networks go wireless, problems with dropouts and interferenceincrease and lost packets become a real problem. Thus the wirelessphysical LAN has the potential to fail more often than a wiredmedia LAN. With high-speed media, data is transmitted onto thewire more quickly. This increases the stress on the cabling andphysical equipment, leading to more possibility for failures.The bottom line is that as the nature of the physical networkand the demands placed on it change, it becomes increasingly importantthat the integrity of physical network remain sound. |
What Kind of Tool? Having a method for effectively testing the physical network is important, but it only solves half of the problem. The other half is, what kind of tool can implement this method? How do you put those micro-bursts of stress on the network?
Both hardware and software tools exist for monitoring the physical network. Hardware tools consist of physical devices such as cable meters. Using time-domain reflectometry (TDR), cable meters can determine the exact point in a cable segment where a break has occurred. However, you must physically connect the meter to the network segment.
Software tools, on the other hand, can be used to remotely determine where that faulty segment is without requiring you to physically visit and connect to each segment you want to test. Software also provides unattended testing of your network. For example, software can be set to run every night (at 2:00 a.m., for instance) and log the results for you to look at later. Another advantage is that one software tool can analyze a number of different media types-a job that would require several different cable meters. And only software tools can detect problems on a wireless LAN (see the box "New Media, More Problems?").
The choice between hardware and software tools is not mutually exclusive. In many cases, software tools can be used to complement hardware devices. For example, administrators generally don't care where a cable segment is broken; they only want to know which cable is broken so they can remove and replace it. But in large cable plants with lots of wire runs in the walls, using a cable meter in conjunction with software makes sense.
In short, an effective software troubleshooting solution for the physical network should automate periodic stress tests of the physical network, predict probable points of future failure on the network, and report on problem areas. One example of such a tool is LANengineer, a software-based physical network management tool that allows you to test the physical network by putting brief bursts of high load on the network. LANengineer will impact network performance no more than one to two percent and will not endanger the physical network. In fact, the high-load burst is short enough that, even if one user's packet is dropped as a result of the test, the networking software would immediately retry the packet and succeed. This method of testing allows the administrator to pinpoint and resolve problem areas without affecting the users.
Three Example Troubleshooting Scenarios
The following three scenarios illustrate how I have used LANengineer, a physical network management software solution, to identify immediate failures and detect potential problems at the physical level.
Detecting Network Performance Bottlenecks
The Novell network in one of our labs seemed to run slowly at times. This was puzzling, since the server was not under any load and NetWare was reporting no problems. To find out if something was wrong at the physical level, I stress-tested the cabling with LANengineer. The software reported a problem with a particular 10BaseT cable segment. I repeatedly tested the cable segment, wiggling the wire and watching to see what the software said. When I wiggled the wire at one of the connectors, the cable would repeatedly fail completely and then recover. I pulled out the connector, recrimped it, and tested it again. This time the cable tested without errors, and the network resumed running at normal speed.
The reason NetWare reported no errors is because, by default, it needs 15 back-to-back failures before it reports a problem. A network can easily drop 9 out of 10 packets and never exceed the 15 packet threshold. As long as the client's requests to the server get through within the first 15 tries, NetWare doesn't report a problem. However, all of those retries have an effect on performance. Without LANengineer's ability to test the physical network, this problem may have gone undetected for some time and would have continued to dramatically impair the LAN's performance.
Troubleshooting Lost Network Connections
In another situation, a company using NetWare had been wired with poor quality wire and connectors. The users complained of two major problems. First, their network drives would be grayed out and unusable several times during the day (meaning that the workstations were losing their connection with the server). To get around this, the users were rebooting their workstations throughout the day to regain the network connection. Second, the network sometimes ran slowly for no apparent reason. This was unusual, given that the network had only five users and the server was never very busy.
To find out what was wrong, I stress-tested the network cable with LANengineer. The software reported a large number of collisions that were causing packets to be dropped all over the network. Even when the network was idle, a single workstation trying to communicate would experience numerous collisions. It turned out that the network was acting like an echo chamber: a workstation would send a packet, hear a reflection of its own packet, and assume that the reflection was another workstation sending at the same time. Following the normal Ethernet CSMA/CD process, the workstation would first send a jamming signal on the network so no one else could talk, and then back off for a random amount of time before it resent the packet. Stations did this constantly.
Users were losing their network connection because the server and workstation couldn't communicate with each other due to lost packets. When a file server doesn't sense activity from a workstation for 15 minutes, it sends out a watchdog packet that basically says, "Hey, workstation, are you still alive?" The workstation should respond with a packet that says, "Yes, I am alive." This happens in the background, transparent to the user.
On this network, after a workstation was inactive for 15 minutes, the server would send out a watchdog packet, and either the watchdog packet would be lost before arriving at the workstation, or the response from the workstation would be lost before making it back to the server. In either case, because the workstation didn't answer the watchdog packet, the server decided that the workstation was no longer functioning and would disconnect from the workstation (also known as "tearing down the connection"). The workstation, however, was unaware that its connection had been terminated until the next time the user tried to access the server, at which point the workstation displayed a network error message. Since the users were running Windows, losing the connection caused the network drive icons to be grayed out and unusable.
LANengineer indicated that a particular cable segment was causing problems on the network. Once I replaced the segment and fixed a broken T-connector, the workstations no longer lost their connections with the server, but kept their network drive mappings for days on end. Even better, the network started running at a normal speed-over 10 times fasters than its users had ever seen it run. Since this problem had existed since the day the network was installed, users had no idea how fast the network could be.
Predicting Physical Network Failure
Besides pinpointing existing problems, physical network management can provide early warning of potential failures. One network administrator claimed that his network was running just fine, but LANengineer identified a problem on a particular segment. He found this hard to believe since the network software ran just fine; he assumed that the physical network management software was broken instead. Further tests on the segment using LANengineer pointed to the network interface card. Since the network software still wasn't reporting problems, the administrator finally called about LANengineer. While we were talking on the phone, the network interface card failed completely. LANengineer had tested and predicted a failure at this network card a week before the failure actually occurred. After the administrator replaced the card, he retested the physical network and LANengineer reported no additional problems.
Tips for Stress-Testing the Physical Network
One of the goals of physical network testing is to test the network on a regular basis. Testing the network at least several times a week is a reasonable expectation. Although you could test an active network with little or no impact on users, testing the physical network on an idle or near-idle network can provide information on subtle changes in physical network performance. Remember, knowing where problems are likely to occur before they actually happen enables proactive network maintenance. The advantages of testing an idle network make testing the network at night desirable. It follows that the best testing method would be one in which testing could be accomplished in a single night. Assuming that nightly backups are taking place, on the average a window of about 10 hours each night is available for physical network testing.
Another goal of physical network testing is for the administrator to visit as few locations as possible to obtain the results of the testing. Running all over the network each morning to see what happened during the previous night's testing is time-consuming and inefficient. Using one computer to oversee the testing and collect the results would simplify this task.
One additional goal is to keep the test report to a manageable size. Can you imagine wading through a report that showed the results of the 4,950 tests it would take to test a 100-node network?
Testing in Domains
At first glance, it would seem that the best way to accomplish physical network testing would be to have every node on the network test itself with every other node on the network. This would ensure that every node could communicate with every other node without problems. While this exhaustive testing is the most thorough method possible, the practice runs into problems when performed on a network of any significant size.
The maximum number of tests you would need to perform is derived from the formula
n * (n - 1) / 2
where n equals the number of nodes on the network. For example, on a network with 10 nodes, testing every node with every other would take 45 tests. If each test takes a maximum of 10 seconds, it would take, at most, 7.5 minutes to complete the tests. On a 100-node network, testing every node with every other would require 4,950 tests. At 10 seconds maximum for each test, total testing would take at most 13.75 hours. On a 1,000-node network, testing every node with every other node would require 499,500 tests, taking at most 57 days 19.5 hours to complete.
|
Numberof Nodes
|
Numberof Tests
|
Time (at10 Sec/Test)
|
|
10 |
45 |
7.5 minutes |
|
100 |
4,950 |
13 hours 45 minutes |
|
1000 |
499,500 |
57 days 19 hours 30 minutes |
As you can see, as the number of nodes on the network goes up, the number of tests-and hence the maximum total time required to complete the testing- increases exponentially (see Figure 3).
Figure 3: If you test every node with every other node, the time to test increases exponentially.
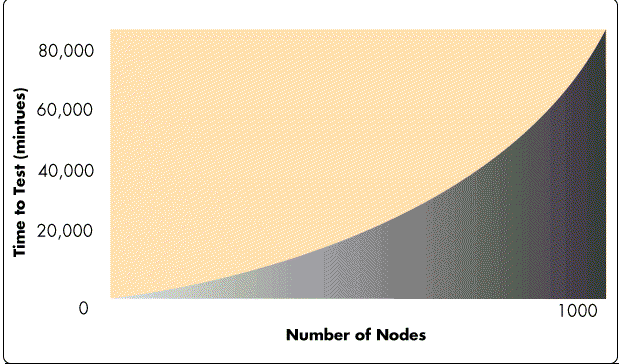
In light of the goals described above, having every node test every other on a network of any appreciable size is not a viable option. It requires too much time to be feasible.
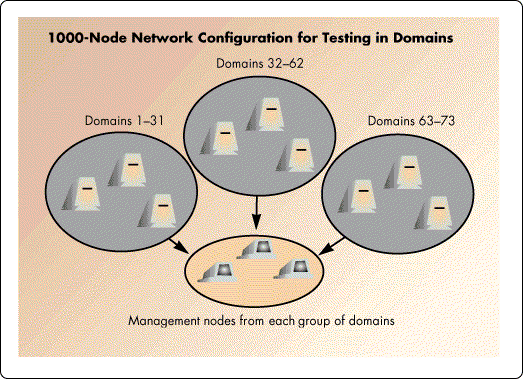
A better method for testing the physical network is to group your network into 15-node groups, or domains (not to be confused with a NOS "domain" architecture). To simplify the collection of test results, you should include a management node for collecting all test information in every domain. Thus, each domain would consist of 14 nodes specific to that domain and one management node (see Figure 4).
Figure 4: The recommended "domain" for physical network testing consists of 14 nodes plus one management node for collecting the test results.

To illustrate the advantages of testing your network in domains rather than with every node against every other node, consider the following scenario. In a 15-node domain it takes 105 tests for each node to test itself with every other node, requiring at most 17.5 minutes to complete. Using this method to test a 99-node network would take 4,851 tests and require at most 13.475 hours to complete. Using the domain method, you can reduce the testing time for a 99-node network to a maximum of two hours. Here's how it works.
First, you divide the network into 7 domains (99 - 1 / 14), each consisting of 14 unique nodes and one management node (see Figure 5).
Figure 5: A 99-node network can be divided into 7 test domains to reduce physical network testing time.

Because the single management node is included in every domain, it makes sense that, if every node can talk to the other nodes in their domain and if all the nodes in each domain can talk to the management node, then all nodes should be able to talk to each other. Within each domain, each node is tested against every other node, taking 105 tests and 17.5 minutes to complete. Since you're using the same management node to collect test data on each domain, you have to test the domains one after the other. That adds up to 105 tests times 7 domains, for a total of 735 tests and 17.5 minutes times 7, or 122.5 minutes (approximately two hours) to complete the testing.
Compared with the 13.475 hours it would have taken to test every node with every other node on this network, using the domain method saves a considerable amount of time. In addition, one computer gathered all the test results, and the number of tests dropped from 4,851 to 735, cutting down on the length of the test report.
Using Multiple Management Nodes
A single management node can oversee the testing of 435 nodes (31 domains) in 9.0 hours, allowing you to test the entire network in one night (see Figure 6).
Figure 6: On a 435-node network divided into 31 domains, it would take 9.0 hours to test the entire network.

If you have more than 435 nodes on your network, you can still test the network in one night by designating additional management nodes to oversee the testing of other groups of 435 nodes. Testing in domains using multiple management nodes substantially reduces the time it takes to test increasingly large networks, as illustrated in the following chart:
|
Number of Nodes
|
Number of Tests
|
Time(at 10 Sec/Test)
|
Number of Mgmt Nodes
|
|
15 |
105 |
17.5 minutes |
1 |
|
99 |
735 |
2.0 hours |
1 |
|
435 |
3255 |
9.0 hours |
1 |
|
870 |
6511 |
9.0 hours |
2 |
|
1305 |
9768 |
9.1 hours |
3 |
This scheme allows for concurrent testing: two groups of 435 nodes using two management nodes to oversee the testing would take 6,511 tests and only 9 hours to complete (see Figure 7).
Figure 7: Testing in domains: number of nodes vs. time to test.
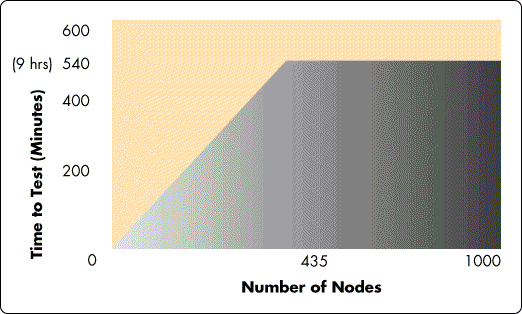
To ensure that both groups of 435 nodes can talk to each other, the two management nodes would test communications with each other. If both can talk to each other, it follows that all nodes in one group should be able to talk with all nodes in the other group (see Figure 8).
Figure 8: To test a 1000-node network using domains, the network is divided into 435-node groups (31 domains per group maximum) with one management node per group. After concurrent testing within each group, the management nodes test with each other. The entire process takes 9.1 hours.
Using this method, a network of 1000 nodes can be tested using three nodes to oversee the tests in 9.1 hours instead of 57 days 19.5 hours (only 1/29th the time). This method of testing is nearly as thorough as every node testing with every other node, but can be done in a much more reasonable amount of time (see Figure 9).
Figure 9: Number of nodes vs. time to test for testing with and without domains.
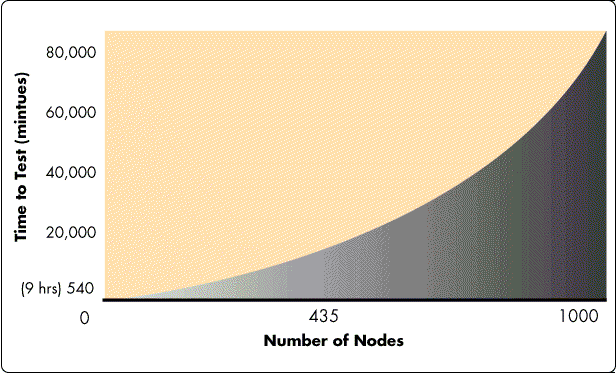
As you can see, testing with domains substantially reduces the exponential curve that testing every node with every other node creates.
Implementing Your Test Domains
You can group nodes into domains by department, by location, or by nodes most likely to communicate with each other. For example, if you have a 75-node WAN, with 30 nodes in one location and 45 in another, and your primary goal is to minimize WAN traffic involved with testing the network, you could divide the 30-node location into two domains with one management node and the 45-node location into three domains with one management node. Thus, only two nodes must test each other over the WAN link, reducing WAN traffic but ensuring network integrity.
Act, Don't React
Managing the physical part of your network will allow you to act proactively on potential problems rather than having to react to major catastrophes. This AppNote has introduced you to physical network management and shown you how software-based tools can be used to proactively test a network at periodic intervals to predict probable points of future failure. Stress-testing the network every night (in domains on larger networks) provides a report on the status of the physical network each morning. By identifying potential problem areas on the network before they become serious, you can schedule repairs when it is convenient for both you and your users.
For more information about LANengineer, visit the Web site at:
http://www.lanengineer.com
or contact:
L'Image Enterprises, L.L.C. 17853 Santiago Blvd. #107-342 Villa Park, CA 92667 714-637-6577 800-720-5557 714-637-7557 fax
* Originally published in Novell AppNotes
Disclaimer
The origin of this information may be internal or external to Novell. While Novell makes all reasonable efforts to verify this information, Novell does not make explicit or implied claims to its validity.